Word2Vec在Tensorflow上的版本以及与Gensim之间的运行对比
接昨天的博客,这篇随笔将会对本人运行Word2Vec算法时在Gensim以及Tensorflow的不同版本下的运行结果对比。在运行中,参数的调节以及迭代的决定本人并没有很好的经验,所以希望在展出运行的参数以及结果的同时大家可以批评指正,多谢大家的支持!
对比背景:
对比实验所运用的corpus全部都是可免费下载的text8.txt。下载点这里。在训练时,word embedding的维度被调节为200,除了word2vec_basic.py版本的step size为600001外,其余均为15个epoches。 运行结果除basic版本外其他的均运用了Mikolov所公开的questions-words.txt文件来计算其精确度。该精确度计算文件的格式为每行四个词,在计算精度时,系统选取前三个词的向量,计算词2-词1+词3所得的向量并通过cosine similarity的方式搜寻最接近的词,并选取top N个(N为自定义量,一般要么1要么4)来查看questions-words里每行的第四个词是否存在于这top N个词之中。另外,在运行结束后,我也根据Mikolov论文中的提示运用了几个常见的向量算数测试来测验各模型的准确度。我所运用的测试为:
1. France, Paris, Beijing, China 或者 France, Paris, Rome, Greece
2. man, king, woman, queen
3. slow, slowly, quick, quickly
等等......
对比结果:
TensorFlow框架:
word2vec_baisc.py是Tensorflow官方版本的Sentence Embedding概念阐述的示例的代码。该代码用最简单的方式实现了Word2Vec中的部分主要功能,即Skip-Gram模型以及Negative Samping加速分类算法。在设定word embedding维度为200以及num step为600001后,运行结果如下:

由上图可见,词向量是randomly init的,所以他认为six跟conjuring或者analogies相近。另外,在刚init的时机,loss数是302.11。在20万此迭代后,average loss为4.96。此时的nearest测试结果如下:

我们可见此时,跟six相近的词为seven, five, four和eight, 并且与has相似的有had, have等。这个结果已经初步证明系统已经学习到了一些特征,但是有的词例如history,所对应的词是reginae,这个连含义都不清楚的词和明显跟history的意义不相关。所以可见系统并不完善,只是简单的词儿比较容易先学到。另外,从20万个到第40万step,我们发现loss降低的并不明显。在训练的最后,结果展示如下:

history跟culture的北美的环境里有些许相似的成分,所以可见系统穷时变得更加的好了。同时,i本身作为罗马数字的一面(即ii)和作为我的一面(即we)也被很好的展现了出来。这个结果是encouraging的,因为系统其实变得更好了。但是一直到60万step, loss还停留在4.52左右,于20万的4.96区别不大,由此可见学习进入smoothing区域。
但系统到底在词义以及词性上的结果到底如何呢?我们通过以下一些实验为大家证明。具体的代码如下:
# Testing final embedding
input_dictionary = dict([(v,k) for (k,v) in reverse_dictionary.iteritems()])
#找寻france, paris和rome的word index
test_word_idx_a = input_dictionary.get('france')
test_word_idx_b = input_dictionary.get('paris')
test_word_idx_c = input_dictionary.get('rome')
#在final_embeddings(也就是我们系统学到的embedding)里寻找上述词
a = final_embeddings[test_word_idx_a,:]
b = final_embeddings[test_word_idx_b,:]
c = final_embeddings[test_word_idx_c,:]
#通过algebra的方式寻找预测词
ans = c + (a - b)
similarity = final_embeddings.dot(ans)
print similarity.shape
print similarity[0:10]
#选取最近的4个词展示出来
top_k = 4
nearest = (-similarity).argsort()[0:top_k+1]
print nearest
for k in xrange(top_k+1):
close_word = reverse_dictionary[nearest[k]]
print(close_word)
所得结果如下:
当输入a = france, b = paris, c = rome时,系统回答我词汇近似于[rome, france, thibetanus, mnras, schwaben]。 当输入为a = king, b = man, c = woman时,系统回答为[king, woman, philip, mayr, eulemur]。这里的结果并不理想。训练时间上,60万个step时间并不是很长,也不短,之前没注意记时间,但是运算时间大体在1小时左右。
这个模型是Tensorflow对word embedding的加强式示例,其默认迭代数为15次,运行结果如下:

15 epoches之后的正确率为36.7%。 在设定迭代数量为50次后,该结果为39%, 迭代数为100时,accuracy也没超过40%,停留在39.7%。 当运行了200次迭代后,总算达到了40%,虽然耗时为大约7小时。至于系统于一些基础问题上的运行结果,我们对15词迭代的结果进行了测试,结果如下:

从以上简单的测试中,我们已经发现其效果一般,但比较basic版本还是要好很多的。其中,有名的king, man, queen, woman问题系统并没有回答正确。
Gensim的Word2Vec:
Gensim是一个很常用的深度学习topic modeling工具。在编写,运用方式以及效果上肯定会优于Tensorflow的版本。Gensim的Word2Vec系统在网上有许多教程,这里提供一下两个供大家参考,解释的均很不错,基本属于可以直接运用的类型:1)http://rare-technologies.com/word2vec-tutorial/ 2)http://www.open-open.com/lib/view/open1420687622546.html
系统的运行结果如下:
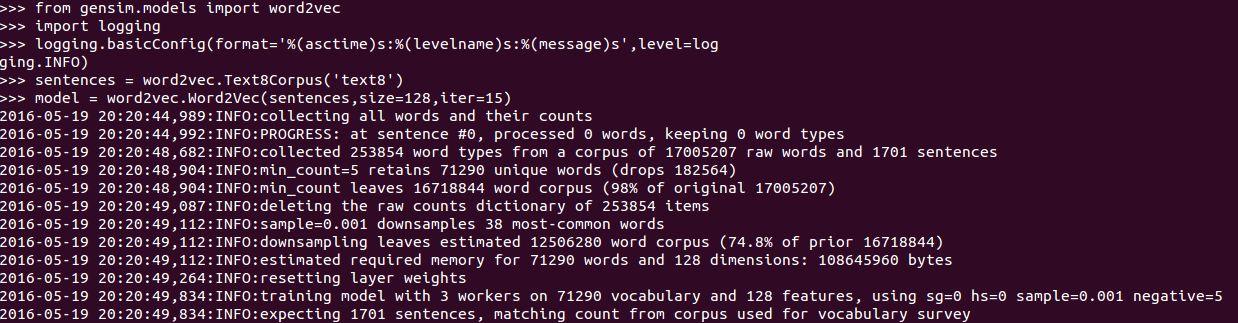
在运行时,我们把word_embedding的size设为128, 运行迭代15次。训练完成模型后,对模型用questions-words.txt文件进行评测:

这份不仅我们观察到其效果如何,我们更是直观的了解了gensim的系统在哪些地方表现的不错,哪里有不足。比如在family这个大类中,所出现的问题为[grandfather grandmother grandpa grandma],系统在这方面正确率颇高,为82%,但是在预测省内的都市时,效果却仅达到18.1%。 这个直观的系统让我们快速了解了word2vec的学习效率以及学习优缺点,但是对于我们常用的问题会做的如何呢?测试结果如下:
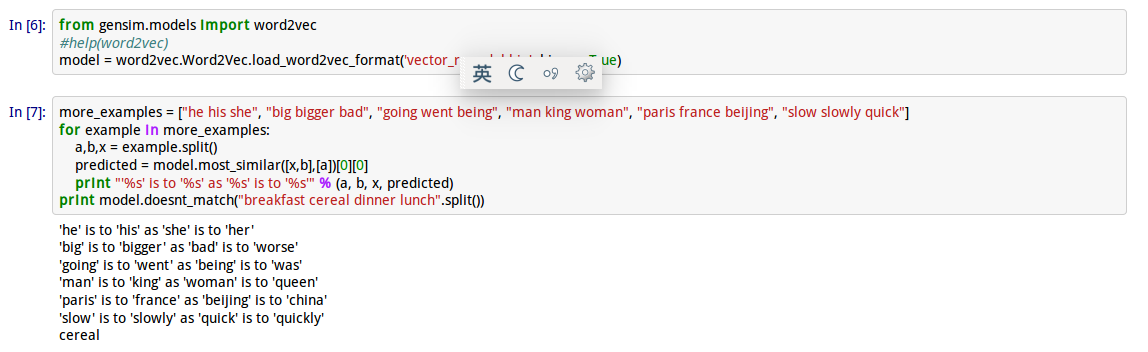
由此可见,系统答对了我们询问的全部问题,虽然问题基数很小,但对比之前的系统,说明gensim做的可以很好,也能更好!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号