
MongoDB入门实战教程(13)
 MongoDB的一大特色就在于其原生的横向扩展能力,具体体现就是分片集。本篇,我们来了解一下MongoDB分片集的机制及其原理。本文简单介绍了MongoDB分片集的机制及原理,最后介绍了MongoDB数据分片的三种基本策略。
MongoDB的一大特色就在于其原生的横向扩展能力,具体体现就是分片集。本篇,我们来了解一下MongoDB分片集的机制及其原理。本文简单介绍了MongoDB分片集的机制及原理,最后介绍了MongoDB数据分片的三种基本策略。
MongoDB的一大特色就在于其原生的横向扩展能力,具体体现就是分片集。本篇,我们来了解一下MongoDB分片集的机制及其原理。
1 为什么要分片?
我们都知道,在关系型数据库如MySQL中,当数据量过大造成事务执行缓慢的时候,减少每次查询数据总量是解决之道。因为,数据量一旦过大,索引也会相应增大,这时对索引的维护成本也会增加,进而降低事务执行性能。这时,我们的总体解决思路一般都是 分表。
在MongoDB中,当数据容量日益增大访问性能日渐降低时,单库已有巨大数据量如10TB时,我们的解决思路其实也是 分表,只不过在MongoDB中,这叫 分片集。
分片集是MongoDB提供的一个原生的横向扩展能力,无需引入其他的中间件就可以轻松实现。
未分片:
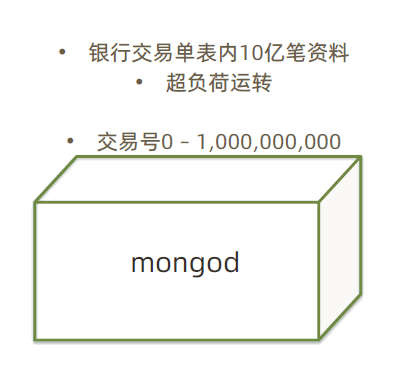
两个分片集:
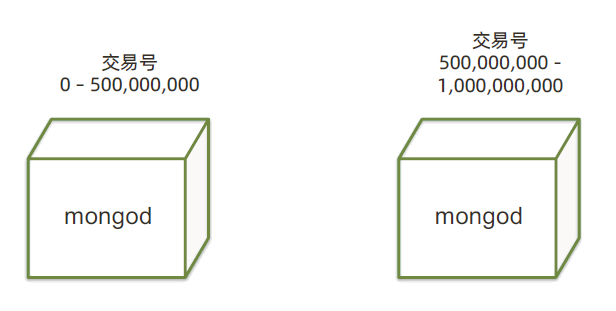
当使用分片之后,单个分片集的数据量就有了限制,从而保证了查询的性能。更为重要的是,增加一个分片,使用的时间可控,这就为横向扩展提供了良好的基础。
2 引入分片集的部署架构
首先,我们来看看MongoDB常见部署的架构,如下图所示:

可以看到,MongoDB可以单机运行、可以复制集运行 也可以 分片集群运行。复制集可以保证数据的高可用,而分片集群则可以保证横向扩展性。
其次,我们来看看一个完整分片集群到底长什么样,它如下图所示:
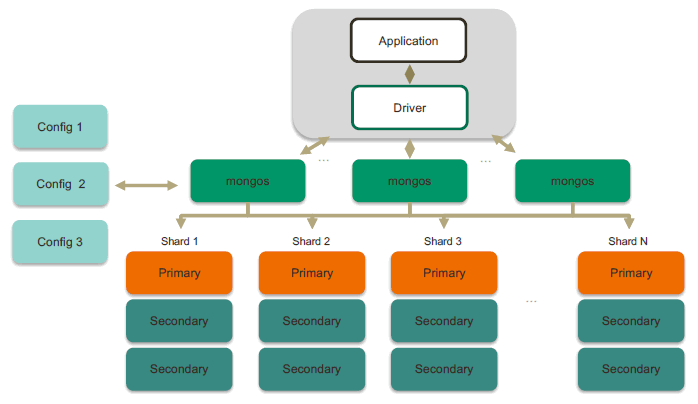
从上图所知,整个分片集群会包括如下几个组成部分:
(1)mongos
mongos是路由节点,它承上启下,作为mongodb集群的单一入口,它主要转发应用程序端的请求 并 选择合适的数据节点进行读写,最后合并多个数据节点的返回。mongos是无状态的,一般建议至少部署两个节点,推荐三个。
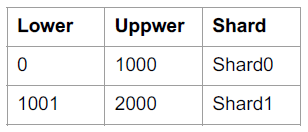
(2)config
config是配置(目录)节点,你可以理解为它存储了如何分片的规则,这些规则就是元数据,类似于下表所示的数据:
(3)replica set 复制集
复制集节点就是最终的数据存储节点了,以复制集为单位,横向扩展。MongoDB允许最大有1024个分片,每个分片的数据不重复,所有分片在一起才可以完整工作。在实际应用场景中,最佳实践是每个分片的数据量尽量不超过3TB,尽可能保持在2TB内一个分片,可以提供最佳的读写性能。
这里再介绍一下,一个分片集群内部到底包含哪些东西?
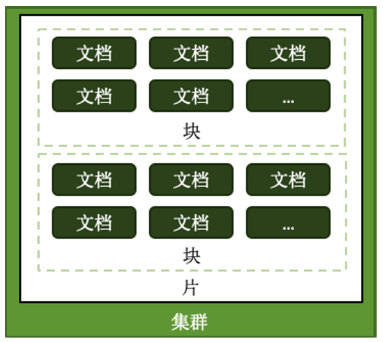
一个集群(Cluster)包括多个分片(Shard),每个分片包含多个块(Chunk),每个块包含多个文档(Document),每个文档包含了一行含有片键(Shard Key)的数据,而这个片键就是文档中的一个用来进行分片的字段。
最后,MongoDB分片集群到底有什么特点?
(1)对于应用程序端,它完全透明,不需要额外的特殊处理,只需要对接mongos节点就行。
(2)mongos对数据自动均衡,应用程序端不需要像Memcached一样做客户端负载均衡。
(3)分片集可以做到动态扩容,无须对已有MongoDB服务下线。
因此,基于分片集的这些机制和特点,建议生产环境尽量使用分片集群,当然前提是你有足够的硬件资源如CPU、内存 和 磁盘。
3 分片集的数据分布策略
MongoDB分片集提供了三种数据分布的策略:
(1)基于范围(Range)
(2)基于哈希(Hash)
(3)基于zone/tag
基于范围分片
首先,基于范围的数据分片很好理解,通常会按照某个字段如创建日期来区分不同范围的数据存储。
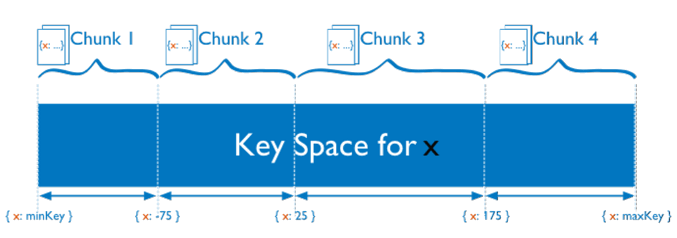
其优点是分片范围的查询性能足够好,缺点是存在热点数据问题,数据的分布可能会不够均匀。
基于哈希分片
其次,基于Hash的分片策略也比较好理解,通常会按照某个字段的哈希值来确定数据存储的位置。
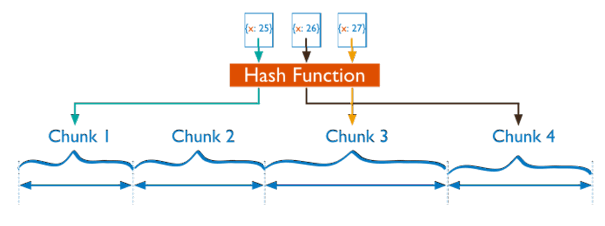
其优点是数据的分布会比较均匀,缺点则是范围查询的效率会较低,因为可能会涉及在多个节点读取数据并聚合。
基于Zone/Tag分片
最后,基于zone/tag的数据分片则有点不太好理解,它不是一般我们所熟知的分片方式。所谓基于zone/tag的数据分片,一般是指在两地三中心或异地多活的应用场景中,如果数据存在地域性的访问需求,那么就可以自定义Zone来进行分片。
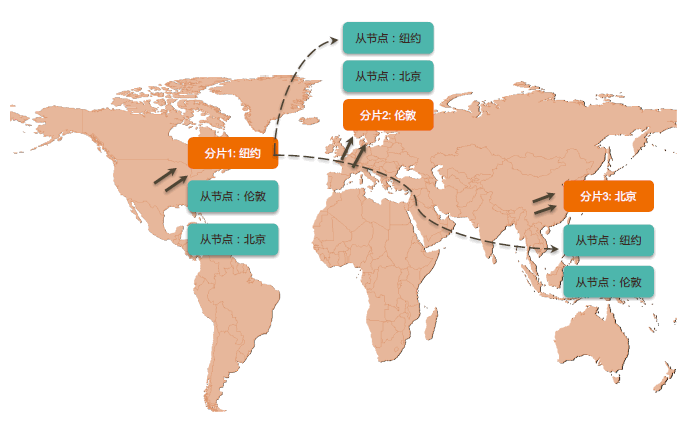
通过打tag的方式,可以实现将为某个地域服务的数据存储到指定地域的数据分片上(比如CountryCode=NewYork),最终实现本地读和本地写的目的。
4 分片集群的搭建
由于MongoDB分片集群的搭建偏运维,我这里就不做实践了。
网上有很多相关的操作指南,有兴趣的童鞋也可以看看这篇:MongoDB 4.4.1 分片集搭建
5 总结
本文简单介绍了MongoDB分片集的机制及原理,最后介绍了MongoDB数据分片的三种基本策略。
下一篇,我们会总结MongoDB应用开发的最佳实践,它也会是本系列的最后一篇文章。
参考资料
唐建法,《MongoDB高手课》(极客时间)
郭远威,《MongoDB实战指南》(图书)

△推荐订阅学习



 浙公网安备 33010602011771号
浙公网安备 33010602011771号