
AI应用实战课学习总结(4)医疗数据可视化
 今天是我们的第4站,了解经典的乳腺癌医疗数据集,并基于该数据集使用Matplotlib和Seaborn做了一些常见的数据可视化图的绘制,有了这些图可以帮助我们做数据分析。
今天是我们的第4站,了解经典的乳腺癌医疗数据集,并基于该数据集使用Matplotlib和Seaborn做了一些常见的数据可视化图的绘制,有了这些图可以帮助我们做数据分析。
大家好,我是Edison。
最近入坑黄佳老师的《AI应用实战课》,记录下我的学习之旅,也算是总结回顾。
今天是我们的第4站,通过一个经典的医疗数据集来进行数据可视化的实战。
数据集介绍
这是一个从UCI网站(https//archive.ics.uci.edu/ml/index.php)获取的美国威斯康辛州的乳腺癌数据集,它包括了一些对乳腺细胞测量之后的特征数据(如厚度、大小等)和标签数据(诊断结果:良性or恶性),现经常被拿来做机器学习分类算法的入门教学。
下面就是该数据集所有的数据字段的介绍:
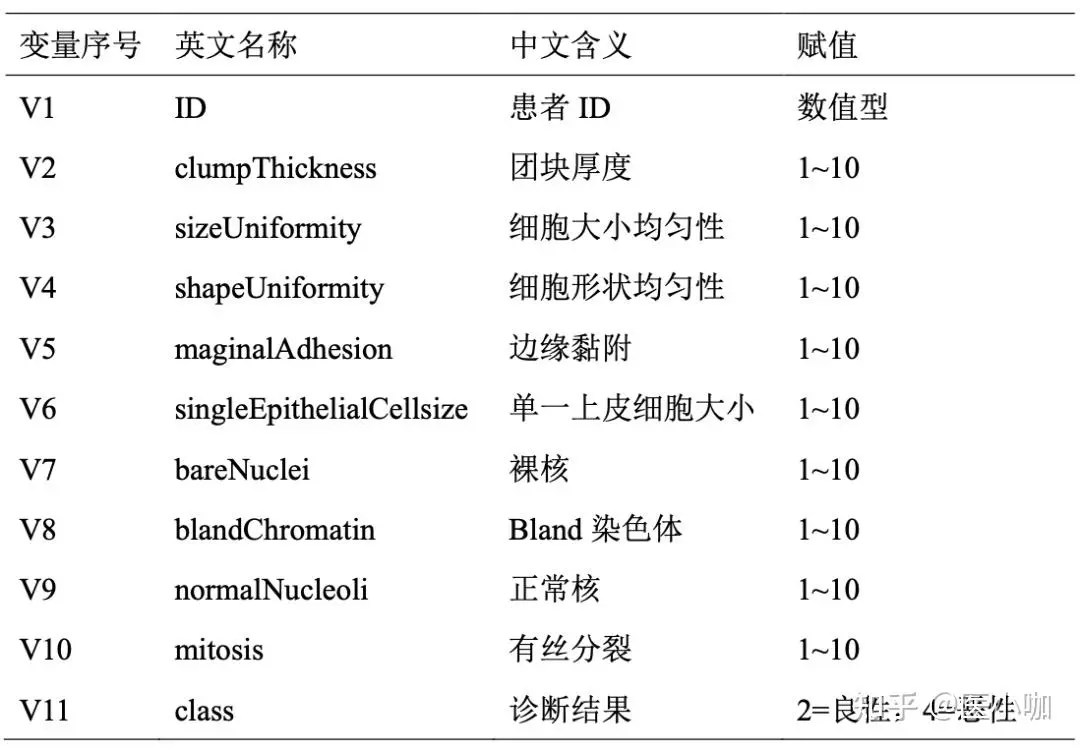
该数据集大约有569个样本,它的良性(健康)数据样本 和 恶性(确诊)数据样本相对来说是比较平均的(良性357个,恶性212个)。
针对该数据集,我们可以使用Matplotlib和Seaborn等可视化库快速做一些数据可视化的操作,帮助我们进行数据分析。
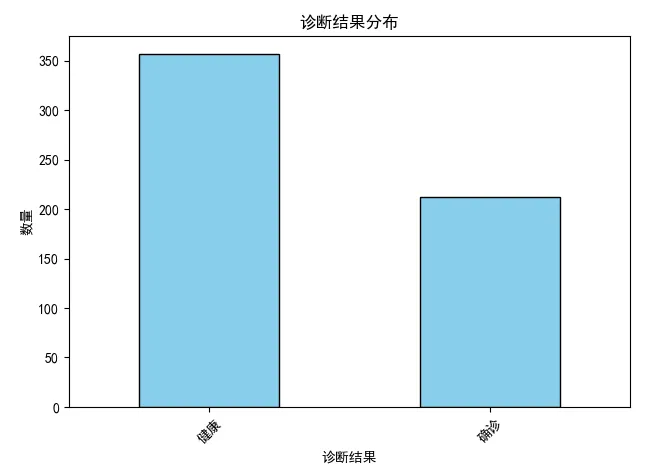
例如,我们可以对诊断结果做标签数据分布的柱状图,就可以快速知道良性和恶性的人数都有多少。
接下来,我们就来基于Python+可视化库来实现一下。
数据可视化实战
Step1 读取数据,设置特征 和 标签
import pandas as pd # 导入Pandas数据处理工具 # 读取数据 data = pd.read_csv('medical-data-demo.csv') data.head() # head方法显示前5行数

# 设置X(特征)和y(标签) y = data["诊断结果"] X = data.drop(["诊断结果", "ID"], axis=1) X

Step2 诊断结果分布柱状图(基于matplotlib)
import matplotlib.pyplot as plt # 设置字体为SimHei,以正常显示中文标签 plt.rcParams["font.family"]=['SimHei'] plt.rcParams['font.sans-serif']=['SimHei'] # 设置正常显示负号 plt.rcParams['axes.unicode_minus']=False # 通过柱状图显示y(诊断结果)的分布 y.value_counts().plot(kind='bar', color='skyblue', edgecolor='black') plt.title('诊断结果分布') plt.xlabel('诊断结果') plt.ylabel('数量') plt.xticks(rotation=45) plt.tight_layout() plt.show()
效果如下图:
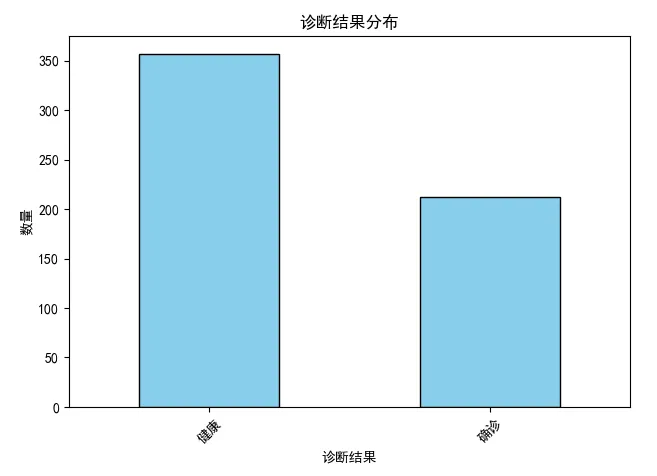
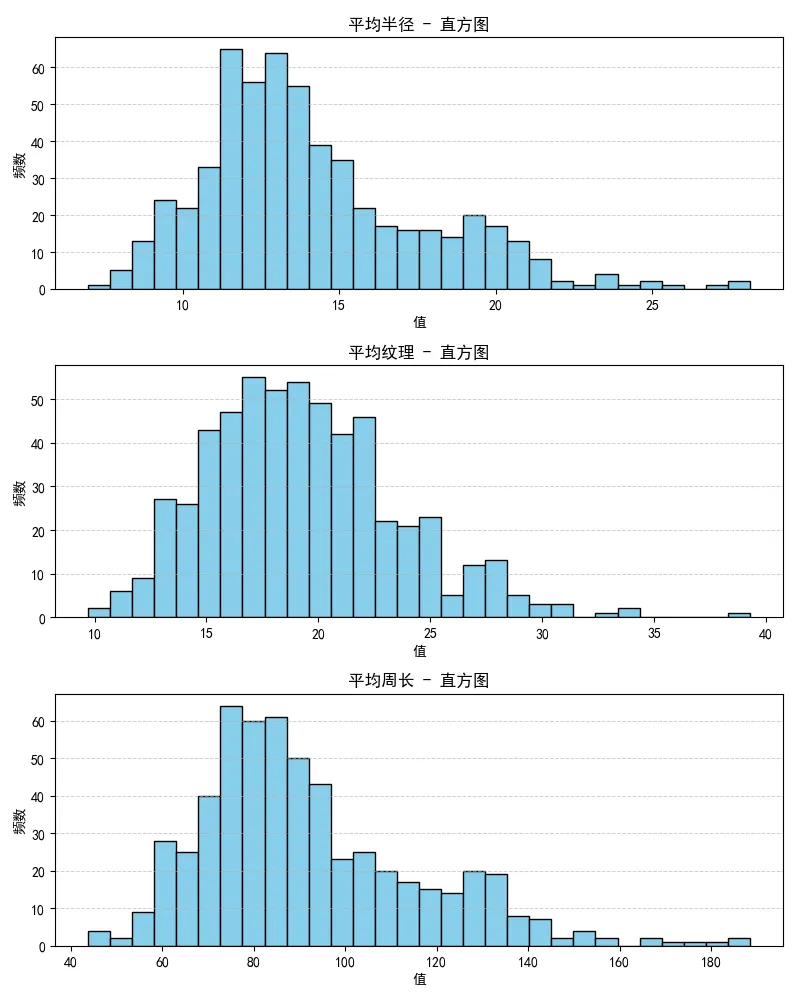
Step3 某些特征的直方图
# 显示特征数据集的统计信息 X.describe()
即可得到每个特征的最大、最小值、平均值、四分位、中位数等统计信息:

# 查看X的特征名称 features = X.columns # 绘制前三个特征的直方图 first_three_features = features[:3] # 设置画布和子图,这里是三个子图 fig, axes = plt.subplots(nrows=3, ncols=1, figsize=(8, 10)) # 依次设置三个子图的属性 for i, feature in enumerate(first_three_features): axes[i].hist(X[feature], bins=30, color='skyblue', edgecolor='black') axes[i].set_title(f"{feature} - 直方图") axes[i].set_xlabel('值') axes[i].set_ylabel('频数') axes[i].grid(True, axis='y', linestyle='--', linewidth=0.7, alpha=0.6) plt.tight_layout() plt.show()
前三个特征(平均半径、平均纹理和平均周长)的直方图效果如下:
Step4 部分特征的箱线图
箱线图是一种非常有用的统计工具,主要用于展示一组数据的分布情况。它不仅能反映数据的集中程度,还能展示数据的离散程度。简单来说,箱线图就是用来告诉你:你的数据分布是什么样的,以及它们是如何变化的。
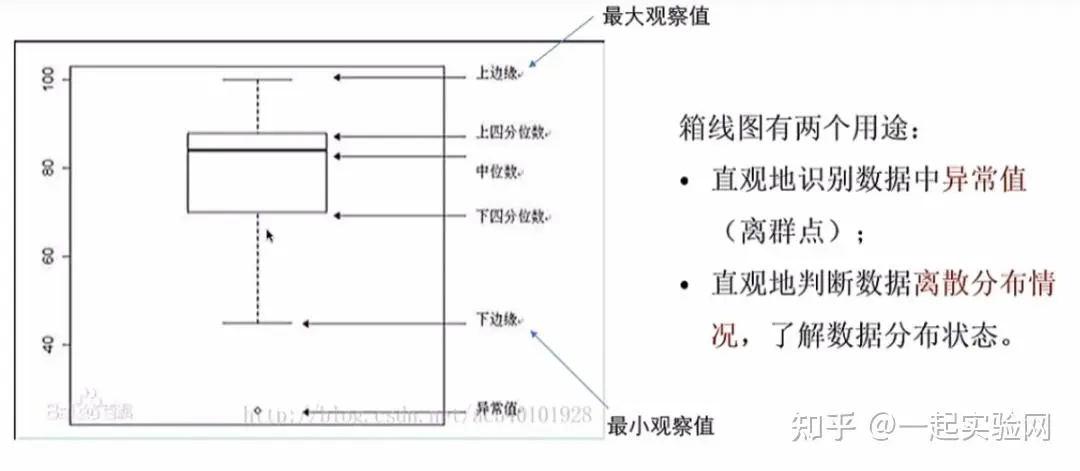
首先,先做一下数据的标准化:
from sklearn.preprocessing import StandardScaler # Setting X and y y = data["诊断结果"] X = data.drop(["诊断结果", "ID"], axis=1) # Selecting the first 10 features selected_features = X.columns[:10] # Standardizing X scaler = StandardScaler() X_standardized = scaler.fit_transform(X) # Extracting the standardized values of the selected features X_selected_standardized = X_standardized[:, :10]
然后,绘制箱线图:
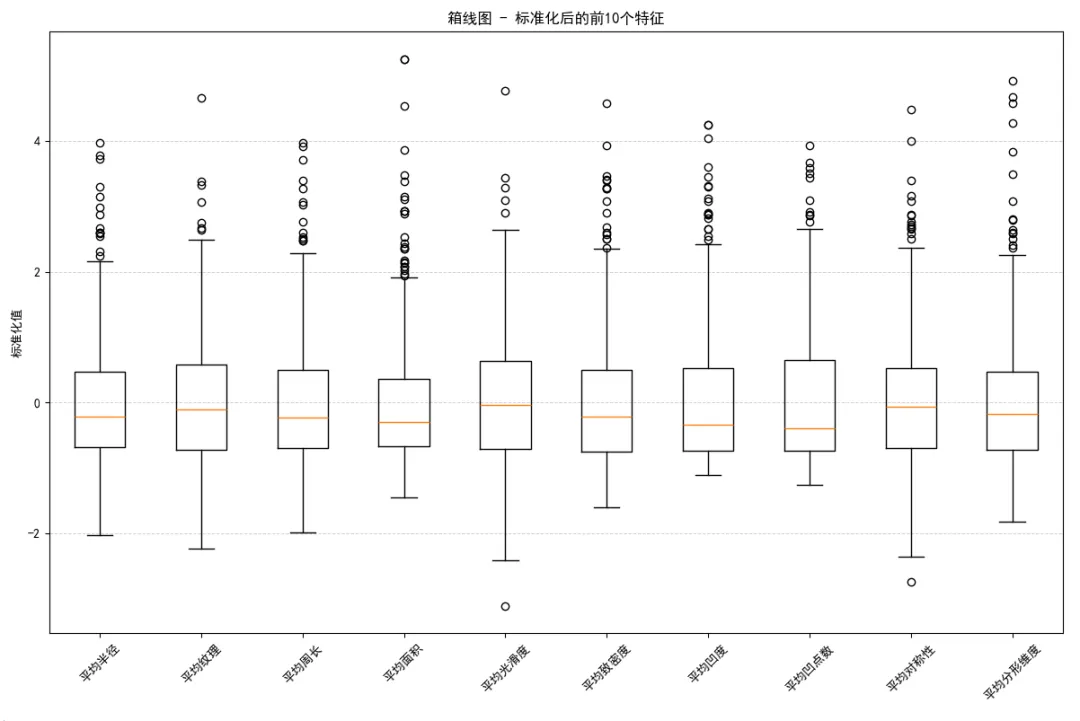
# Plotting the boxplot for the standardized values of the selected features import matplotlib.pyplot as plt # Setting the font for displaying Chinese characters in the plot plt.rcParams["font.family"]=['SimHei'] plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False plt.figure(figsize=(12, 8)) plt.boxplot(X_selected_standardized, vert=True) plt.xticks(range(1, len(selected_features) + 1), selected_features, rotation=45) plt.title('箱线图 - 标准化后的前10个特征') plt.ylabel('标准化值') plt.grid(True, axis='y', linestyle='--', linewidth=0.7, alpha=0.6) plt.tight_layout() plt.show()
得到的标准化后的前10个特征的箱线图如下:
Step5 部分特征的小提琴图
小提琴图和箱线图类似,用来显示数据分布和概率密度。结合了箱线图和密度图的特征,用来显示数据的分布形状。
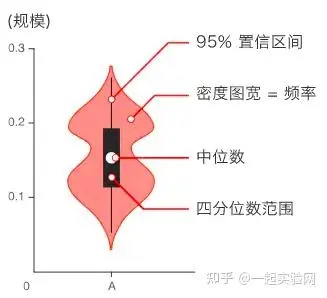
要绘制小提琴图,就需要使用Seaborn了,Matplotlib就没法支持了。同样,需要先做数据的标准化之后,再来绘制。
import seaborn as sns # 导入Seaborn # 绘制小提琴图 plt.figure(figsize=(12, 8)) sns.violinplot(data=pd.DataFrame(X_selected_standardized, columns=selected_features), palette="Set3") plt.title('小提琴图 - 标准化后的前10个特征') plt.ylabel('标准化值') plt.xticks(rotation=45) plt.tight_layout() plt.show()
得到的标准化后的前10个特征的小提琴图如下:

箱线图和小提琴图的差异:小提琴图可以看出数据分布密度,箱线图看不出来。
Step6 部分特征的相关性热图
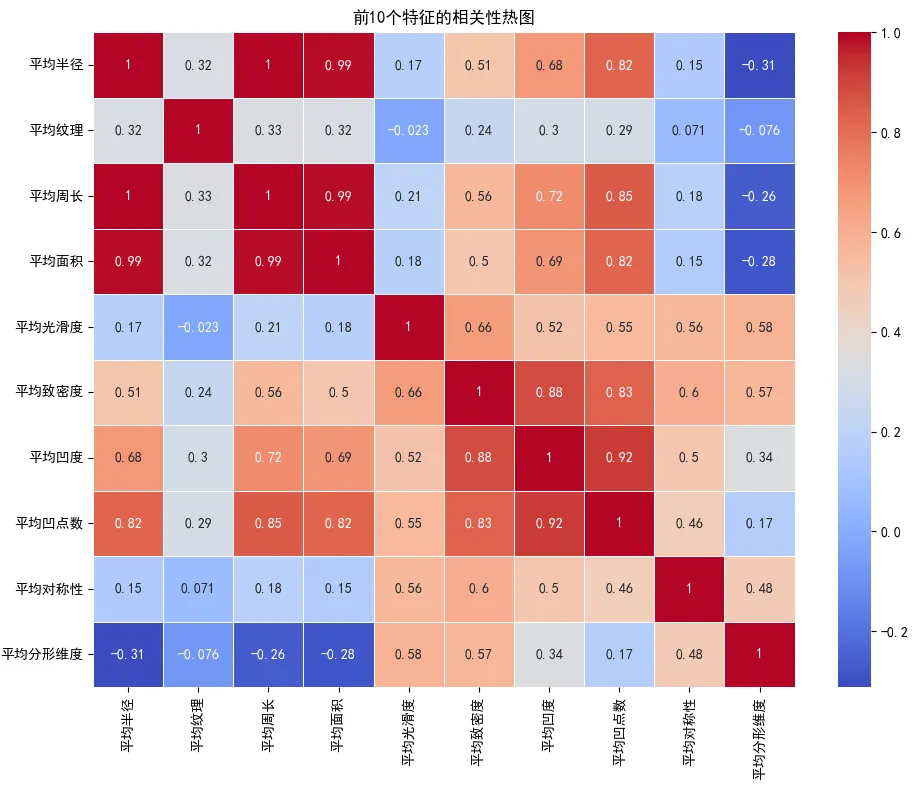
相关性热图作为一种可视化工具,可直观地展现两个或多个变量之间的相关性强度。在热图的呈现中,通过矩阵的形式展示数据集中各变量之间的相关性,其中每个单元格代表两个变量之间的相关性系数,并以颜色深浅来直观表示相关性的强弱。常用皮尔逊相关系数来衡量,该系数的取值范围在-1到1之间,其中-1表示完全负相关,1表示完全正相关,0表示无线性相关。
这种可视化方式不仅有助于我们迅速捕捉数据集中的潜在关联规律,还能为后续的数据分析和建模工作提供有力的指导。
绘制相关性热图,仍然使用Seaborn来绘制:
# 绘制相关性热图 correlation_matrix = pd.DataFrame(X_selected_standardized, columns=selected_features).corr() # 得到相关性矩阵 plt.figure(figsize=(10, 8)) sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', linewidths=0.5) plt.title('前10个特征的相关性热图') plt.tight_layout() plt.show()
得到的标准化后的前10个特征的相关性热图如下:
小结
本文介绍了经典的乳腺癌医疗数据集,并基于该数据集使用Matplotlib和Seaborn做了一些常见的数据可视化图的绘制,有了这些图可以帮助我们做数据分析。
推荐学习
黄佳,《AI应用实战课》(课程)

黄佳,《图解GPT:大模型是如何构建的》(图书)
黄佳,《动手做AI Agent》(图书)


