
走向面试之数据库基础:一、你必知必会的SQL语句练习-Part 1
 本文是在Cat Qi的参考原帖的基础之上经本人一题一题练习后编辑而成,非原创,仅润色而已。另外,本文所列题目的解法并非只有一种,本文只是给出比较普通的一种而已,也希望各位园友能够自由发挥。
本文是在Cat Qi的参考原帖的基础之上经本人一题一题练习后编辑而成,非原创,仅润色而已。另外,本文所列题目的解法并非只有一种,本文只是给出比较普通的一种而已,也希望各位园友能够自由发挥。
本文是在Cat Qi的参考原帖的基础之上经本人一题一题练习后编辑而成,非原创,仅润色而已。另外,本文所列题目的解法并非只有一种,本文只是给出比较普通的一种而已,也希望各位园友能够自由发挥。
一、三点一线当学霸:“学生-课程-成绩”类题目
1.1 本题目的表结构
Student(S#,Sname,Sage,Ssex) 学生表
Course(C#,Cname,T#) 课程表
SC(S#,C#,score) 成绩表
Teacher(T#,Tname) 教师表
1.2 本题目的建表及测试数据
(1)建表:


1 CREATE TABLE Student 2 ( 3 S# INT, 4 Sname nvarchar(32), 5 Sage INT, 6 Ssex nvarchar(8) 7 ) 8 9 CREATE TABLE Course 10 ( 11 C# INT, 12 Cname nvarchar(32), 13 T# INT 14 ) 15 16 CREATE TABLE Sc 17 ( 18 S# INT, 19 C# INT, 20 score INT 21 ) 22 23 CREATE TABLE Teacher 24 ( 25 T# INT, 26 Tname nvarchar(16) 27 )
注意:建表语句暂未考虑主键以及外键的问题;
(2)测试数据:
1 insert into Student select 1,N'刘一',18,N'男' union all 2 select 2,N'钱二',19,N'女' union all 3 select 3,N'张三',17,N'男' union all 4 select 4,N'李四',18,N'女' union all 5 select 5,N'王五',17,N'男' union all 6 select 6,N'赵六',19,N'女' 7 8 insert into Teacher select 1,N'叶平' union all 9 select 2,N'贺高' union all 10 select 3,N'杨艳' union all 11 select 4,N'周磊' 12 13 insert into Course select 1,N'语文',1 union all 14 select 2,N'数学',2 union all 15 select 3,N'英语',3 union all 16 select 4,N'物理',4 17 18 insert into SC 19 select 1,1,56 union all 20 select 1,2,78 union all 21 select 1,3,67 union all 22 select 1,4,58 union all 23 select 2,1,79 union all 24 select 2,2,81 union all 25 select 2,3,92 union all 26 select 2,4,68 union all 27 select 3,1,91 union all 28 select 3,2,47 union all 29 select 3,3,88 union all 30 select 3,4,56 union all 31 select 4,2,88 union all 32 select 4,3,90 union all 33 select 4,4,93 union all 34 select 5,1,46 union all 35 select 5,3,78 union all 36 select 5,4,53 union all 37 select 6,1,35 union all 38 select 6,2,68 union all 39 select 6,4,71
1.3 开始实战吧小宇宙
(1)查询“001”课程比“002”课程成绩高的所有学生的学号;
1 select a.S# from 2 (select S#,Score from SC where C#='001') a, 3 (select S#,Score from SC where C#='002') b 4 where a.S#=b.S# and a.Score>b.Score
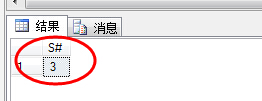
(2) 查询平均成绩大于60分的同学的学号和平均成绩;
1 select S#,AVG(Score) as AvgScore 2 from SC 3 group by S# 4 having AVG(Score)>60

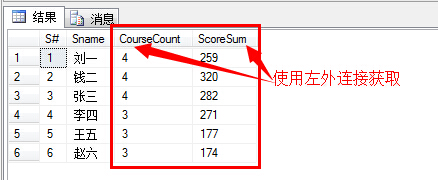
(3)查询所有同学的学号、姓名、选课数、总成绩;
1 select s.S#,s.Sname,COUNT(sc.C#) as CourseCount,SUM(sc.Score) as ScoreSum 2 from Student s left outer join SC sc 3 on s.S# = sc.S# 4 group by s.S#,s.Sname 5 order by s.S#
(4)查询姓“李”的老师的个数;
1 select COUNT(distinct Tname) as count 2 from Teacher 3 where Tname like '李%'

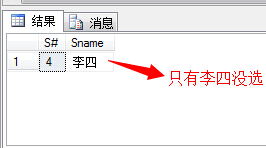
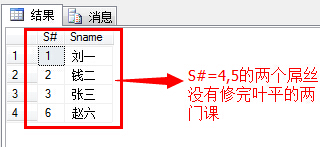
(5)查询没学过“叶平”老师课的同学的学号、姓名;
1 select s.S#,s.Sname 2 from Student s 3 where s.S# not in 4 ( 5 select distinct(sc.S#) from SC sc,Course c,Teacher t 6 where sc.C#=c.C# and c.T#=t.T# and t.Tname='叶平' 7 )
(6)查询学过“001”并且也学过编号“002”课程的同学的学号、姓名;
1 --解法一:求交集 2 select s.S#,s.Sname 3 from Student s,SC sc 4 where s.S#=sc.S# and sc.C#='001' 5 intersect 6 select s.S#,s.Sname 7 from Student s,SC sc 8 where s.S#=sc.S# and sc.C#='002' 9 --解法二:使用exists 10 select s.S#,s.Sname 11 from Student s,SC sc 12 where s.S#=sc.S# and sc.C#='001' and exists 13 ( 14 select * from SC sc2 where sc.S#=sc2.S# and sc2.C#='002' 15 )

PS:EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False。那么,这里我们来看一下in和exists的区别:
①in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。
②一直以来认为exists比in效率高的说法是不准确的。
-->如果查询的两个表大小相当,那么用in和exists差别不大。
-->如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in。
(7)查询学过“叶平”老师所教的所有课的同学的学号、姓名;
1 select s.S#,s.Sname 2 from Student s 3 where s.S# in 4 ( 5 select sc.S# 6 from SC sc,Course c,Teacher t 7 where c.C#=sc.C# and c.T#=t.T# and t.Tname='叶平' 8 group by sc.S# 9 having COUNT(sc.C#)= 10 ( 11 select COUNT(c1.C#) 12 from Course c1,Teacher t1 13 where c1.T#=t1.T# and t1.Tname='叶平' 14 ) 15 )
①测试数据教师表中,叶平老师只有一门课
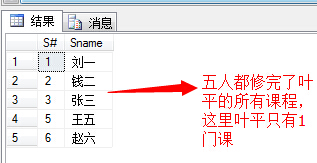
②修改测试数据教师表,将T#=2的TName也改为叶平,叶平就有两门主讲课程了
(8)查询课程编号“002”的成绩比课程编号“001”课程低的所有同学的学号、姓名;
1 select s.S#,s.Sname 2 from Student s, 3 (select sc1.S#,sc1.Score from SC sc1 where sc1.C#='002') a, 4 (select sc2.S#,sc2.Score from SC sc2 where sc2.C#='001') b 5 where s.S#=a.S# and s.S#=b.S# and a.S#=b.S# and a.Score<b.Score
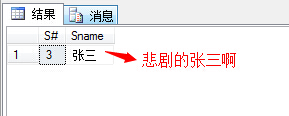
(9)查询有课程成绩小于60分的同学的学号、姓名;
1 select s.S#,s.Sname 2 from Student s 3 where s.S# in 4 ( 5 select distinct(sc.S#) from SC sc 6 where s.S#=sc.S# and sc.Score<60 7 )

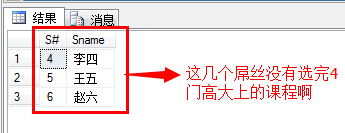
(10)查询没有学全所有课的同学的学号、姓名;
1 select s.S#,s.Sname 2 from Student s 3 where s.S# not in 4 ( 5 select sc.S# from SC sc 6 group by sc.S# 7 having COUNT(distinct sc.C#)= 8 ( 9 select COUNT(distinct c.C#) from Course c 10 ) 11 )
(11)查询至少有一门课与学号为“001”的同学所学相同的同学的学号和姓名;
1 select distinct(s.S#),s.Sname 2 from Student s,SC sc 3 where s.S#=sc.S# and sc.C# in
4 ( 5 select distinct(sc2.C#) from SC sc2 6 where sc2.S#='001' 7 ) 8 order by s.S# asc

(12)查询至少学过学号为“001”同学所有一门课的其他同学学号和姓名;(感觉跟11题有重叠)
1 select distinct(s.S#),s.Sname 2 from Student s,SC sc 3 where s.S#=sc.S# and s.S#!='001' and sc.C# in 4 ( 5 select distinct(sc2.C#) from SC sc2 6 where sc2.S#='001' 7 ) 8 order by s.S# asc
(13)把“SC”表中“叶平”老师教的课的成绩都更改为此课程的平均成绩;
1 update SC set Score= 2 ( 3 select AVG(score) from SC sc,Course c,Teacher t 4 where sc.C#=c.C# and c.T#=t.T# and t.Tname='叶平' 5 ) 6 where C# in 7 ( 8 select distinct(sc.C#) from SC sc,Course c,Teacher t 9 where sc.C#=c.C# and c.T#=t.T# and t.Tname='叶平' 10 )
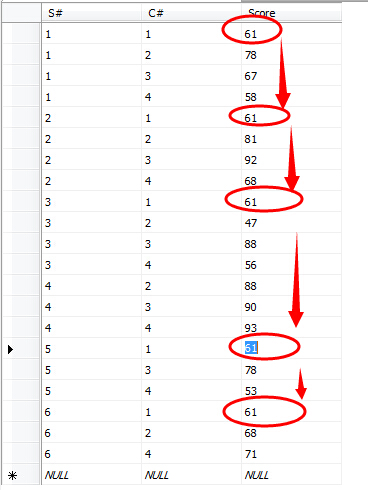
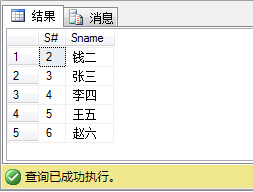
(14)查询和“002”号的同学学习的课程完全相同的其他同学学号和姓名;
select s.S#,s.Sname from Student s where s.S#!='002' and s.S# in ( select distinct(S#) from SC where C# in (select C# from SC where S#='002') group by S# having COUNT(distinct C#)= ( select COUNT(distinct C#) from SC where S#='002' ) )
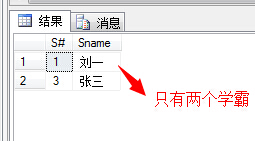
(15)删除学习“叶平”老师课的SC表记录;
delete from SC where C# in ( select c.C# from Course c,Teacher t where c.T#=t.T# and t.Tname='叶平' )
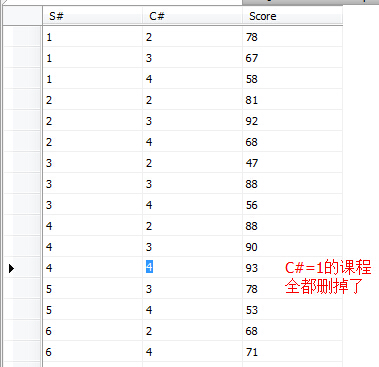
(16)向SC表中插入一些记录,这些记录要求符合以下条件:①没有上过编号“002”课程的同学学号;②插入“002”号课程的平均成绩;
1 insert into SC 2 select s.S#,'002',(select AVG(score) from SC where C#='002') 3 from Student s 4 where s.S# not in (select distinct(S#) from SC where C#='002')
(17)按平均成绩从低到高显示所有学生的“语文”、“数学”、“英语”三门的课程成绩,按如下形式显示: 学生ID,语文,数学,英语,有效课程数,有效平均分;
1 select t.S# as '学生ID', 2 (select Score from SC where S#=t.S# and C#='002') as '语文', 3 (select Score from SC where S#=t.S# and C#='003') as '数学', 4 (select Score from SC where S#=t.S# and C#='004') as '英语', 5 COUNT(t.C#) as '有效课程数', 6 AVG(t.Score) as '有效平均分' 7 from SC t 8 group by t.S# 9 order by AVG(t.Score)

(18)查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分;
1 select sc.C# as '课程ID',MAX(Score) as '最高分',MIN(Score) as '最低分' 2 from SC sc 3 group by sc.C#
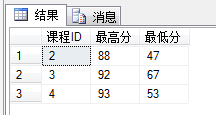
(19)按各科平均成绩从低到高和及格率的百分数从高到低顺序;
1 select sc.C#,c.Cname,ISNULL(AVG(sc.Score),0) as 'AvgScore', 2 100 * SUM(CASE WHEN ISNULL(sc.Score,0)>=60 THEN 1 ELSE 0 END)/COUNT(*) as 'Percent(%)' 3 from SC sc,Course c 4 where sc.C#=c.C# 5 group by sc.C#,c.Cname 6 order by [Percent(%)] desc
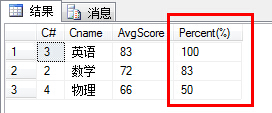
PS:此题难点在于如何求及格率的百分比,我们可以通过判断每一行的Score是否大于等于60分的人数除以该课程的人数获得及格率,然后统一乘以100便得到百分比。这里使用了聚合函数SUM(PassedCounts)/COUNT(AllCounts)得到及格率(小于1的概率),最后乘以100获得百分比。核心是这里的PassedCounts(及格人数)的计算,这里使用了CASE WHEN *** THEN *** ELSE *** END的语句,灵活地对Score进行了判断并赋值(1和0)进行计算。
另外,这里[Percent(%)]可以使用100 * SUM(CASE WHEN ISNULL(sc.Score,0)>=60 THEN 1 ELSE 0 END)/COUNT(*)替代。
(20)查询如下课程平均成绩和及格率的百分数(备注:需要在1行内显示): 企业管理(002),OO&UML (003),数据库(004)
1 select 2 SUM(CASE WHEN C#='002' THEN Score ELSE 0 END)/SUM(CASE C# WHEN '002' THEN 1 ELSE 0 END) as '企业管理平均分', 3 100 * SUM(CASE WHEN C#='002' and Score>=60 THEN 1 ELSE 0 END)/SUM(CASE C# WHEN '002' THEN 1 ELSE 0 END) as '企业管理及格百分比', 4 SUM(CASE WHEN C#='003' THEN Score ELSE 0 END)/SUM(CASE C# WHEN '003' THEN 1 ELSE 0 END) as 'OO&UML平均分', 5 100 * SUM(CASE WHEN C#='003' and Score>=60 THEN 1 ELSE 0 END)/SUM(CASE C# WHEN '003' THEN 1 ELSE 0 END) as 'OO&UML及格百分比', 6 SUM(CASE WHEN C#='004' THEN Score ELSE 0 END)/SUM(CASE C# WHEN '004' THEN 1 ELSE 0 END) as '数据库平均分', 7 100 * SUM(CASE WHEN C#='004' and Score>=60 THEN 1 ELSE 0 END)/SUM(CASE C# WHEN '004' THEN 1 ELSE 0 END) as '数据库及格百分比' 8 from SC

PS:这里出现了两种格式的CASE WHEN语句,但其实这两种方式,可以实现相同的功能。简单case函数(例如上面的:CASE C# WHEN '002' THEN 1 ELSE 0 END)的写法相对比较简洁,但是和case搜索函数(例如上面的:CASE WHEN C#='002' THEN Score ELSE 0 END)相比,功能方面会有些限制,比如写判定式。
(21)查询不同老师所教不同课程平均分从高到低显示;
1 select c.C#,MAX(c.Cname) as 'Cname',MAX(t.T#) as 'T#',MAX(t.Tname) as 'Tname', 2 AVG(sc.Score) as 'AvgScroe' 3 from SC sc,Course c,Teacher t 4 where sc.C#=c.C# and c.T#=t.T# 5 group by c.C# 6 order by AvgScroe desc
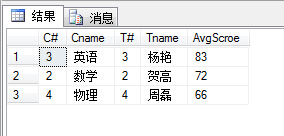
PS:可能有园友会对上题中的很多个MAX(列名)有疑惑,这里我们再来看下Group By语句。这里需要注意的一点就是,在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。因此,上题中我们需要查询课程名,教师名等信息,但又不是分组的依据(分组依据应该是课程号),因此就用MAX()这个聚合函数包裹起来。
(22)查询如下课程成绩第 3 名到第 6 名的学生成绩单:企业管理(001),马克思(002),UML (003),数据库(004)
[学生ID],[学生姓名],企业管理,马克思,UML,数据库,平均成绩
此题没有看明白,跳过。
(23)统计列印各科成绩,各分数段人数:课程ID,课程名称,[100-85],[85-70],[70-60],[ <60]
1 select sc.C#,MAX(c.Cname) as 'CourseName', 2 SUM(CASE WHEN sc.Score BETWEEN 85 and 100 THEN 1 ELSE 0 END) as '[85-100]', 3 SUM(CASE WHEN sc.Score BETWEEN 70 and 85 THEN 1 ELSE 0 END) as '[70-85]', 4 SUM(CASE WHEN sc.Score BETWEEN 60 and 70 THEN 1 ELSE 0 END) as '[60-70]', 5 SUM(CASE WHEN sc.Score BETWEEN 0 and 60 THEN 1 ELSE 0 END) as '[<60]' 6 from SC sc,Course c 7 where sc.C#=c.C# 8 group by sc.C#

(24)查询学生平均成绩及其名次;
1 select s.S#,s.Sname,T2.AvgScore, 2 (select COUNT(AvgScore) from 3 (select S#,AVG(Score) as 'AvgScore' from SC group by S#) as T1 4 where T2.AvgScore<T1.AvgScore)+1 as 'Rank' 5 from 6 (select S#,AVG(Score) as 'AvgScore' from SC 7 group by S#) as T2, 8 Student s 9 where s.S#=T2.S# 10 order by AvgScore desc
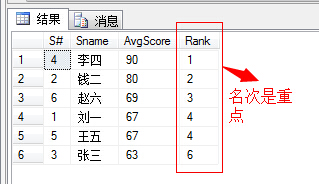
PS:本题目中的名次计算是一个难点,换个思路,我们如何计算当前学生的平均成绩的排名可以通过计算有多少个成绩小于当前学生的成绩再加上1即可得到,如上题目中的:
(select COUNT(AvgScore) from
(select S#,AVG(Score) as 'AvgScore' from SC group by S#) as T1
where T2.AvgScore<T1.AvgScore)+1 as 'Rank'
(25)查询各科成绩前三名的记录:(不考虑成绩并列情况)
1 select sc.C#,c.Cname,sc.S#,s.Sname,sc.Score 2 from Student s,SC sc,Course c 3 where sc.C#=c.C# and sc.S#=s.S# and sc.Score in 4 ( 5 select top 3 Score from SC sc2 6 where sc.C#=sc2.C# 7 Order by Score desc 8 ) 9 order by sc.C#,sc.Score desc
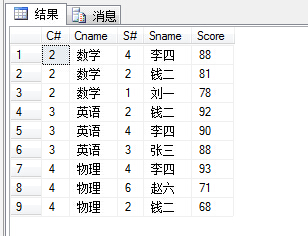
(26)查询每门课程被选修的学生数;
1 select sc.C#,MAX(c.Cname) as 'CName',COUNT(distinct sc.S#) as 'StudentCount' 2 from SC sc,Course c 3 where sc.C#=c.C# 4 group by sc.C#

(27)查询出只选修了一门课程的全部学生的学号和姓名;
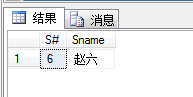
1 select s.S#,s.Sname 2 from Student s 3 where s.S# in 4 ( 5 select sc.S# from SC sc 6 group by sc.S# 7 having COUNT(distinct sc.C#)=1 8 )
这里SC表中没有一个只选了一门课程的学生,可以将语句改为:having COUNT(distinct sc.C#)=2,便可得到以下结果:
(28)查询男生、女生的人数;
1 select COUNT(S#) as 'BoysCount' from Student s where s.Ssex='男' 2 select COUNT(S#) as 'GirlsCount' from Student s where s.Ssex='女'

(29)查询姓“张”的学生名单;
1 select s.S#,s.Sname 2 from Student s 3 where s.Sname like '张%'

(30)查询同名同姓学生名单,并统计同名人数;
1 select s.Sname,COUNT(Sname) as 'SameCount' 2 from Student s 3 group by s.Sname 4 having COUNT(Sname)>1
这里Student表中并没有两个同名同姓的学生信息,因此我们插入一条:{7,钱二,20,女},再执行上面的SQL语句可得以下结果:

(31)查询1981年出生的学生名单(注:Student表中Sage列的类型是datetime) ;
这个题目很怪,明明设计数据库时Sage是int型,这里又是datetime型,我晕死了。故只给出参考答案,我无法执行看结果。
1 select Sname,CONVERT(char (11),DATEPART(year,Sage)) as Age 2 from Student 3 where CONVERT(char(11),DATEPART(year,Sage))='1981';
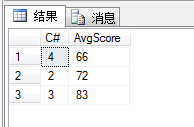
(32)查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列;
1 select sc.C#,AVG(sc.Score) as 'AvgScore' 2 from SC sc 3 group by sc.C# 4 order by AvgScore asc,C# desc
(33)查询平均成绩大于85的所有学生的学号、姓名和平均成绩;
1 select sc.S#,s.Sname,AVG(sc.Score) as 'AvgScore' 2 from Student s,SC sc 3 where s.S#=sc.S# 4 group by sc.S#,s.Sname 5 having AVG(sc.Score)>85

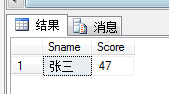
(34)查询课程名称为“数学”,且分数低于60的学生姓名和分数;
1 select s.Sname,sc.Score from Student s,SC sc,Course c 2 where s.S#=sc.S# and sc.C#=c.C# and c.Cname='数学' and sc.Score<60
(35)查询所有学生的选课情况;
1 select s.S#,s.Sname,c.C#,c.Cname from Student s,SC sc,Course c 2 where s.S#=sc.S# and c.C#=sc.C# 3 order by c.C#,s.S#
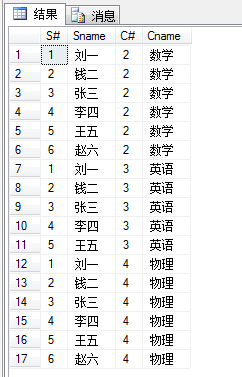
(36)查询任何一门课程成绩在70分以上的姓名、课程名称和分数;
1 select distinct s.S#,s.Sname,c.Cname,sc.Score 2 from Student s,SC sc,Course c 3 where s.S#=sc.S# and sc.C#=c.C# and sc.Score>=70
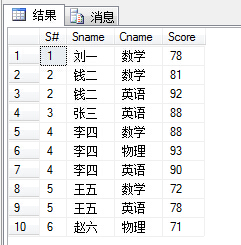
(37)查询不及格的课程,并按课程号从大到小排列;
1 select distinct sc.C#,c.Cname from SC sc,Course c 2 where sc.C#=c.C# and sc.Score<60 3 order by sc.C# desc
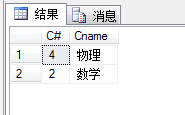
(38)查询课程编号为003且课程成绩在80分以上的学生的学号和姓名;
1 select sc.S#,s.Sname from Student s,SC sc 2 where s.S#=sc.S# and sc.C#='003' and sc.Score>=80

(39)求选了课程的学生人数(超简单的一题)
1 select COUNT(distinct S#) as 'StuCount' from SC
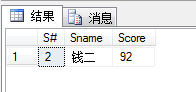
(40)查询选修“杨艳”老师所授课程的学生中,成绩最高的学生姓名及其成绩;
1 select s.S#,s.Sname,sc.Score 2 from Student s,SC sc,Course c,Teacher t 3 where s.S#=sc.S# and sc.C#=c.C# and c.T#=t.T# and t.Tname='杨艳' 4 and sc.Score = 5 ( 6 select MAX(sc2.Score) from SC sc2 7 where sc.C#=sc2.C# 8 )
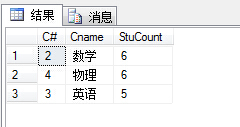
(41)查询各个课程及相应的选修人数;
1 select sc.C#,c.Cname,COUNT(distinct S#) as 'StuCount' from SC sc,Course c 2 where sc.C#=c.C# 3 group by sc.C#,c.Cname
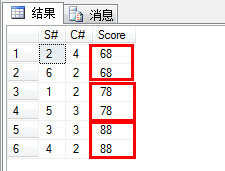
(42)查询不同课程但成绩相同的学生的学号、课程号、学生成绩;
1 select distinct sc1.S#,sc1.C#,sc1.Score from SC sc1,SC sc2 2 where sc1.C#!=sc2.C# and sc1.Score=sc2.Score 3 order by sc1.Score asc
(43)查询每门课程成绩最好的前两名;
1 select sc.C#,c.Cname,sc.S#,s.Sname,sc.Score from Student s,SC sc,Course c 2 where s.S#=sc.S# and sc.C#=c.C# and sc.Score in 3 ( 4 select top 2 sc2.Score from SC sc2 5 where sc2.C#=sc.C# 6 order by sc2.Score desc 7 ) 8 order by sc.C#

(44)统计每门课程的学生选修人数(超过10人的课程才统计)。要求输出课程号和选修人数,查询结果按人数降序排列,查询结果按人数降序排列,若人数相同,按课程号升序排列
1 select sc.C#,COUNT(distinct S#) as 'StuCount' from SC sc 2 group by sc.C# 3 having COUNT(distinct S#)>=10 4 order by StuCount desc,sc.C# asc
因为SC表中并没有超过10人的课程,因此本查询结果为空。
(45)检索至少选修两门课程的学生学号;
1 select distinct sc.S# from SC sc 2 group by sc.S# 3 having COUNT(sc.C#)>=2
SC表中所有的数据都选了超过两门课,因此结果是所有的学号;
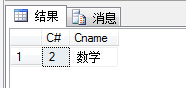
(46)查询全部学生都选修的课程的课程号和课程名;
1 select sc.C#,c.Cname from SC sc,Course c 2 where sc.C#=c.C# 3 group by sc.C#,c.Cname 4 having COUNT(sc.S#)=(select COUNT(distinct s.S#) from Student s)
SC表中插入一条数据{7,2,80},再执行一下上面的SQL语句可以得到下面的结果:
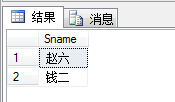
(47)查询没学过“叶平”老师讲授的任一门课程的学生姓名;
1 select s.Sname from Student s where s.S# not in 2 ( 3 select sc.S# from SC sc,Course c,Teacher t 4 where sc.C#=c.C# and c.T#=t.T# and t.Tname='杨艳' 5 )
(48)查询两门以上不及格课程的同学的学号及其平均成绩;
1 select sc.S#,AVG(ISNULL(sc.Score,0)) as 'AvgScore' from SC sc 2 where sc.S# in 3 ( 4 select sc2.S# from SC sc2 5 where sc2.Score<60 6 group by sc2.S# 7 having COUNT(sc2.C#)>2 8 ) 9 group by sc.S#
因SC表中木有两门以上不及格的屌丝,因此查询结果为空;
(49)检索“004”课程分数小于60,按分数降序排列的同学学号;(很简单的一题)
1 select sc.S# from SC sc 2 where sc.C#='004' and sc.Score<60 3 order by sc.Score desc
查询结果:S#为1,3,5
(50)删除“002”同学的“001”课程的成绩;(很简单的一题)
delete from SC where S#='002' and C#='001'
二、练习总结
本篇是从Cat Qi的原文《SQL面试题(学生表-教师表-课程表-选课表)》中摘抄的,前半部分难度较大,后半部分难度减小,经过我一题一题的练习,也还是得到了很大的锻炼。下一篇Part 2,将针对另外两个类型的题目,我暂时取名为“书到用时方恨少:图书-读者-借阅”类题目,这一类题目也是非常常见的题目,大概会有15个题目左右。
参考原帖
(1)Cat Qi,《SQL面试题(学生表-教师表-课程表-选课表)》:http://www.cnblogs.com/qixuejia/p/3637735.html
(2)CSDN,《找些不错的SQL面试题》讨论帖,http://bbs.csdn.net/topics/280002741


 浙公网安备 33010602011771号
浙公网安备 33010602011771号