
AI应用实战课学习总结(12)Transformer
 本文介绍了Transformer的基本概念和架构,它相对于RNN的优势主要就在于自注意力机制,实现了并行性和可扩展性,进而催生了GPT等大语言模型的诞生。目前我们可以通过对预训练好的大语言模型进行微调,进而让其适应我们的业务任务,节省资源又能保证质量。
本文介绍了Transformer的基本概念和架构,它相对于RNN的优势主要就在于自注意力机制,实现了并行性和可扩展性,进而催生了GPT等大语言模型的诞生。目前我们可以通过对预训练好的大语言模型进行微调,进而让其适应我们的业务任务,节省资源又能保证质量。
大家好,我是Edison。
最近入坑黄佳老师的《AI应用实战课》,记录下我的学习之旅,也算是总结回顾。
今天是我们的第12站也是最后一站,一起了解下在DNN/CNN/RNN之后横空出世的Transformer,作为大语言模型的基础架构,它到底有什么样的优势?
从CNN到Transformer
在之前的两篇内容中,我们了解了深度学习和基于CNN发展出来的神经网络模型如RNN等,经过了多年的发展,现在已经发展到了Transformer,突破了自然语言处理的瓶颈,从而真正开始能够理解语言然后开始和人类聊天对话。
Transformer也是一种深度学习模型,具有Encoder(编码器)和 Decoder(解码器)的架构,有的模型只用了Encoder(如BERT),有的模型只用了Decoder(如GPT),还有的模型Encoder和Decoder都有使用到(如T5)。
它最初是为了解决从序列到序列(Seq2Seq)的任务,比如说机器翻译,它先给语言做一个编码,然后再解码,就能够实现完成这个机器的翻译。

Transformer架构中最核心的内容就是引入了自注意力机制,通过自注意力和多头自注意力机制实现了并行处理,通过多层具有自注意机制的网络层叠加来实现模式的学习,进而大幅提高了处理效率。
从Transformer演化出了GPT,或者说GPT是基于Transformer的一个自回归的模型,它只用到了Transformer的Decoder(解码器)。所谓自回归任务,就是专注于预测序列中的下一个字(严谨点说是Token),如下图所示:
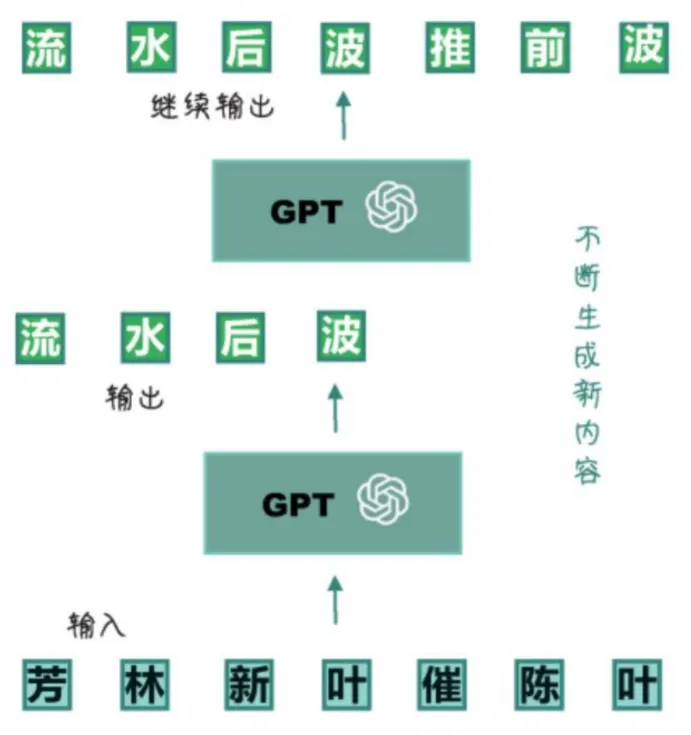
GPT通过自回归模型进行预训练,在进行预训练的时候,模型会被输入大量的文本数据,然后开始预测每一个词的下一个词,如此往复,直到整个句子说的差不多了,不断生成新内容。通过这种方式,GPT学习到了语言规律、语法、词法、词汇搭配等等,然后生成的都是自然流畅的文本。


Transformer为何有效?
还记得上一篇RNN中举得例子吗?老师给学生传纸条,一个学生看一个字,再通过Hidden节点将前面的字记下来,这是一种非常低效的记忆方式。

在Transformer中,则是通过自注意力机制并行计算互相注意的方式实现高效便捷的处理,进而将编码器和解码器串联起来。
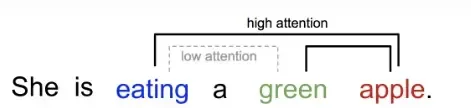
因此,Transformer相较于RNN更加有效的原因在于:
(1)自注意力机制
Transformer会将整个序列一次性导入,并将整个序列中的元素分配不同的注意力权重。换句话说,在考虑上下文时为每一个单词(严格来说是Token)都分配一个适当的重要性,这就可以让模型可以在一个序列中捕捉长距离的依赖关系。而这个依赖关系,其实就可以帮助模型理解句子中的各种语法和语义的模式。
如下图所示,当聚焦到前面一列头部的某个 Token 时,它会在后面一列(也是同一个句子中的 Token 序列)找到与该 Token 更相关的其它 Token,或者可以说句子中的每个 Token 都与前面当前所聚焦 Token 有一个相关数值,值越大表示越相关,对应的注意力权重也越大。当然,同一个 Token 与它自己最相关,通常相关值最大。

(2)多头注意力
所谓多头注意力就是指它不仅仅一组一组地寻找注意力,而是融合多个注意力,进而学到更多的行为。人类的语言非常微妙,一个句子可能有多种含义,因此只找一组是不够的。
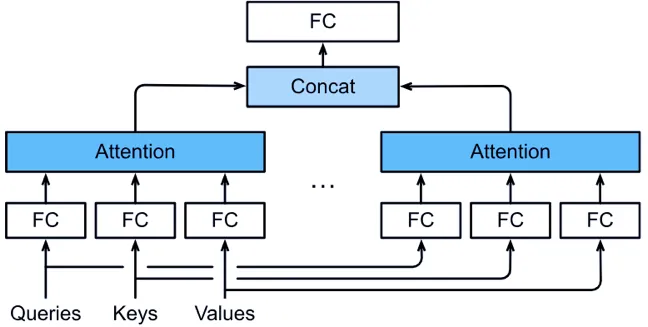
比如,在机器翻译任务中,使用多头注意力能够学习并捕捉到输入序列中的不同类型信息:一个注意力头可能学习句子的语法结构,而另一个注意力头可能学习句子中的于语义信息,这样更有利于模型生成准确、自然的翻译结果,从而提高了模型的性能。
(3)并行性和可扩展性
因为Transformer是并行处理本身具有并行性,因此可以通过简单地增加它的层数,隐藏单元数或者注意力的头数,实现可扩展性,获得更好的处理效率。
大语言模型的训练方式
不同的大语言模型使用了不同的预训练方式,这里以BERT和GPT为例说明:
BERT采取的是 抠字完形填空 的方式:

如果模型猜对了,损失函数就低,相反损失函数就高。因此,通过这种猜词的方式调整参数,慢慢让其形成猜词能力。猜词这种方式是双向关注,而下面GPT是单项关注。
GPT采取的是 猜测下一句 的方式:

如上图,如果生成的准确,损失函数就低,相反损失函数就大,慢慢调参形成下个句子的预测能力。
大语言模型的使用方式
目前主流的大语言模型的使用方式为:预训练 + 微调。
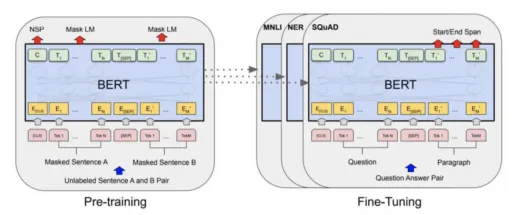
预训练 (Pre-Training) 相当于盖一座房子的地基和框架,经过预训练之后的大语言模型通常称为基线模型(Base Model)。
微调(Fine-Tuning)则相当于根据业务需求做精装修,借助基线模型我们不用每次都从做起,只需要用少量的特定业务场景的领域数据进行二次训练或迁移训练,使其适应具体业务任务即可。
通过结合预训练和微调,既节省训练资源又能专业化应用。
小结
本文介绍了Transformer的基本概念和架构,它相对于RNN的优势主要就在于自注意力机制,实现了并行性和可扩展性,进而催生了GPT等大语言模型的诞生。
目前我们可以通过对预训练好的大语言模型进行微调,进而让其适应我们的业务任务,节省资源又能保证质量。
参考文章
简单之美,《理解注意力机制》
CoCoML,《详解深度学习中的“注意力机制”》
推荐学习
黄佳,《AI应用实战课》(课程)

黄佳,《图解GPT:大模型是如何构建的》(图书)
黄佳,《动手做AI Agent》(图书)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号