
MongoDB入门实战教程(7)
 前面我们学习了聚合查询,本篇我们来看看在模型设计中如何应用引用模式来提高查询效率。本文简单介绍了MongoDB的模型设计中的内嵌模式和引用模式,探讨了引用模式的使用、何时使用 及 使用限制。
前面我们学习了聚合查询,本篇我们来看看在模型设计中如何应用引用模式来提高查询效率。本文简单介绍了MongoDB的模型设计中的内嵌模式和引用模式,探讨了引用模式的使用、何时使用 及 使用限制。
本系列教程目录:
前面我们学习了聚合查询,本篇我们来看看在模型设计中如何应用引用模式来提高查询效率。
1内嵌模式
在进行MongoDB的模型设计中,基于JSON文档模型,我们很容易就可以设计出一个内嵌模式的文档模型出来。
可以不夸张地说,80%~90%的场景下,我们优先都会使用内嵌对象 或 内嵌数组 的方式来设计文档模型的所谓的1-1、1-N、N-N的关系。
例如下面这个Contacts的文档模型,它描述了一个联系人的关系建模:
Contacts { name: "Edison Zhou", company: "CSCEC YZW", title: ".NET Engineer", portraits: { mimetype: xxx, data: xxxx }, addresses: [ { type: home, … }, { type: work, … } ], groups: [ {name: "YZW Football Assocation" }, {name: "YZW .NET Assocation" } ] }
可以看到,所谓的内嵌类 其实 类似于 预先聚合(关联),这样的操作(引用+冗余)其实对读操作更有性能优势。
但是,内嵌设计有一个大前提限制:即内嵌后文档大小不能超过16MB。
此外,如果内嵌的数组(通常是数组)的长度太大,比如数万或更多的时候,也是不适合采用内嵌模式的。
那么,此时我们应该怎么设计呢?
2 引用模式
万级长度的内嵌数组
这里我们仍然适用上面提到的Contacts模型,假设其中的groups是一个内嵌数组,这个groups的数据可能有百万级的长度,且每个Contacts文档都需要冗余这么一份数据,而且groups数据还面临着频繁修改的需求。
Contacts { name: "Edison Zhou", company: "CSCEC YZW", title: ".NET Engineer", ...... // 假设下面groups有百万级,且一个group的信息改动会引发百万级的DB操作 groups: [ {name: "YZW Football Assocation" }, {name: "YZW .NET Assocation" } ] }
适当使用引用模式解决
解决方案很简单,就是针对groups使用单独的collection来存储,在Contancts模型中添加对group id的集合的引用。
Collection 1 - Contacts:
Contacts { name: "Edison Zhou", company: "CSCEC YZW", title: ".NET Engineer", ...... // 假设下面groups有百万级,且一个group的信息改动会引发百万级的DB操作 group_ids: [1,2,3,4,5...] }
Collection 2 - Groups:
Groups
{
groups_id,
name
}
这样的设计其实类似于关系型数据库模型的设计,用Id来关联,我们再熟悉不过了。
但是,在MQL中,我们就需要额外使用$lookup来实现类似SQL中的关联查询了,严格来说,应该算是LEFT OUTER JOIN查询。
嗯,这又是一种聚合操作:
db.Contacts.aggregate([ { $lookup: { from: "groups", localField: "group_ids", foreignField: "group_id", as: "groups" } }]);
这个查询会得到如下图所示的结果:
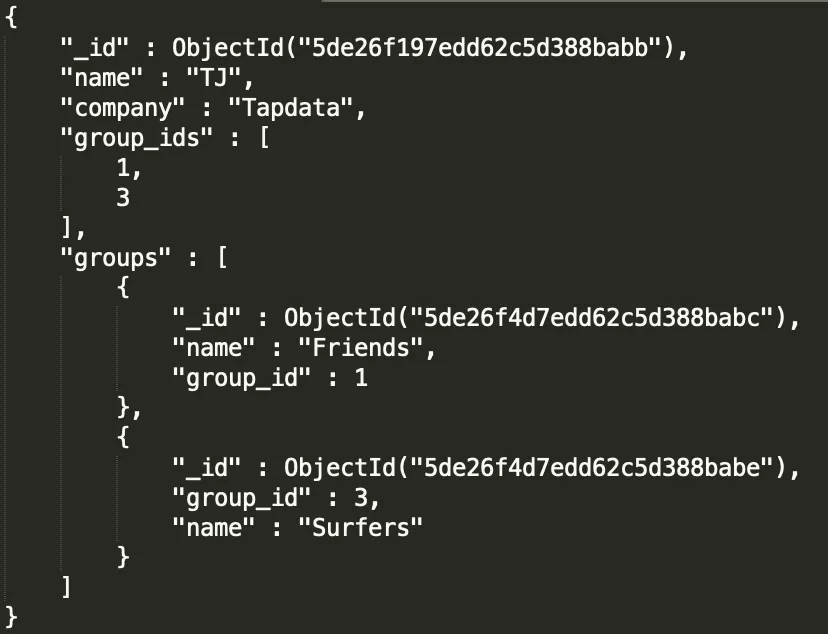
.NET中的Lookup操作:
上面讲解了如何通过MQL进行操作,那么,在.NET中如何实现$lookup的效果呢?
好在MongoDB Driver已经帮我们提供了这样的一个LookUp,且看下面的代码示例:
假设我们的实体定义如下:
public class Contact { [BsonId] [BsonRepresentation(BsonType.ObjectId)] public string Id { get; set; } public string Name { get; set; } public string Company { get; set; } public string Title { get; set; } public int[] GroupIds { get; set; } public IList<Group> Groups { get; set; } } public class Group { [BsonId] [BsonRepresentation(BsonType.ObjectId)] public string Id { get; set; } public int GroupId { get; set; } public string Name { get; set; } }
那么,可以通过Driver实现以下操作:
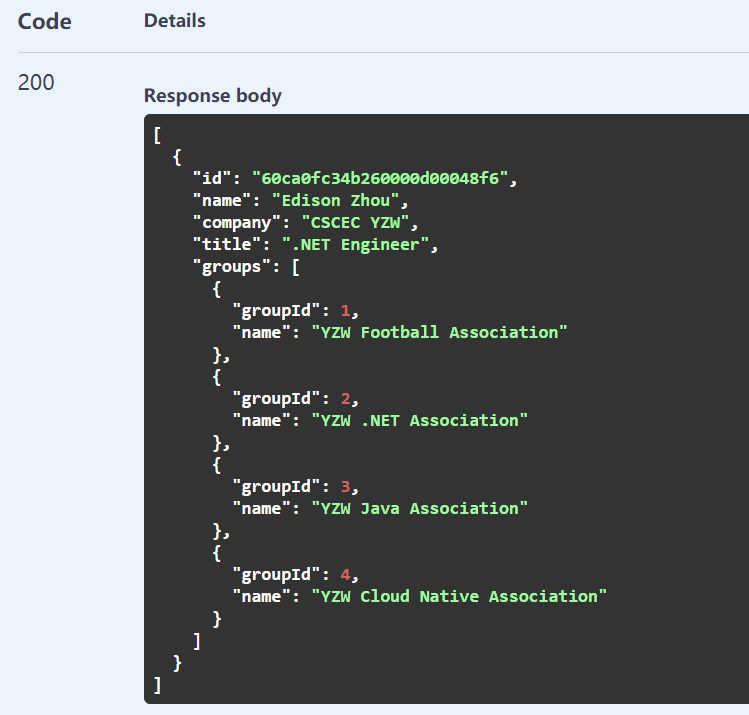
public async Task<IList<Contact>> GetAsync() { return await _contacts .Aggregate() .Lookup<Contact, Group, Contact>( _groups, local => local.GroupIds, from => from.GroupId, result => result.Groups) .ToListAsync(); }
完整示例github地址:https://github.com/EdisonChou/EDT.Mongo.Sample
运行结果如下所示:
什么时候使用引用模式
综上所述,当满足以下条件之一时,你可以开始考虑引用模式设计文档模型:
(1)当内嵌后的文档太大,有可能超过16MB限制的时候;
(2)内嵌的文档 或 数组元素 有可能会频繁修改的时候;
(3)内嵌数组元素 有可能会持续增长且没有封顶的时候;
引用模式设计的限制
引用模式也并非银弹,它存在以下一些限制:
(1)MongoDB对于使用引用的集合之间没有所谓的外键检查;
(2)MongoDB使用聚合框架的$lookup来模仿关联查询;
(3)$lookup只支持LEFT OUTER JOIN,且关联目标(from)不能是分片表;
db.Contacts.aggregate([ { $lookup: { from: "groups", // 这里的from不能是分片表 ...... } }]);
总结
本文简单介绍了MongoDB的模型设计中的内嵌模式和引用模式,探讨了引用模式的使用、何时使用 及 使用限制。
下一篇,我们会学习MongoDB的模式设计中的一些设计模式并套用这些设计模式简化设计难度。
参考资料
唐建法,《MongoDB高手课》(极客时间)
郭远威,《MongoDB实战指南》(图书)

△推荐订阅学习



 浙公网安备 33010602011771号
浙公网安备 33010602011771号