
操作系统核心原理-5.内存管理(中):分页内存管理
 在上一篇介绍的几种多道编程的内存管理模式中,以交换内存管理最为灵活和先进。但是这种策略也存在很多重大问题,而其中最重要的两个问题就是空间浪费和程序大小受限。那么有什么办法可以解决交换内存存在的这些问题呢?答案是分页,它是我们解决交换缺陷的“不二法门”。分页系统的核心在于:将虚拟内存空间和物理内存空间皆划分为大小相同的页面,如4KB、8KB或16KB等,并以页面作为内存空间的最小分配单位,一个程序的一个页面可以存放在任意一个物理页面里。
在上一篇介绍的几种多道编程的内存管理模式中,以交换内存管理最为灵活和先进。但是这种策略也存在很多重大问题,而其中最重要的两个问题就是空间浪费和程序大小受限。那么有什么办法可以解决交换内存存在的这些问题呢?答案是分页,它是我们解决交换缺陷的“不二法门”。分页系统的核心在于:将虚拟内存空间和物理内存空间皆划分为大小相同的页面,如4KB、8KB或16KB等,并以页面作为内存空间的最小分配单位,一个程序的一个页面可以存放在任意一个物理页面里。
在上一篇介绍的几种多道编程的内存管理模式中,以交换内存管理最为灵活和先进。但是这种策略也存在很多重大问题,而其中最重要的两个问题就是空间浪费和程序大小受限。那么有什么办法可以解决交换内存存在的这些问题呢?答案是分页,它是我们解决交换缺陷的“不二法门”。
一、分页内存管理
1.1 解决问题之道
为了解决交换系统存在的缺陷,分页系统横空出世。分页系统的核心在于:将虚拟内存空间和物理内存空间皆划分为大小相同的页面,如4KB、8KB或16KB等,并以页面作为内存空间的最小分配单位,一个程序的一个页面可以存放在任意一个物理页面里。
(1)解决空间浪费碎片化问题
由于将虚拟内存空间和物理内存空间按照某种规定的大小进行分配,这里我们称之为页(Page),然后按照页进行内存分配,也就克服了外部碎片的问题。
(2)解决程序大小受限问题
程序增长有限是因为一个程序需要全部加载到内存才能运行,因此解决的办法就是使得一个程序无须全部加载就可以运行。使用分页也可以解决这个问题,只需将当前需要的页面放在内存里,其他暂时不用的页面放在磁盘上,这样一个程序同时占用内存和磁盘,其增长空间就大大增加了。而且,分页之后,如果一个程序需要更多的空间,给其分配一个新页即可(而无需将程序倒出倒进从而提高空间增长效率)。
1.2 虚拟地址的构成与地址翻译
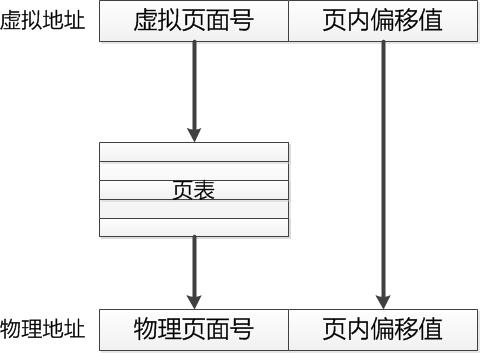
(1)虚拟地址的构成
在分页系统下,一个程序发出的虚拟地址由两部分组成:页面号和页内偏移值,如下图所示:

例如,对于32位寻址的系统,如果页面大小为4KB,则页面号占20位,页内偏移值占12位。
(2)地址翻译:虚拟地址→物理地址
分页系统的核心是页面的翻译,即从虚拟页面到物理页面的映射(Mapping)。该翻译过程如下伪代码所示:
if(虚拟页面非法、不在内存中或被保护) { 陷入到操作系统错误服务程序 } else { 将虚拟页面号转换为物理页面号 根据物理页面号产生最终物理地址 }
而这个翻译过程由内存管理单元(MMU)完成,MMU接收CPU发出的虚拟地址,将其翻译为物理地址后发送给内存。内存管理单元按照该物理地址进行相应访问后读出或写入相关数据,如下图所示:
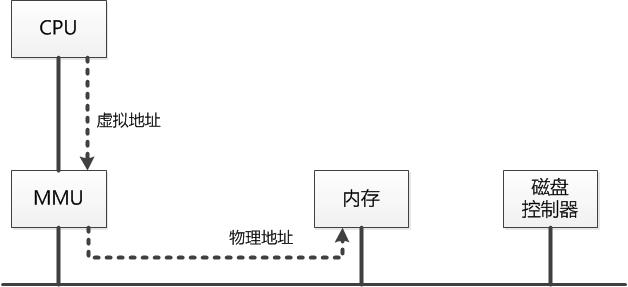
那么,这个翻译是怎么实现的呢?答案是查页表,对于每个程序,内存管理单元MMU都为其保存一个页表,该页表中存放的是虚拟页面到物理页面的映射。每当为一个虚拟页面寻找到一个物理页面之后,就在页表里增加一条记录来保留该映射关系。当然,随着虚拟页面进出物理内存,页表的内容也会不断更新变化。
1.3 页表
页表的根本功能是提供从虚拟页面到物理页面的映射。因此,页表的记录条数与虚拟页面数相同。此外,内存管理单元依赖于页表来进行一切与页面有关的管理活动,这些活动包括判断某一页面号是否在内存里,页面是否受到保护,页面是否非法空间等等。
页表的一个记录所包括的内容如下图所示:

由于页表的特殊地位,决定了它是由硬件直接提供支持,即页表是一个硬件数据结构。
1.4 分页系统的优缺点
优点:
(1)分页系统不会产生外部碎片,一个进程占用的内存空间可以不是连续的,并且一个进程的虚拟页面在不需要的时候可以放在磁盘中。
(2)分页系统可以共享小的地址,即页面共享。只需要在对应给定页面的页表项里做一个相关的记录即可。
缺点:页表很大,占用了大量的内存空间。
1.5 缺页中断处理
在分页系统中,一个虚拟页面既有可能在物理内存,也有可能保存在磁盘上。如果CPU发出的虚拟地址对应的页面不在物理内存,就将产生一个缺页中断,而缺页中断服务程序负责将需要的虚拟页面找到并加载到内存。缺页中断的处理步骤如下,省略了中间很多的步骤,只保留最核心的几个步骤:

二、页面置换算法
如果发生了缺页中断,就需要从磁盘上将需要的页面调入内存。如果内存没有多余的空间,就需要在现有的页面中选择一个页面进行替换。使用不同的页面置换算法,页面更换的顺序也会各不相同。如果挑选的页面是之后很快又要被访问的页面,那么系统将很开再次产生缺页中断,因为磁盘访问速度远远内存访问速度,缺页中断的代价是非常大的。因此,挑选哪个页面进行置换不是随随便便的事情,而是有要求的。
2.1 页面置换的目标
页面置换时挑选页面的目标主要在于降低随后发生缺页中断的次数或概率。
因此,挑选的页面应当是随后相当长时间内不会被访问的页面,最好是再也不会被访问的页面。BTW,如果可能,最好选择一个没有修改过的页面,这样替换时就无须将被替换页面的内容写回磁盘,从而进一步加快缺页中断的响应速度。
所以,为了达到这个目的,先驱们设计出了各种各样的页面置换算法,下面就来看看这些算法。
2.2 随机更换算法
在需要替换页面的时候,产生一个随机页面号,从而替换与该页面号对应的物理页面。遗憾的是,随机选出的被替换的页面不太可能是随后相当长时间内不会被访问的页面。也就是说,这种算法难以保证最小化随后的缺页中断次数。事实上,这种算法的效果相当差。
2.3 先进先出算法
顾名思义,先进先出(FIFO,First In First Out)算法的核心是更换最早进入内存的页面,其实现机制是使用链表将所有在内存中的页面按照进入时间的早晚链接起来,然后每次置换链表头上的页面就行了,而新加进来的页面则挂在链表的末端,如下图所示:

FIFO的优点是简单且容易实现,缺点是如果最先加载进来的页面是经常被访问的页面,那么就可能造成被访问的页面替换到磁盘上,导致很快就需要再次发生缺页中断,从而降低效率。
2.4 第二次机会算法
由于FIFO只考虑进入内存的时间,不关心一个页面被访问的频率,从而有可能造成替换掉一个被经常访问的页面而造成效率低下。那么,可以对FIFO进行改进:在使用FIFO更换一个页面时,需要看一下该页面是否在最近被访问过,如果没有被访问过,则替换该页面。反之,如果最近被访问过(通过检查其访问位的取值),则不替换该页面,而是将该页面挂到链表末端,并将该页面进入内存的时间设置为当前时间,并将其访问位清零。这样,对于最近被访问过的页面来说,相当于给了它第二次机会。
例如,当A页面最近被访问过,即其访问位R的值为1,则使用第二次机会算法之后,链表的格局如下图所示:
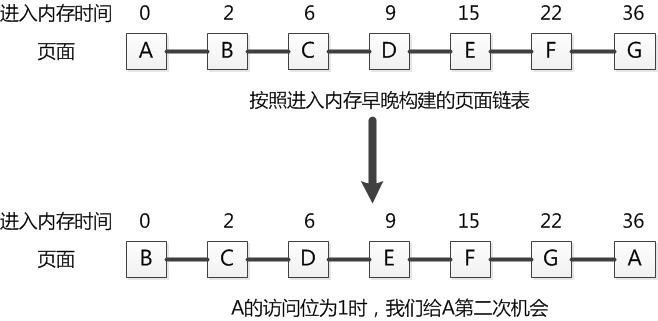
第二次机会算法简单、公平且容易实现。但是,每次给予一个页面第二次机会时,将其移动到链表末端需要耗费时间。此外,页面的访问位只在页面替换进行扫描时才可能清零,所以其时间局域性体现得不好,访问位为1的页面可能是很久以前访问的,时间上的分辨粒度太粗,从而影响页面替换的效果。
2.5 时钟算法
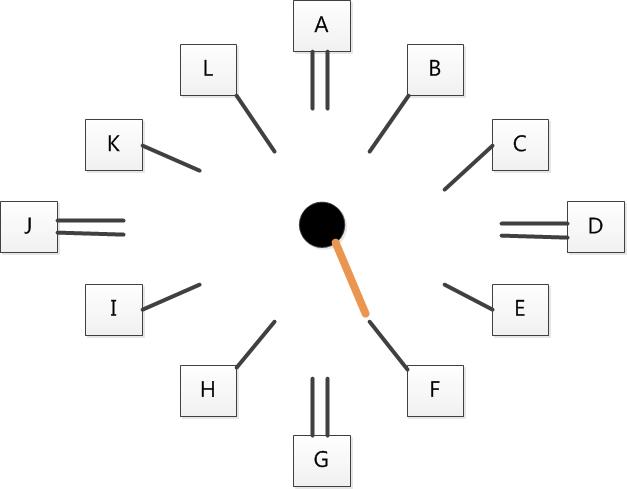
为了改善第二次机会算法的缺点,先驱们提出了时钟算法。时钟算法的核心思想是:将页面排成一个时钟的形状,该时钟有一个针臂,每次需要更换页面时,我们从针臂所指的页面开始检查。如果当前页面的访问位为0,即从上次检查到这次,该页面没有被访问过,将该页面替换。反之,就将其访问位清零,并顺时针移动指针到下一个页面。重复这些步骤,直到找到一个访问位为0的页面。
例如下图所示的一个时钟,指针指向的页面是F,因此第一个被考虑替换的页面是F。如果页面F的访问位为0,F将被替换。如果F的访问位为1,则F的访问位清零,指针移动到页面G。
从表面上看,它和第二次机会算法类似,都是访问位为0就更换,反之则再给一次机会。但是,它和第二次机会算法还是有几点不同:
(1)他们的数据结构不一样,第二次机会使用的是链表,时钟算法使用的是索引(整数指针)。这样,其使用的内存空间不一样。
(2)第二次机会需要使用额外的内存,而时钟算法可以直接使用页表。使用页表的好处是无需额外的空间,更大的好处是页面的访问位会定期自动清零,这样将使得时钟算法的时间分辨粒度较第二次机会算法高,从而取得更好的页面替换效果。
时钟算法的精髓是第二次机会,其缺点也就和第二次机会算法一样:过于公平,没有考虑到不同页面调用频率的不同,有可能换出不应该或不能换出的页面,还可能造成无限循环。
PS:至此,随机、FIFO、第二次机会与时钟算法的介绍就到此结束,这四种算法都是属于“公平算法”,即所有的页面都或多或少地给予公平待遇,没有页面获得特殊待遇。但是这种公平实现方式,会使效率受到一定影响,这时因为个体对于整个系统的贡献没有被区别对待,造成贡献大的和贡献小的待遇一样,自然会影响整个系统的效率。
2.6 最优更换算法
我们知道,最理想的页面替换算法是选择一个再也不会被访问的页面进行替换。如果不存在这样的页面,那至少选择一个在随后最长时间内不会被访问的页面进行替换。这样,我们就可以保证在随后发生缺页中断的次数最小或概率最低,这种算法就是最有替换算法。
但是,我们没法知道一个页面随后多长时间不会被访问,因此最优更换算法在实际中没法实现,那么为什么要介绍最有更换算法呢?这是为了定义一个标杆,以此来评判其他算法的优劣。
2.7 NRU(最近未被使用)算法
顾名思义,NRU就是选择一个在最近一段时间内没有被访问过的页面进行替换,这是基于程序访问的时空局域性。因为根据时空局域性原理,一个最近没有被访问的页面,在随后的时间里也不太可能被访问,而NRU的实现方式就是利用页面的访问和修改位。
每个页面都有一个访问位和一个修改位,凡是对页面进行读写操作时,访问位被设置为1。当进程对页面进行读写操作时,修改位设置为1。根据这两个位的状态来对页面进行分类的话,可以分成以下四种页面类型:1、2、3、4。

有了这个分类,NRU算法就按照这四类页面的顺序依次寻找可以替换的页面。如果所有页面皆被访问和修改过,那也只能从中替换掉一个页面,因此NRU算法总是会终结的。
当然,这种分类比较笼统,在同一类页面里,我们没有办法分辨出哪一类被访问的时间更近一些。即在某些情况下,我们替换的可能并不是最近没有被使用的页面。
2.8 LRU(最近最少使用)算法
与NRU算法相比,LRU算法不仅考虑最近是否用过,还要考虑最近使用的频率。这里是基于过去的数据预测未来:如果一个页面被访问的频率低,那么以后很可能也用不到。
LRU算法的实现必须以某种方式记录每个页面被访问的次数,这是个相当大的工作量。最简单的方式就是在页表的记录项里增加一个计数域,一个页面被访问一次,这个计数器的值就增加1。于是,当需要更换页面时,只需要找到计数域值最小的页面替换即可,该页面即是最近最少使用的页面。另一种简单实现方式就是用一个链表将所有页面链接起来,最近被使用的页面在链表头,最近未被使用的放在链表尾。在每次页面访问时对这个链表进行更新,使其保持最近被使用的页面在链表头。
LRU算法虽然很好,但是实现成本高(需要分辨出不同页面中哪个页面时最近最少使用的),并且时间代价大(每次页面访问发生时都需要更新记录)。因此,一般的商业操作系统都没有采纳LRU页面更新算法。
2.9 工作集算法
由于不可能精确地确定那个页面是最近最少使用的,那就干脆不花费这个力气,只维持少量的信息使得我们选出的替换页面不太可能是马上又会使用的页面即可。这种少量的信息就是工作集信息。
工作集概念来源于程序访问的时空局限性,即在一段时间内,程序访问的页面将局限在一组页面集合上。例如,最近k次访问均发生在某m个页面上,那么m就是参数为k时的工作集。我们用w(k,t)来表示在时间t时k次访问所涉及的页面数量。
显然,随着k的增长,w(k,t)的值也随之增长;但是当k增长到某个数值之后,w(k,t)的值将增长极其缓慢甚至接近停滞,并维持一段时间的稳定,如下图所示:

由上图可以看出,如果一个程序在内存里面的页面数与其工作集大小相等或者超过工作集,则该程序可在一段时间内不会发生缺页中断。如果其在内存的页面数小于工作集,则发生缺页中断的频率将增加,甚至发生内存抖动。
因此,工作计算法的目标就是维持当前的工作集的页面在物理内存里面。每次页面更换时,寻找一个不属于当前工作集的页面替换即可。这样,我们再寻找页面时只需要将页面分离为两大类即可:当前工作集内页面和当前工作集外页面。如此,只要找到一个飞当前工作集的页面,将其替换即可。
工作集算法的优点:实现简单,只需要在页表的每个记录增加一个虚拟时间域即可。而且,这个时间域不是每次发生访问时都需要更新,而是在需要更换页面时,页面更换算法对其进行修改,因此时间成本也不大。
工作集算法的缺点:每次扫描页面进行替换时,有可能需要扫描整个页表。然而,并不是所有页面都内存里,因此扫描过程中的一大部分时间将是无用功。另外,由于其数据结构是线性的,会造成每次都按同样的顺序进行扫描,显得不太公平。
2.10 工作集时钟算法
鉴于工作集算法的缺点,先驱们将工作集算法与时钟算法结合起来,设计出了工作集时钟算法,即使用工作集算法的原理,但是将页面的扫描顺序按照时钟的形式组织起来。这样每次需要替换页面时,从指针指向的页面开始扫描,从而达到更加公平的状态。而且,按时钟组织的页面只是在内存里面的页面,在内存外的页面不放在时钟圈里,从而提高实现效率。
鉴于其时间与空间上的优势,工作集时钟算法被大多商业操作系统所采纳。
参考资料

邹恒明,《操作系统之哲学原理》,机械工业出版社


 浙公网安备 33010602011771号
浙公网安备 33010602011771号