

[算法简结]递归分治(一):起
一年幸福的大学时光又快结束了,到年底也是时候总结了。这个学期开了算法分析课,教程是王晓东的《计算机算法设计与分析》,正好也拿出来总结一下。我开的这个系列内容就是简单地总结这5个月所学算法思想。为了加强自己的动手能力又用java实现了一遍,总共会涉及递归分治、动态规划、贪心算法、回溯法、分支限界法、随机化算法这些方面(内容简单吧,所以叫简结=w=)。
一.递归分治
1.基本思想
递归(Recursion)
定义为直接或间接地调用自身的算法称为递归算法。举几个例子,一个就是我们小时候都遇到过的“老和尚给小和尚讲故事”,另一个就是周杰伦那张叶惠美的专辑封面了,看墙上那幅画里面与整张封面内容相同。这些都是递归的表现形式,希望帮助理解。
 然而只要能用递归的问题都可以转换为迭代(Iteration),两者的区别就是代码简洁与内存消耗的考量。递归中重复的调用开销很大,将占用很长的处理器时间和大量的内存空间。递归算法以此代价换来复杂算法理解上的容易、代码量的减少,并且也不容易出错。虽然说我们在操作上可以逢递归就消解成迭代,不过不惜一切代价躲避递归的想法是错误的。因为对于某些递归过程中递归调用语句后还有递归调用语句(消解时,无可避免要用栈来存储),迭代算法并没有提高程序运行的速度,反而会使程序变得复杂难懂。比如汉诺塔中的两处递归调用。
然而只要能用递归的问题都可以转换为迭代(Iteration),两者的区别就是代码简洁与内存消耗的考量。递归中重复的调用开销很大,将占用很长的处理器时间和大量的内存空间。递归算法以此代价换来复杂算法理解上的容易、代码量的减少,并且也不容易出错。虽然说我们在操作上可以逢递归就消解成迭代,不过不惜一切代价躲避递归的想法是错误的。因为对于某些递归过程中递归调用语句后还有递归调用语句(消解时,无可避免要用栈来存储),迭代算法并没有提高程序运行的速度,反而会使程序变得复杂难懂。比如汉诺塔中的两处递归调用。
我们再来讲讲递归的代价吧,在教材中我们一开始就举出了Fibonacci数列的递归式,其实这种递归的算法很浪费。因为Fibonacci数不就是前两项是0、1,以后的每项都是前面两项的和。前面的递归法只是低效地把本不是递归的事实抽象成递归的定义进而用递归算法得解。即颠倒了原式的定义也浪费了内存空间。所以求Fibonacci数要写也得写“保存前两项,然后相加得到结果”的迭代解法。不是吗?

比萨的Fibonacci
分治(Divide)
将原问题分割成规模较小而结构与原问题相似子问题,递归地解决这些子问题,然后再合并其结果,这就是分治的策略。所以说,分治与递归狼狈为奸。
2.实例
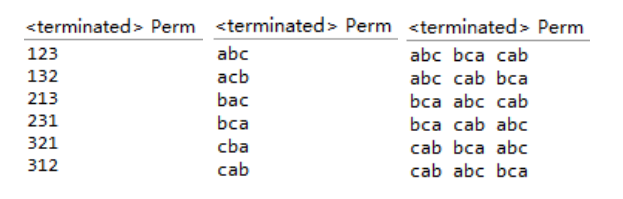
排列问题(这个算法以后使用的次数很多)
设R={r1,r2,...,rn}是要进行排列的n个元素,Ri=R-{ri}。方法Perm(x)为元素的全排列。(ri)Perm(x)为每个全排列前面加上一个ri。
所以得递归式:
当n=1时,Perm(R)=(r)
当n>1时,Perm(R)由(r1)Perm(R1),(r2)Perm(R2),...,(rn)Perm(Rn)构成。
算法的关键就是在每一层递归中都要把每一个元素ri放第一个位置再求下一层Perm(Ri),所以要用到交换,因为java中没有指针的概念,所以特实现swap方法如下

 Swap
Swap

1 static <T> void Swap(T list[],int i, int j) 2 { 3 T tmp = list[i]; 4 list[i] = list[j]; 5 list[j] = tmp; 6 }
核心算法实现如下
Perm
1 static <T> void Perm(T list[], int k, int m) 2 { 3 if(k == m) 4 { 5 for(int i = 0; i <= m; i++) 6 System.out.print(list[i]); 7 System.out.println(); 8 } 9 else 10 for(int i = k; i <= m; i++) 11 { 12 Swap(list, k, i); 13 Perm(list, k + 1, m); 14 Swap(list, k, i); 15 } 16 }
这样我用到了java中的泛型,这样不仅可以比较整型,还可以比较字符型、字符串型。
今天就先讲这么多,主要就是把这个系列的模式定下来,好的开始时成功的一半嘛。给自己加油↖(^ω^)↗

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步