
大模型应用开发基础 : 语言模型的关键思路跃迁
 本文简单介绍了语言模型的发展脉络,特别介绍了其发展过程中的关键思路变迁,即从基于规则的方法到基于统计的方法。由于基于统计和数学的方法具有较高的扩展性和自适应性,它逐渐形成了目前业界主流的NLP处理方法。
本文简单介绍了语言模型的发展脉络,特别介绍了其发展过程中的关键思路变迁,即从基于规则的方法到基于统计的方法。由于基于统计和数学的方法具有较高的扩展性和自适应性,它逐渐形成了目前业界主流的NLP处理方法。
大家好,我是Edison。
最近学习了一门公开课:黄佳老师的《ChatGPT和预训练模型实战课》,温习了ChatGPT的基本原理和语言模型的发展脉络,受益匪浅。老规矩,必须把自己学到的整理一下,才算学过。这一篇我们了解下语言模型的关键转变:从基于规则 到 基于统计 的思路跃迁。
语言是什么?
我们常常说大语言模型(LLM),那么语言到底是什么?语言是信息的载体,承载着沟通的信息,无论是中文,英文,亦或是甲骨文,没有语言,人与人就无法沟通。
语言模型是什么?
对于一个语言模型,它本质上是信息编码 和 解码 的通道,如下图所示:

信息的发送人将想要发送的信息进行编码,然后信息通过信道进行解码,传递给信息的接收人。
例如,一个只说英文的英国人面对一个没有接受过英文教育的中国人,虽然他们都有语言,但是他们不能相互解码,也就无法沟通。
同理,计算机也无法直接理解我们人类的语言,从这个通信模型我们可以看出,它缺少编解码的过程。
那么,ChatGPT是怎么理解人类的语言的呢?这其实就是NLP(自然语言处理)的核心任务,即为自然语言进行编码和解码,进而让计算机和AI都能理解人类的语言。
语言模型的进化
语言模型从大体上来讲,它大概经历了如下图所示的四个阶段,从起源、基于规则 到 基于统计 再到 目前主流的深度学习,语言模型的进化驱动着NLP技术的发展:
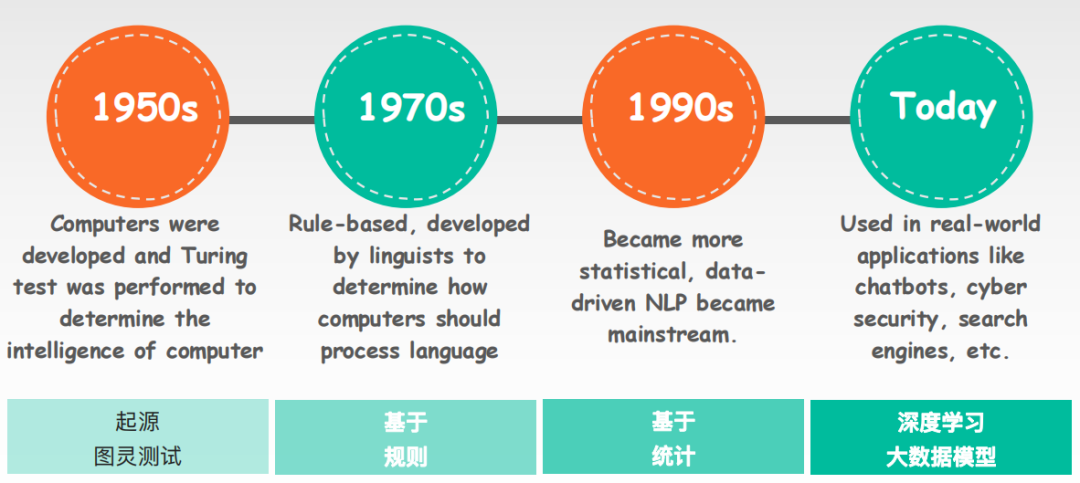
(1)起源:NLP起源可以追溯到19世纪的50年代,计算机科学之父阿兰图灵发表了计算机器与智能的论文,提出了图灵测试的概念。所谓图灵测试,就是指当AI和你对话的时候,如果你无法判断跟你对话的是AI还是人类,那么对于这个AI来说,就算它是通过了图灵测试,也就是拥有了基础的智能。
画外音:你看图灵测试其实就是一个NLP任务!
(2)基于规则:在图灵测试之后的20年间即1950~1970,科学家们开始通过基于语义和语法规则的方法来解决NLP问题。这种方法它受限于规则的数量和复杂性,它没有办法涵盖所有的语言现象的,因为人类的自然语言规则太复杂了。
(3)基于统计:在基于规则的研究热潮之后即1970~1990,科学家们发现基于统计的方法来解决NLP问题更好用,他们将统计方法应用于解决语音识别的问题。这就实现了将一个基于逻辑规则的问题 转换为 一个数学问题,也就使得NLP任务的准确率得到了本质上的提升。
画外音:至此计算机业界领悟到,基于统计方法才是一条正确的道路,基于规则的方法是行不通的。
(4)深度学习:在1990年至今的几十年里,在确定了以基于统计的基本方法背景下,通过深度学习技术和大数据技术的发展下,数据驱动NLP就成为了主流。这种方法主要通过深度神经网络以及其他各种机器学习技术,来处理海量的自然语言数据,从而让模型学习到大量语料库背后的复杂结构和规律。
画外音:现在很多大型预训练语言模型在很多NLP任务上的表现其实已经超过了人类,也就可以帮助我们解决很多实际的问题,比如语音识别、文本分类、自然语言文本生成等等。
总结:语言模型的进化驱动着NLP技术的发展,其中的关键就在于从基于规则的方法到基于统计的方法这个思路的跃迁。
基于规则的语言模型
基于规则的语言模型并不简单,语言模型中的句法分析这一块内容,它就需要考虑句子的句法结构,可能就需要先将句子进行分析然后处理成机器可读的格式。在句子不多且数据量很少的时候,这种方法可能可行,即通过主谓宾定状补这样分析一下。
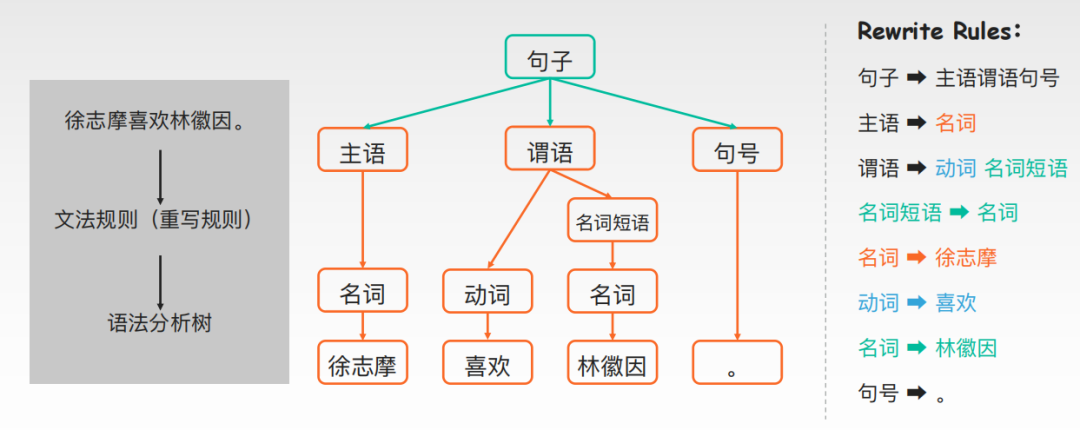
但是,实际上语言其实是非常复杂的,完全没有我们想象中的那么简单,这种方法是看上去很美,实际上不可行。
例如,“徐志摩喜欢林徽因”这句话,机器就需要根据8条规则来进行句法分析,而且这些规则全部需要人工编写,会导致高昂的人力成本,而且很容易出现规则和规则之间的矛盾。而即使我们花费了大量力气来编写这些规则,像刚刚这句话也最多就能套用在另一句跟其很相似的如“爱迪生喜欢博客园”这种格式的句子而已,换句话说,它在于我们应用于其他的各种各样的语言格式的时候,它并不好用!
基于统计的语言模型
正是因为基于规则的方法并不好用,人们才开始逐渐发现基于统计的语言模型才是正道。
所谓基于统计的语言模型,就是为自然语言上下文相关的这种特性建立数学模型。
详细来说,它是基于统计学和概率学的自然语言处理技术,通过分析大量的语言数据,来推断和预测语言现象,为自然语言上下文的相关性来建立数学模型。
例如,假设我们有如下一些词语(以空格分隔):

对于我们人类来说,我们可以很容易就从这些词语中来组成一个合理的句子,因为这本就是我们人类的语言,我们可以一眼就看出。但是,对于计算机或AI来说,这并不容易。这其实就是一个NLP任务,在基于统计的语言模型中,它可能就会通过尝试组成多个句子(不管正不正确),然后再基于统计给这几个句子进行打分,最终选出打分最高的那个,而这个句子就越有可能是正确的合理的句子。

IBM科学家贾里尼克的经典假设:一个句子是否合理,取决于其出现在自然语言中的可能性的大小。
那么,计算机或AI之所以能够判断某个句子比某个句子好,其实是因为它读过大量的自然语言的语料,见多识广。它就发现,当它看到第二个句子出现的概率在它过去看到过的这些句子里边概率比较高,所以它就认为,既然概率更高,那么第二个句子就更像是一个正确的句子。
然后,这个概率又是怎么计算出来的呢?假设S表示一个有意义的句子(Sentense),它是由一连串按照特定顺序排列的词如W1,W2,...,Wn组成。那么,这个概率就是:求S在文本中出现的可能性,即P(S)。(P表示Probability即可能性)
例如,当人类开口说出第一个词是“你”,由于大模型已经统计过人类有史以来所有的句子了,它就发现只要人类开口第一个字出现的是“你”这个字的概率大概是万分之一,根据条件概率公式,在第一个词“你”出现的情况下,它会计算下一个词出现频率最高的是哪一个词,它可能就会下一个词是“好”的概率在它见识过的语料库中可能高达80%。然后,以此类推后续的生成,比如第三个词可能是“吗”,然后将这一整个句子所有的概率全部都乘起来就形成了这一个句子到底是不是一个正确句子的概率,例如“你好吗?”这个句子的概率 就比 “吗你好”的概率要高。
为了简化模型,数学家马尔科夫的经典假设:任意一个词出现的概率只同它前面的那一个词有关。虽然这个假设不一定完全正确,但却实实在在地简化了语言模型的复杂度,就不需要计算很多很多的这个值的条件概率。换句话说,语言模型只需要每次看两个词,计算概率时每次只看它上一个词就可以把概率语言模型换成一个二元模型,即就看两个词在它见识过的大量语料库中前后一块出现的概率即可,一直到最后一个词和上一个词一起出现过的概率。而把这些所得的概率一起相乘之后,也就得到了一个整句的句子它是否是一个正确的句子的概率。

相信你已经了解,这就是基于统计的语言模型的概率计算。
基于统计的语言模型它的优点主要在于具有扩展性,由于它可以处理很大规模的文本和数据集,就可以扩展到更广泛的语言任务和环境中。此外,它还具有自适应性,即能够从实际语料库中自适应的学习语言的规律和模式,因为人类已经有大量的语料库可以给到模型让它自己去计算和统计,进而得到训练。
因此,基于统计和数学的方法进行语言建模就形成了目前业界的主流方法。
小结
本文简单介绍了语言模型的发展脉络,特别介绍了其发展过程中的关键思路变迁,即从基于规则的方法到基于统计的方法。由于基于统计和数学的方法具有较高的扩展性和自适应性,它逐渐形成了目前业界主流的NLP处理方法。
推荐学习
黄佳,《ChatGPT和预训练模型实战课》
产品二姐,《成为AGI产品经理》


