
大模型应用开发初探 : 快速直观感受RAG
 检索增强生成(Retrieval Augmented Generation),简称 RAG,它是根据用户输入的提示词,通过自有垂域数据库检索相关信息,然后合并成为一个新的“完备的“提示词,最后再给大模型生成较为准确的回答。这一篇,我们来快速了解下RAG(检索增强生成)并通过一个简单的DEMO来直观感受一下它的作用。
检索增强生成(Retrieval Augmented Generation),简称 RAG,它是根据用户输入的提示词,通过自有垂域数据库检索相关信息,然后合并成为一个新的“完备的“提示词,最后再给大模型生成较为准确的回答。这一篇,我们来快速了解下RAG(检索增强生成)并通过一个简单的DEMO来直观感受一下它的作用。
大家好,我是Edison。
上一篇,我们了解了什么如何让一些开源小参数量模型具有函数调用的能力。这一篇,我们来快速了解下RAG(检索增强生成)并通过一个简单的DEMO来直观感受一下它的作用。
RAG是什么?
检索增强生成(Retrieval Augmented Generation),简称 RAG,它是根据用户输入的提示词,通过自有垂域数据库检索相关信息,然后合并成为一个新的“完备的“提示词,最后再给大模型生成较为准确的回答。

例如,假设你正在构建问答聊天机器人,以帮助员工回答有关公司专有文档的问题。如果没有专门的培训,独立的 LLM 将无法准确回答有关这些文档的内容的问题,因为这些 LLM 都是基于互联网上公开的数据训练的。LLM 可能会因为缺乏信息而拒绝回答,或者更糟的是,它可能会生成不正确的响应。
为了解决这个问题,RAG 首先根据用户的查询从公司文档检索相关信息,然后将检索到的信息作为额外的上下文提供给 LLM。这样,LLM 就可以根据在相关文档中找到的特定详细信息生成更准确的响应。从本质上讲,RAG 使 LLM 能够“咨询”检索到的信息来表述其答案。
一般的RAG工作流程如下图所示,它实现了 非参数事实知识 和 逻辑推理能力 的解耦或分离,这些事实知识存储在外部知识库中独立管理和更新,确保LLM能够访问到就行。
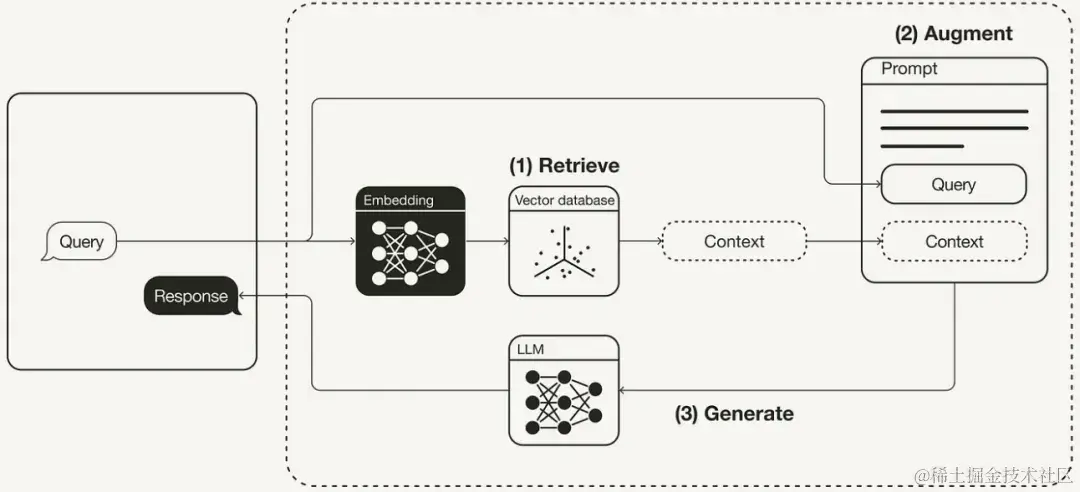
综上所述,RAG其实类似于大学期末的开卷考试,反正知识点都在书里,你平时都没学过,得先找一找,找到了就把相关答案写在试卷上,考完了还是忘得一干二净,但是你的目标达到了:考试及格60分万岁!对于LLM来说,它完成了任务,给你了一个至少可以有60分的回答。下面总结下:
- 检索(Retrieve):根据用户提示词从知识库中获取相关知识上下文。
- 增强(Augment):将用户的原始提示词 和 获取到的知识 进行合并,形成一个新的提示词。
- 生成(Generate):将增强后的新提示词发给LLM进行输出。
直观感受RAG
这里我们就不深究RAG的更多细节内容了,先来通过一个DEMO直观感受下RAG到底有什么作用。至于那些更多的细节内容,留到后续学习实践后,再总结分享。
这仍然是一个WindowsForm的DEMO应用,界面如下:
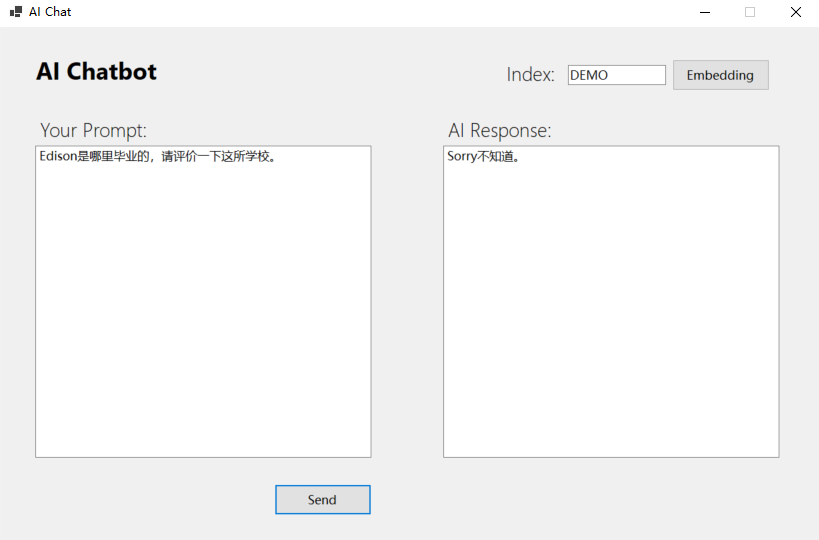
(1)在没有使用RAG时的查询
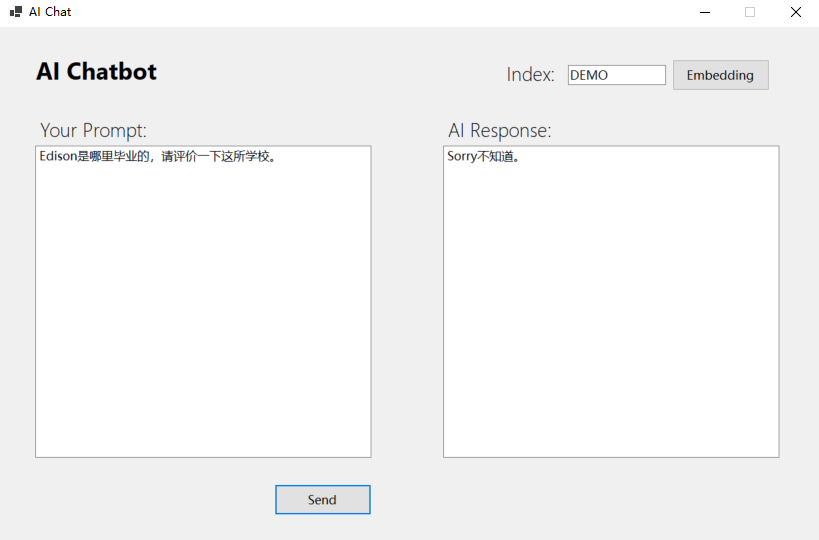
(2)使用RAG:导入内部知识
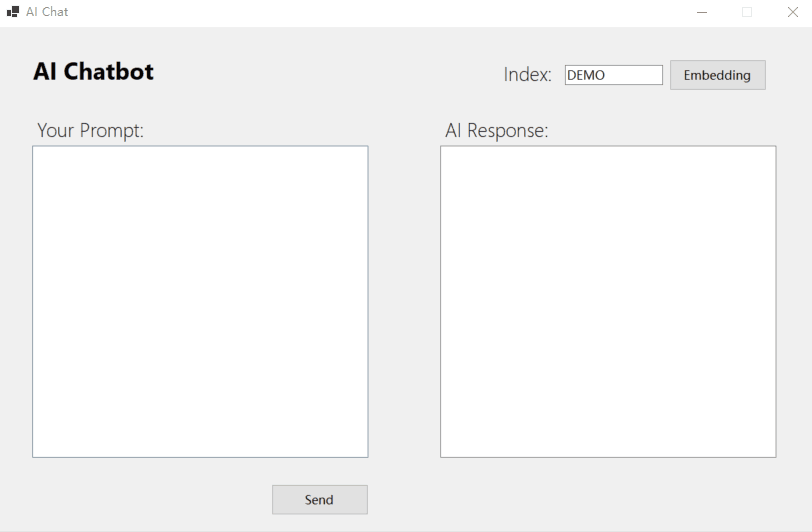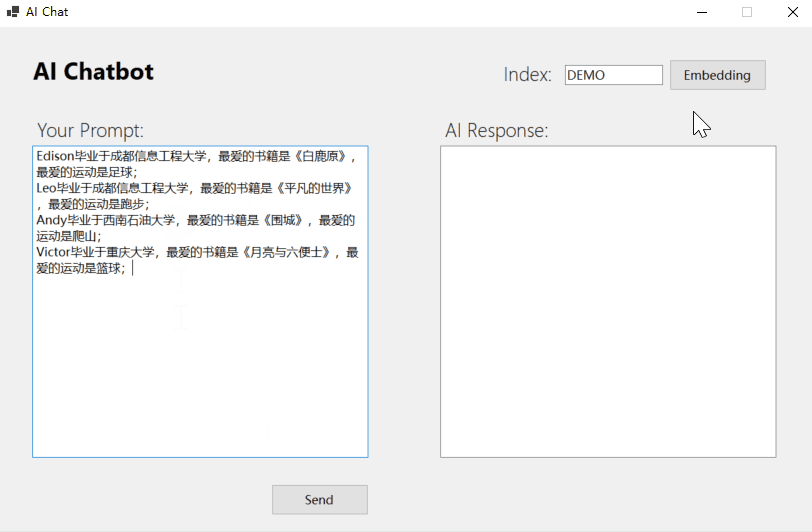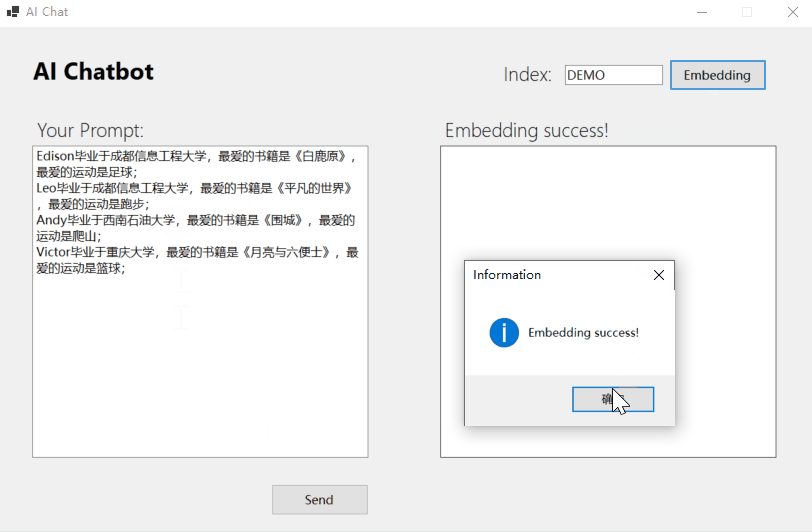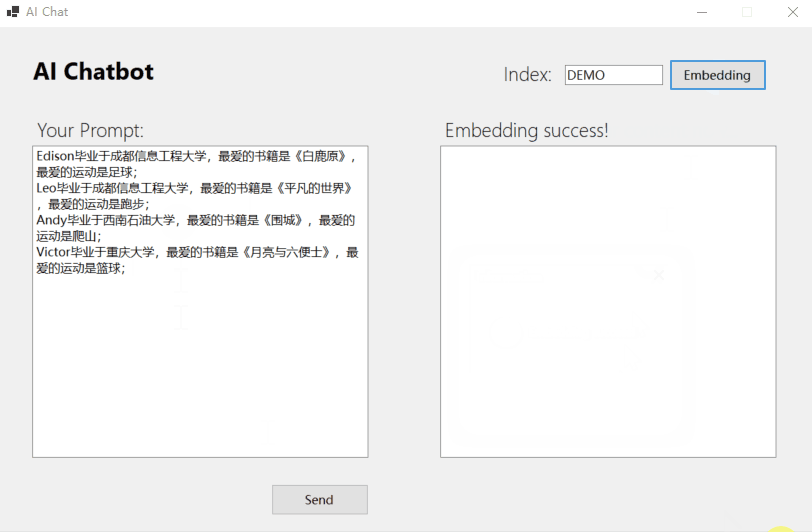
(3)使用RAG:检索增强查询


可以看到,基于导入的内部知识,LLM能够基于RAG获得这些知识片段,然后结合用户的问题 和 知识片段 来生成较为准确的答案。
DEMO要点
(1)配置文件
DEMO中LLM使用的是Qwen2-7B-Instruct的模型,Embedding使用的是bge-m3模型,具体的配置如下:
{ "OpenAI": { "API_PROVIDER": "SiliconCloud", "API_CHATTING_MODEL": "Qwen/Qwen2-7B-Instruct", "API_EMBEDDING_MODEL": "BAAI/bge-m3", "API_BASE_URL": "https://api.siliconflow.cn", "API_KEY": "**********************" // Update this value to yours }, "TextChunker": { "LinesToken": 100, "ParagraphsToken": 1000 } }
(2)使用组件
使用到的组件包主要有两个:
-
Microsoft.SemanticKernel 1.19.0
-
Microsoft.SemanticKernel.Connectors.OpenAI 1.19.0
-
Microsoft.SemanticKernel.Connectors.Sqlite 1.19.0-alpha
可以看到这里使用的是一个本地数据Sqlilte来作为向量数据库存储,因为我们这个仅仅是个快速的DEMO,实际中可能会考虑选择更为适合的DB。需要注意的是,这里Sqlite这个包是个预览版,你在Nuget管理器中需要注意下勾选包含预览版才能搜索得到。
也正因为这个预览版,很多用法都有警告提示,所以最好在代码中加上下面这些将其禁用掉:
#pragma warning disable SKEXP0050 #pragma warning disable SKEXP0001 #pragma warning disable SKEXP0020 #pragma warning disable SKEXP0010 public partial class ChatForm : Form { ...... }
(3)Embedding
private void btnEmbedding_Click(object sender, EventArgs e) { var query = new QueryModel(tbxIndex.Text, tbxPrompt.Text); _textMemory = this.GetTextMemory().GetAwaiter().GetResult(); var lines = TextChunker.SplitPlainTextLines(query.Text, _textChunkerLinesToken); var paragraphs = TextChunker.SplitPlainTextParagraphs(lines, _textChunkerParagraphsToken); foreach (var para in paragraphs) { Task.Run(() => { ShowProcessMessage("AI is embedding your content now..."); _textMemory.SaveInformationAsync( query.Index, id: Guid.NewGuid().ToString(), text: para) .GetAwaiter() .GetResult(); ShowProcessMessage("Embedding success!"); MessageBox.Show("Embedding success!", "Information", MessageBoxButtons.OK, MessageBoxIcon.Information); }); } } private async Task<ISemanticTextMemory> GetTextMemory() { var memoryBuilder = new MemoryBuilder(); var embeddingApiClient = new HttpClient(new OpenAiHttpHandler(_embeddingApiConfiguration.Provider, _embeddingApiConfiguration.EndPoint)); memoryBuilder.WithOpenAITextEmbeddingGeneration( _embeddingApiConfiguration.ModelId, _embeddingApiConfiguration.ApiKey, httpClient: embeddingApiClient); var memoryStore = await SqliteMemoryStore.ConnectAsync("memstore.db"); memoryBuilder.WithMemoryStore(memoryStore); var textMemory = memoryBuilder.Build(); return textMemory; }
在Click事件中,调用GetTextMemory方法进行真正的Embedding操作,然后进行数据持久化到本地的Sqlite数据库。在GetTextMemory这个方法中,实现了调用Embedding模型API进行词嵌入。
数据写入Sqlite后打开表后的效果如下图所示。至于这个collection字段,是对应界面中的Index字段,这里我们暂时不用管它。

(4)Generation
private void btnGetRagResponse_Click(object sender, EventArgs e) { if (_textMemory == null) _textMemory = this.GetTextMemory().GetAwaiter().GetResult(); var query = new QueryModel(tbxIndex.Text, tbxPrompt.Text); var memoryResults = _textMemory.SearchAsync(query.Index, query.Text, limit: 3, minRelevanceScore: 0.3); Task.Run(() => { var existingKnowledge = this.BuildPromptInformation(memoryResults).GetAwaiter().GetResult(); var integratedPrompt = @" 获取到的相关信息:[{0}]。 根据获取到的信息回答问题:[{1}]。 如果没有获取到相关信息,请直接回答 Sorry不知道。 "; ShowProcessMessage("AI is handling your request now..."); var response = _kernel.InvokePromptAsync(string.Format(integratedPrompt, existingKnowledge, query.Text)) .GetAwaiter() .GetResult(); UpdateResponseContent(response.ToString()); ShowProcessMessage("AI Response:"); }); } private async Task<string> BuildPromptInformation(IAsyncEnumerable<MemoryQueryResult> memoryResults) { var information = string.Empty; await foreach (MemoryQueryResult memoryResult in memoryResults) { information += memoryResult.Metadata.Text; } return information; }
在Click事件中,将用户的原始提示词 和 从知识库中获取的知识片段 通过一个提示词模板 组成另一个增强版的 提示词,最后将这个新的提示词发给LLM进行处理回答。
小结
本文简单介绍了一下RAG(检索增强生成)的基本概念 和 工作流程,然后通过一个简单的DEMO快速直观感受了一下RAG的作用。后续,我们会持续关注RAG的更多细节内容 和 落地实践。
参考内容
mingupupu大佬的文章:https://www.cnblogs.com/mingupupu/p/18367726
示例源码
GitHub:https://github.com/Coder-EdisonZhou/EDT.Agent.Demos
推荐学习
Microsoft Learn, 《Semantic Kernel 学习之路》,点击查看原文按钮即可直达



 浙公网安备 33010602011771号
浙公网安备 33010602011771号