02ES基础操作
IK分词器插件
什么是IK分词器?
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如 “我爱狂神” 会被分为"我","爱","狂","神",这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
如果要使用中文,建议使用ik分词器!
IK提供了两个分词算法:ik_smart 和 ik_max_word,其中 ik_smart 为最少切分,ik_max_word为最细粒度划分!一会我们测试!
安装步骤
1、下载ik分词器的包,Github地址:https://github.com/medcl/elasticsearch-analysis-ik/ (版本要对应)
2、下载后解压,并将目录拷贝到ElasticSearch根目录下的 plugins 目录中。
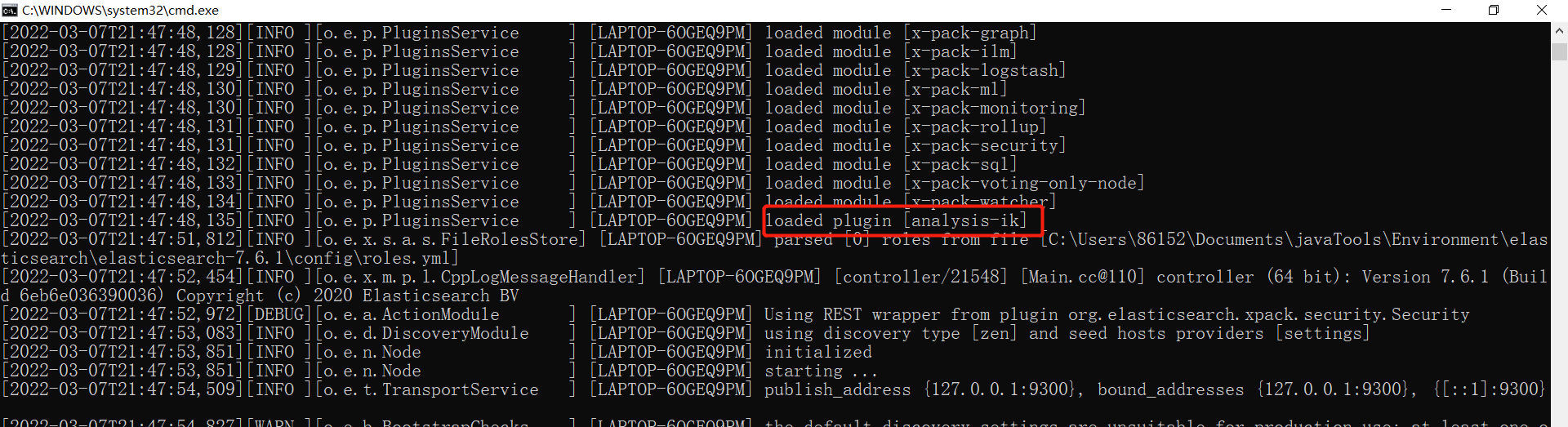
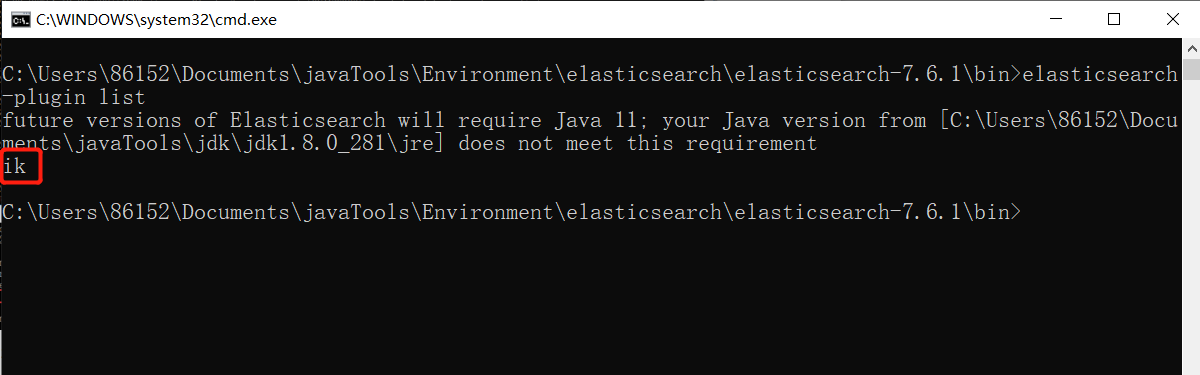
3、重新启动 ElasticSearch 服务,在启动过程中,你可以看到正在加载"analysis-ik"插件的提示信息, 服务启动后,在命令行运行 elasticsearch-plugin list 命令,确认 ik 插件安装成功。
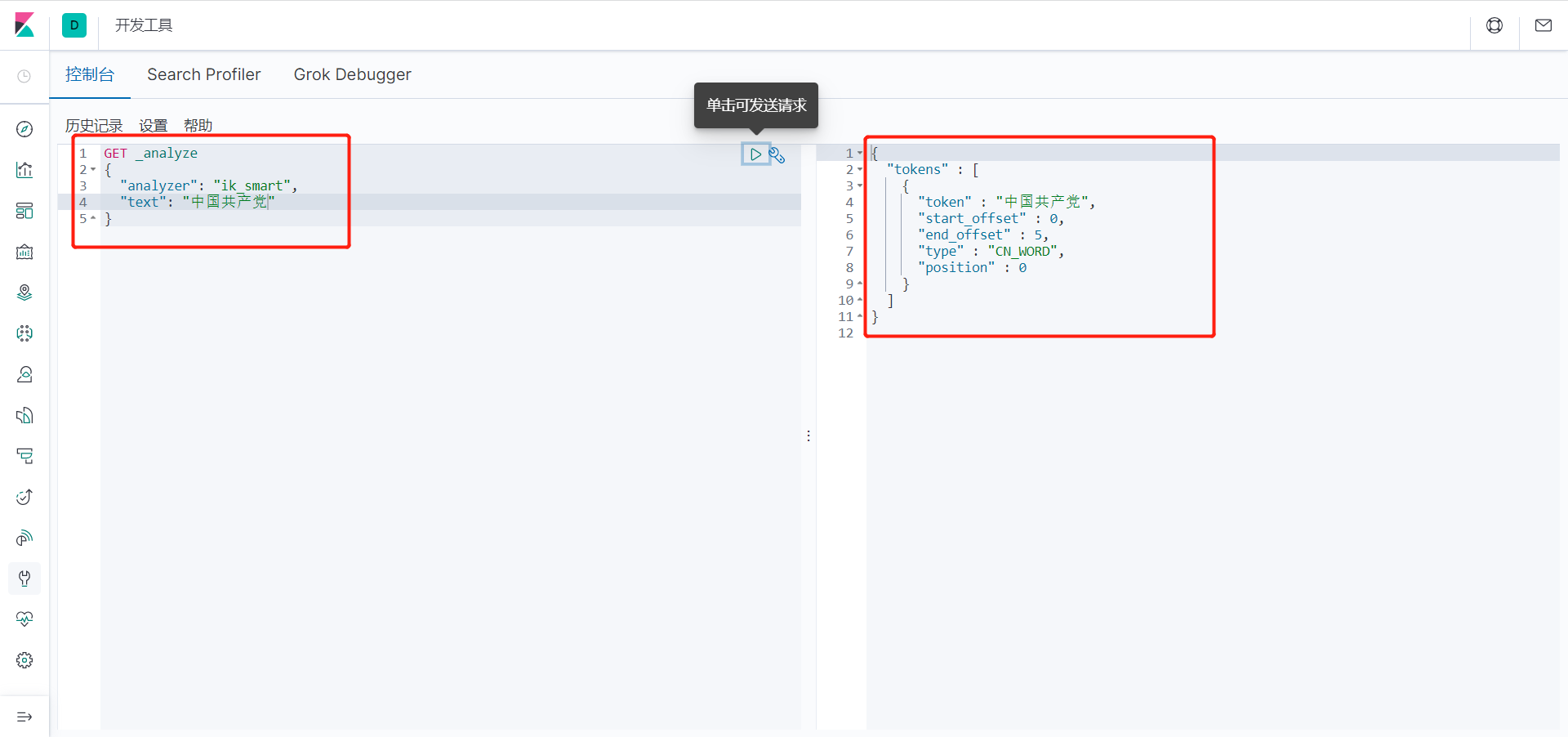
4、在 kibana 中测试 ik 分词器,并就相关分词结果和 icu 分词器进行对比。
ik_smart : 粗粒度分词,优先匹配最长词,只有1个词!
ik_max_word : 细粒度分词,会穷尽一个语句中所有分词可能,测试!
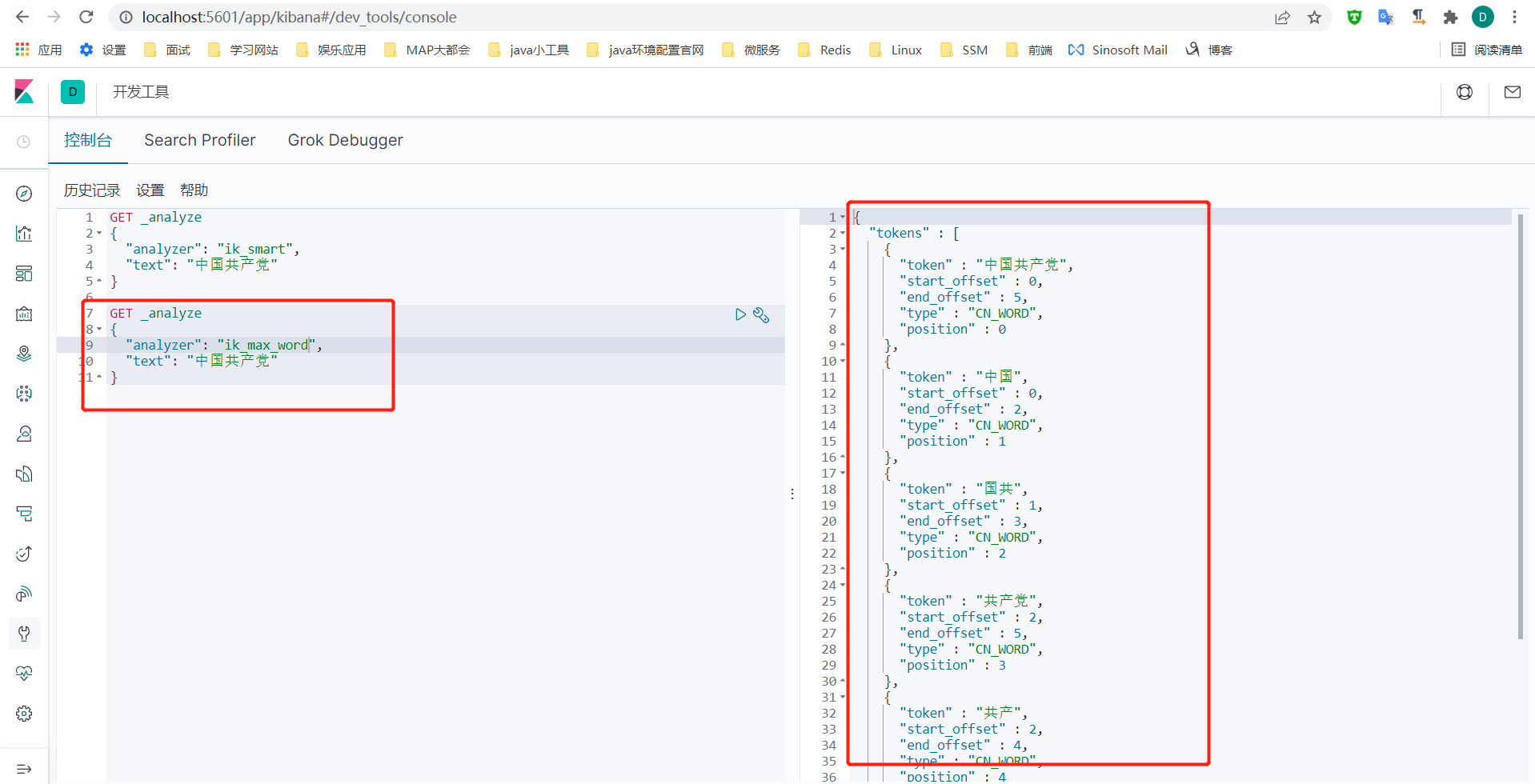
5、我们输入超级喜欢狂神说!发现狂神说被切分了
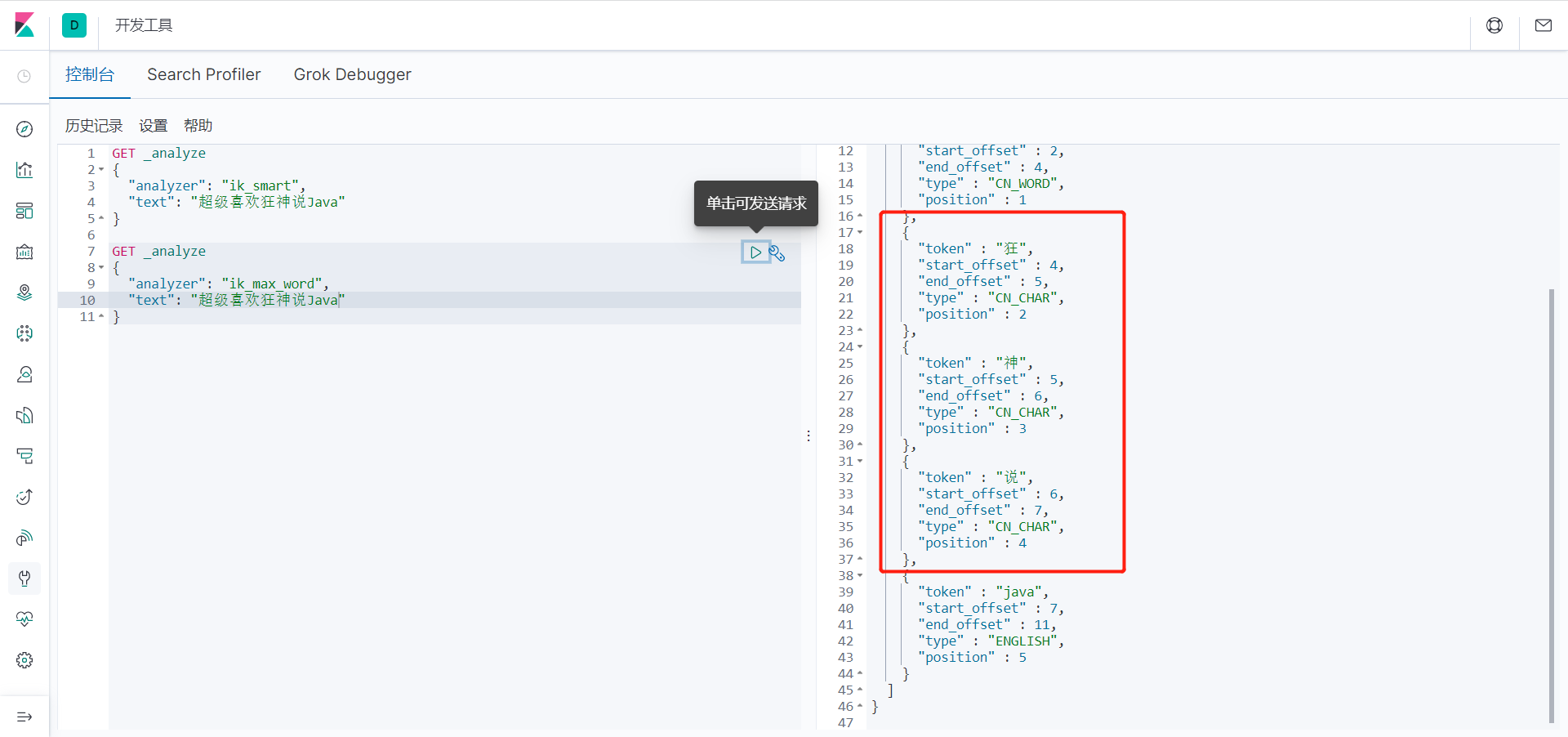
如果我们想让系统识别“狂神说”是一个词,需要编辑自定义词库。
步骤:
(1)进入elasticsearch/plugins/ik/config目录
(2)新建一个my.dic文件,编辑内容:
狂神说
(3)修改IKAnalyzer.cfg.xml(在ik/config目录下)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
修改完配置重新启动elasticsearch,再次测试!
发现监视了我们自己写的规则文件:

再次测试,发现狂神说变成了一个词:
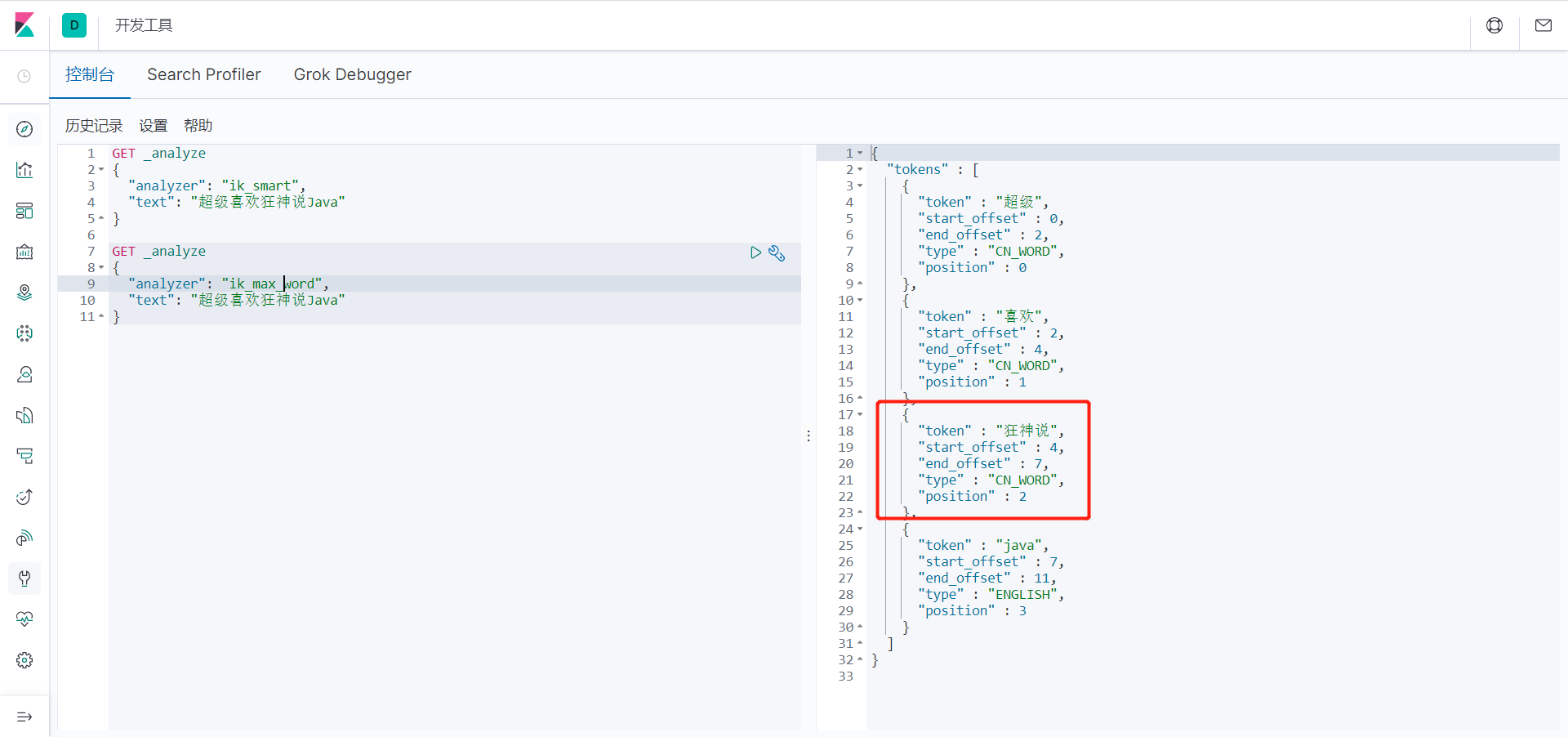
到了这里,我们就明白了分词器的基本规则和使用了!
Rest风格说明
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
基本Rest命令说明:
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档id |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
关于索引的基本操作
基础测试(创建索引)
1、首先我们浏览器 http://localhost:5601/ 进入 kibana里的Console
2、首先让我们在 Console 中输入 :
// 命令解释
// PUT 创建命令 test1 索引 type1 类型 1 id
PUT /test1/type1/1
{
"name":"狂神说", // 属性
"age":16 // 属性
}
返回结果 (是以REST ful 风格返回的 ):
// 警告信息:不支持在文档索引请求中指定类型
// 而是使用无类型的端点(/{index}/_doc/{id}, /{index}/_doc,或 /{index}/_create/{id})。
#! Deprecation: [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}).
{
"_index" : "test1", // 索引
"_type" : "type1", // 类型
"_id" : "1", // id
"_version" : 1, // 版本
"result" : "created", // 操作类型
"_shards" : { // 分片信息
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
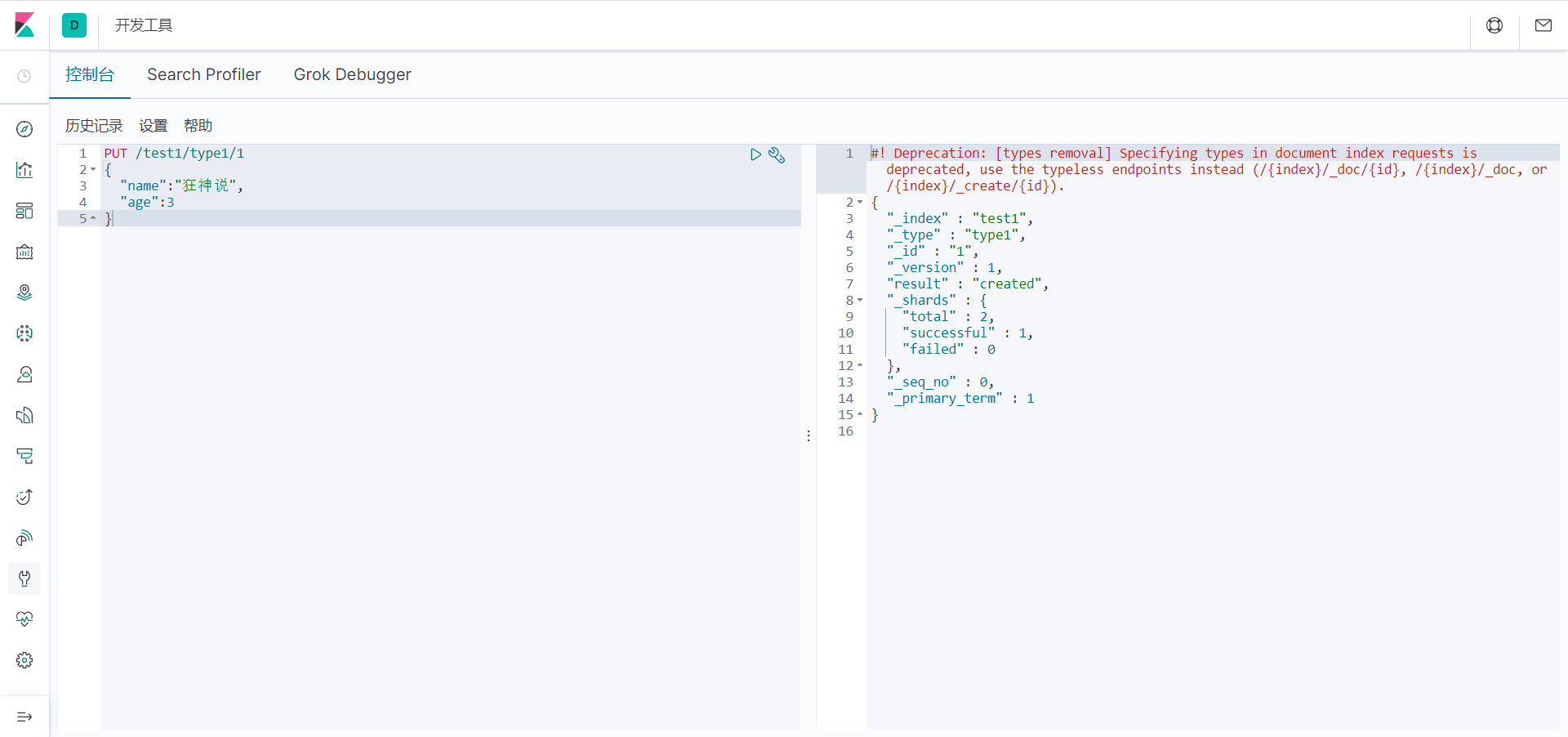
完成了自动增加了索引!数据也成功的添加了,这就是我说大家在初期可以把它当作数据库学习的原因!
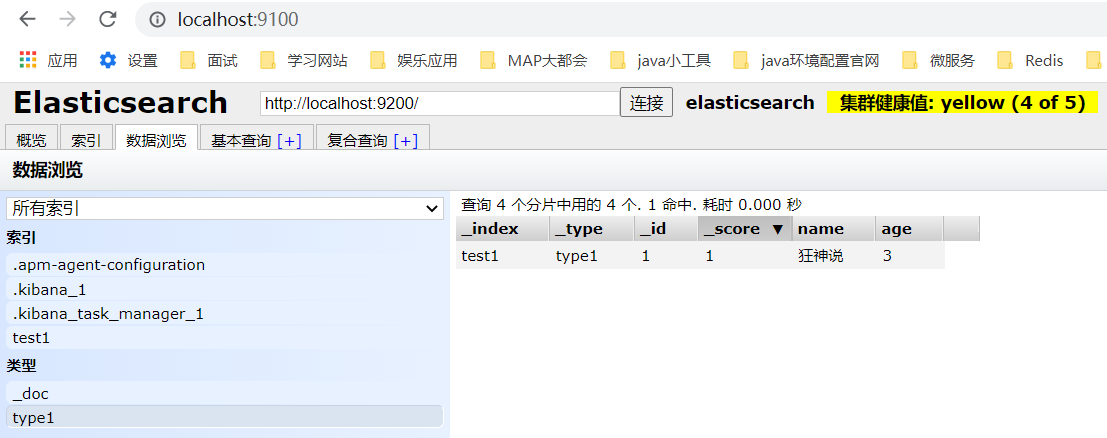
2、那么 name 这个字段用不用指定类型呢。毕竟我们关系型数据库 是需要指定类型的啊 !
-
字符串类型
-
数值类型
long, integer, short, byte, double, float, half_float, scaled_float
-
日期类型
-
布尔值类型
-
二进制类型
-
等等......
4、指定字段类型
PUT /test2
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
输出:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test2"
}
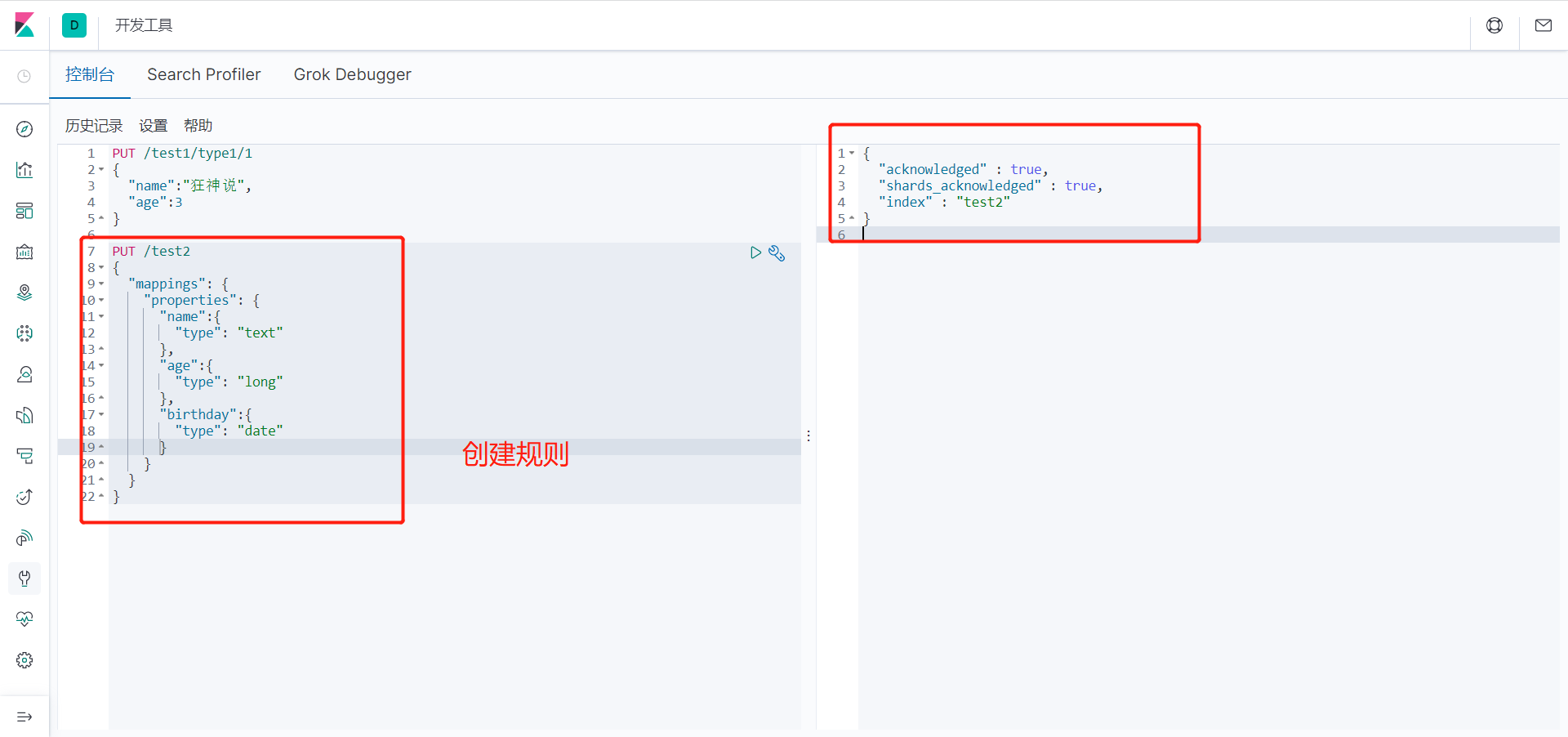
5、查看一下索引字段
GET test2
输出:
{
"test2" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"birthday" : {
"type" : "date"
},
"name" : {
"type" : "text"
}
}
},
"settings" : {
"index" : {
"creation_date" : "1646752424929",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "ChJG56WlTU-ozPxdHk8Rpg",
"version" : {
"created" : "7060199"
},
"provided_name" : "test2"
}
}
}
}
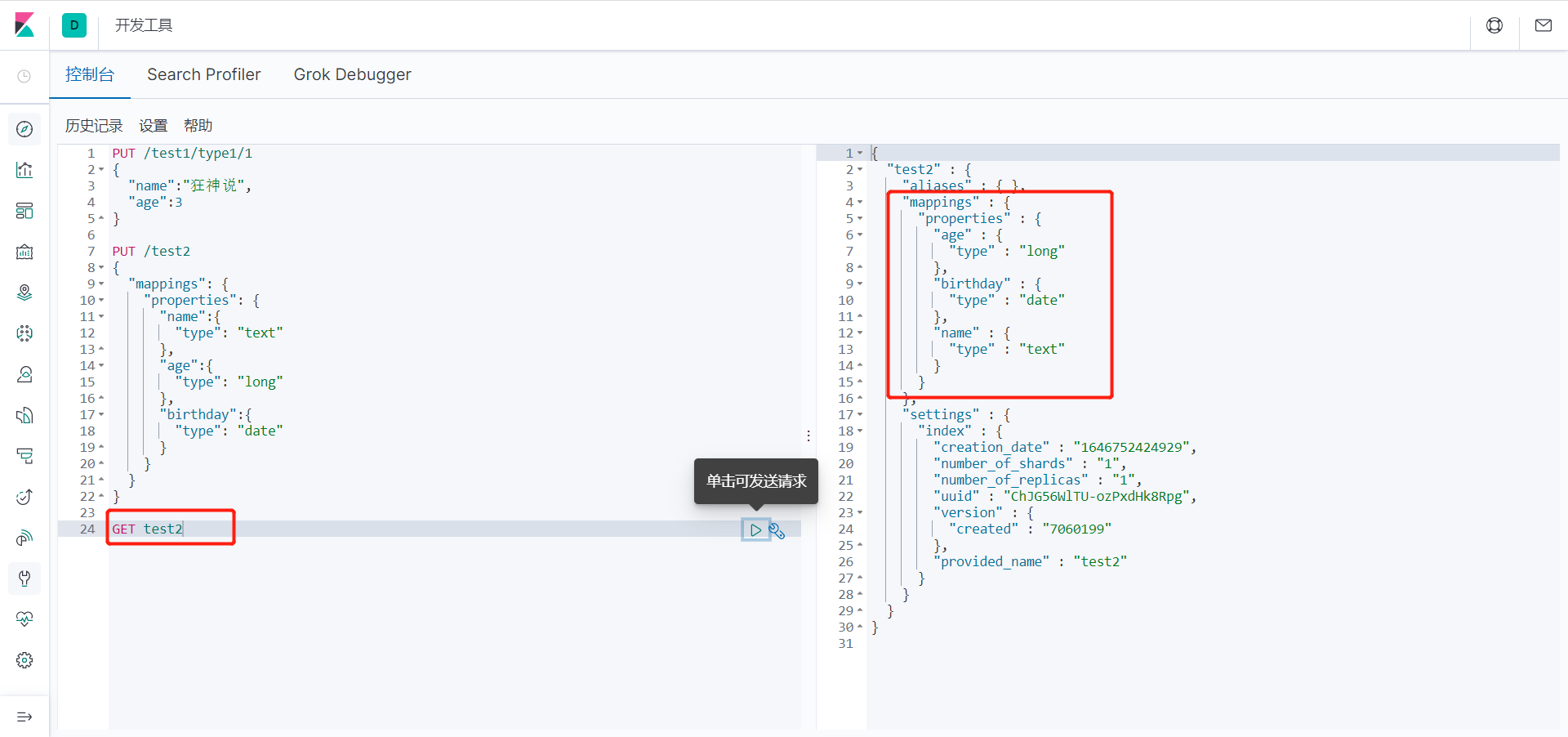
6、我们看上列中 字段类型是我自己定义的 那么 我们不定义类型 会是什么情况呢?
PUT /test3/_doc/1
{
"name":"狂神说",
"age":13,
"birth":"1997-01-05"
}
输出:
{
"_index" : "test3",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
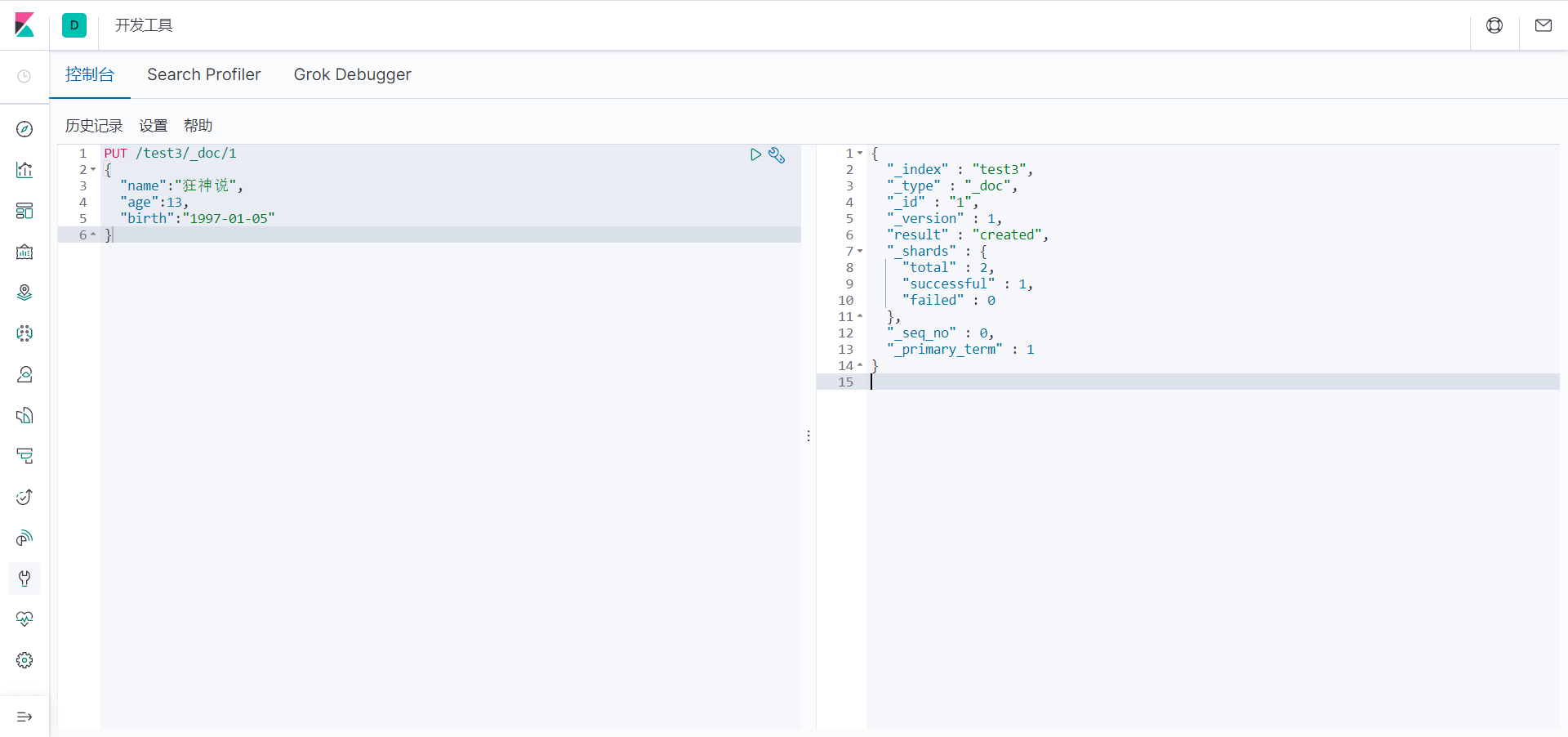
查看一下test3索引:
GET test3
返回结果:
{
"test3" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"birth" : {
"type" : "date"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1646752907193",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "N2PiarItRnKPqizVEuvolg",
"version" : {
"created" : "7060199"
},
"provided_name" : "test3"
}
}
}
}
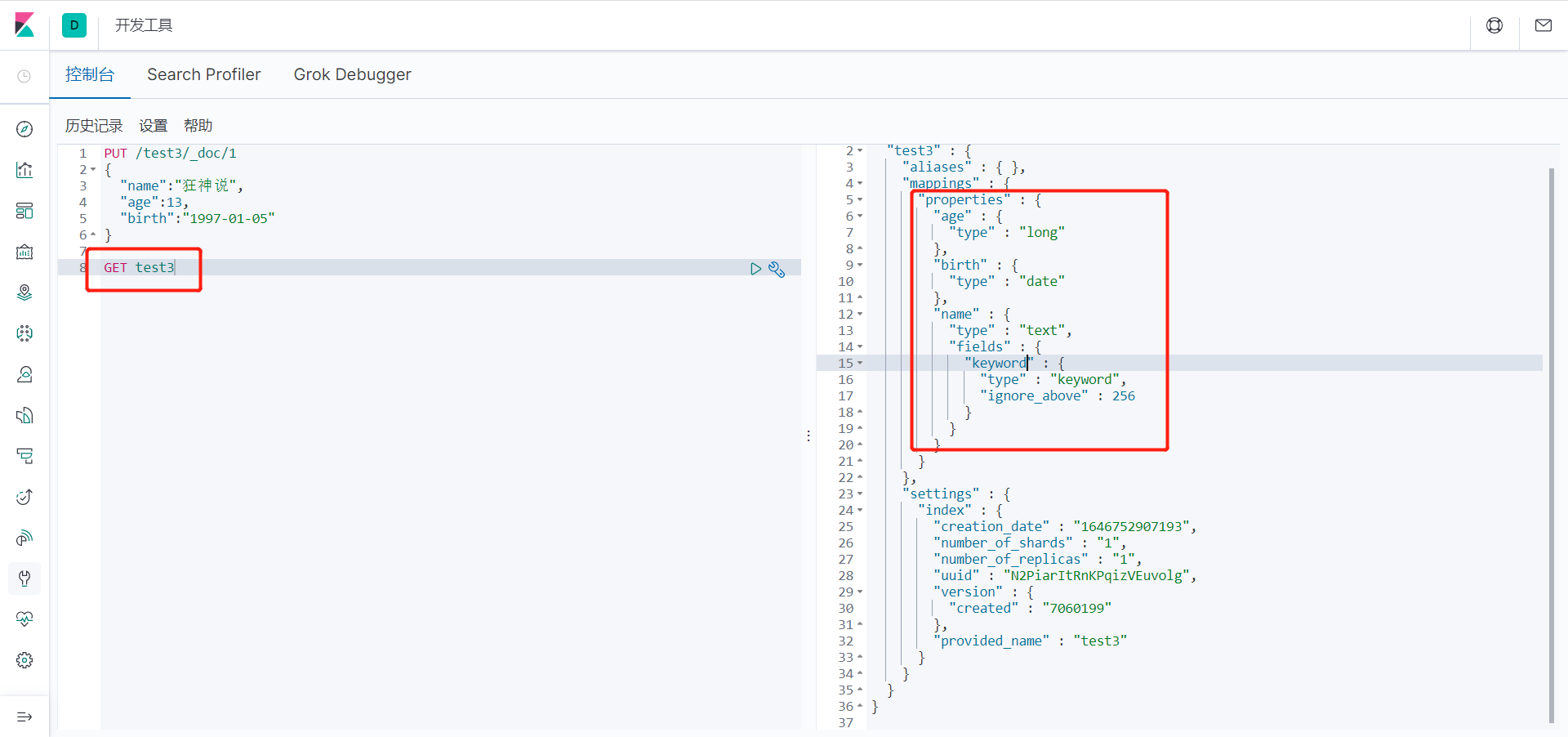
我们看上列没有给字段指定类型那么es就会默认给我配置字段类型!
对比关系型数据库 :
PUT test1/type1/1 : 索引test1相当于关系型数据库的库,类型type1就相当于表 ,1 代表数据中的主 键 id
这里需要补充的是 ,在elastisearch5版本前,一个索引下可以创建多个类型,但是在elastisearch5后, 一个索引只能对应一个类型,而id相当于关系型数据库的主键id若果不指定就会默认生成一个20位的 uuid,属性相当关系型数据库的column(列)。
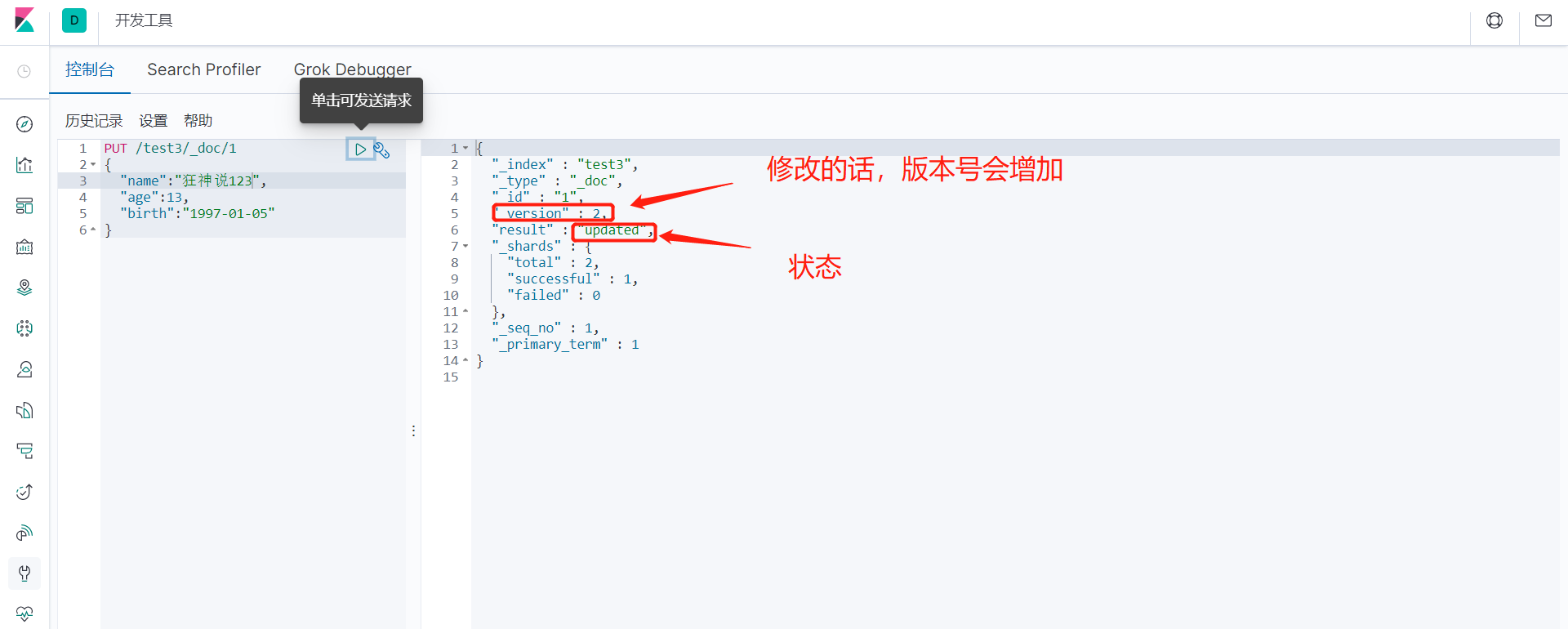
而结果中的 result 则是操作类型,现在是 created ,表示第一次创建。如果再次点击执行该命令那么 result 则会是 updated ,我们细心则会发现 _version 开始是1,现在你每点击一次就会增加一次。表示 第几次更改。
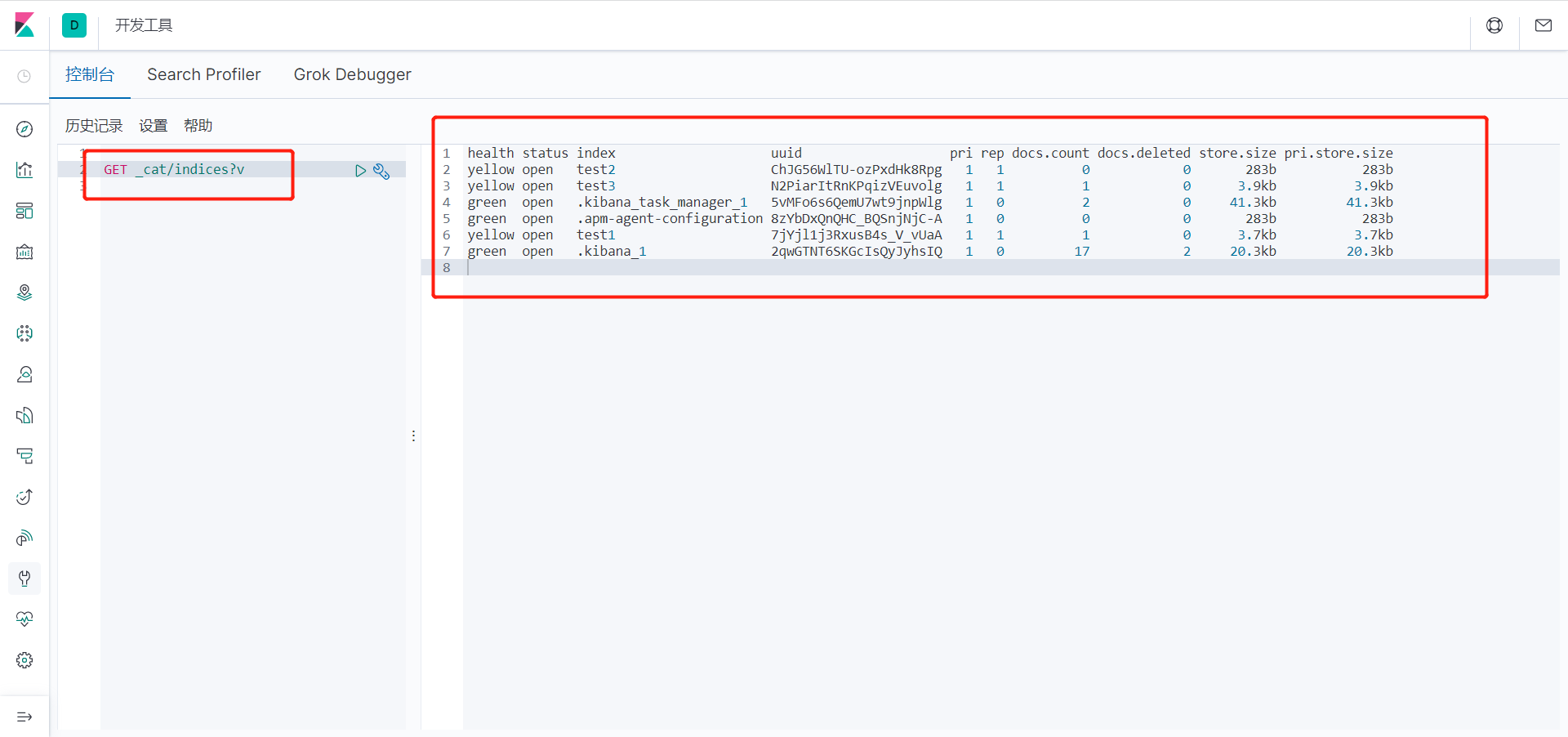
7、我们在来学一条命令 (elasticsearch 中的索引的情况) :
GET _cat/indices?v
返回结果:查看我们所有索引的状态健康情况 分片,数据储存大小等等。
修改 提交还是使用PUT即可!然后覆盖!最新办法!
曾经!
当执行 PUT 命令时,如果数据不存在,则新增该条数据,如果数据存在则修改该条数据。
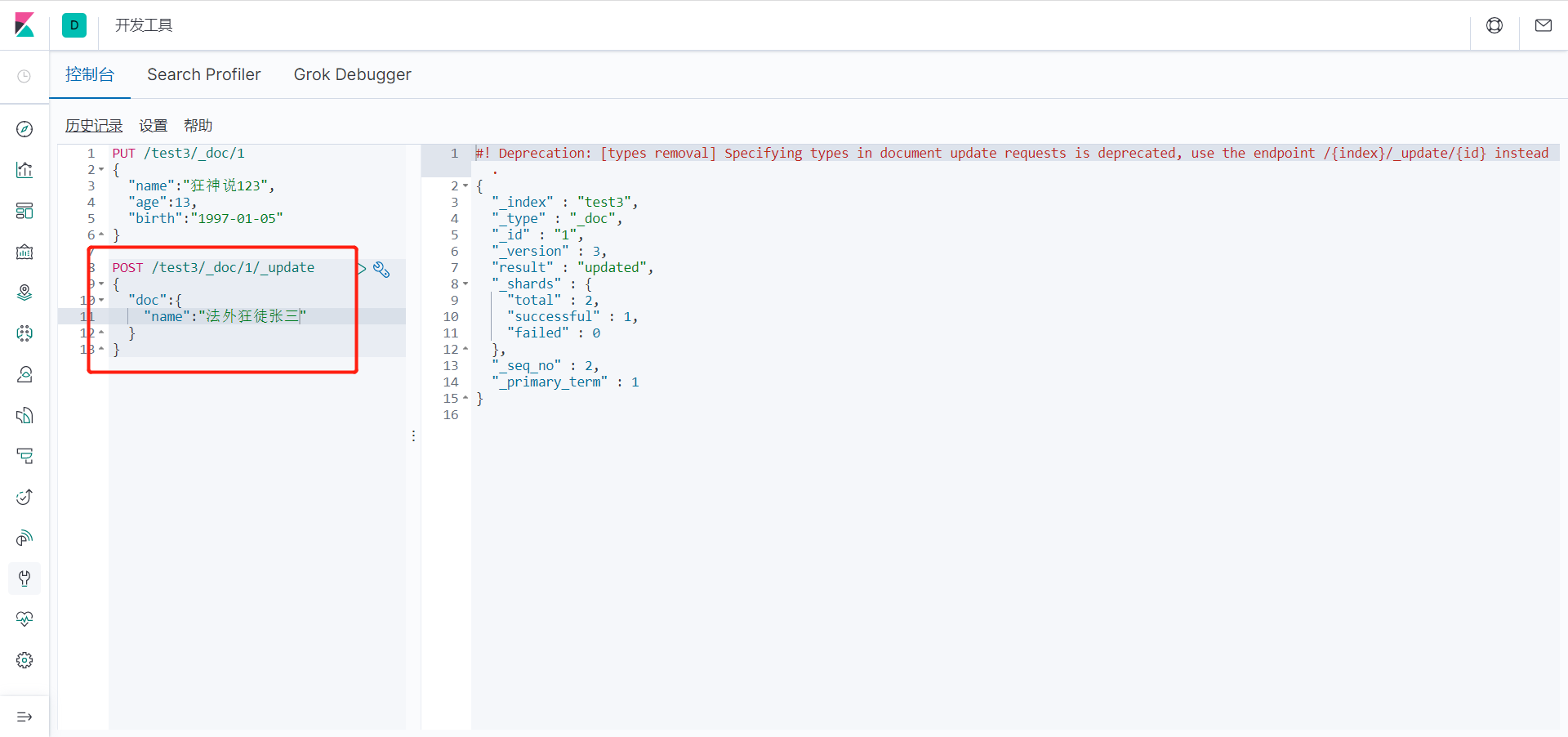
麻烦的是 原数据你还要重写一遍要 这不符合我们规矩。
现在的!
我们使用 POST 命令,在 id 后面跟 _update ,要修改的内容放到 doc 文档(属性)中即可。
删除索引!
通过 DELETE 命令实现删除、根据你的请求来判断是删除索引还是删除文档记录!
使用 RESTFUL 风格是我们ES推荐大家使用的!
DELETE /test1
返回:
{
"acknowledged" : true // 表示删除成功!
}
关于文档的基本操作
创建数据PUT
// 第一条数据:
PUT /kuangshen/user/1
{
"name":"狂神说",
"age":23,
"desc":"一段操作猛如虎,一看工资2500",
"tags":["技术宅","暖男","直男"]
}
// 第二条数据:
PUT /kuangshen/user/2
{
"name":"张三",
"age":3,
"desc":"法外狂徒",
"tags":["交友","旅游","渣男"]
}
// 第三条数据:
PUT /kuangshen/user/3
{
"name":"李四",
"age":30,
"desc":"mmp,不知道怎么形容",
"tags":["靓女","旅游","唱歌"]
}
查看下数据:
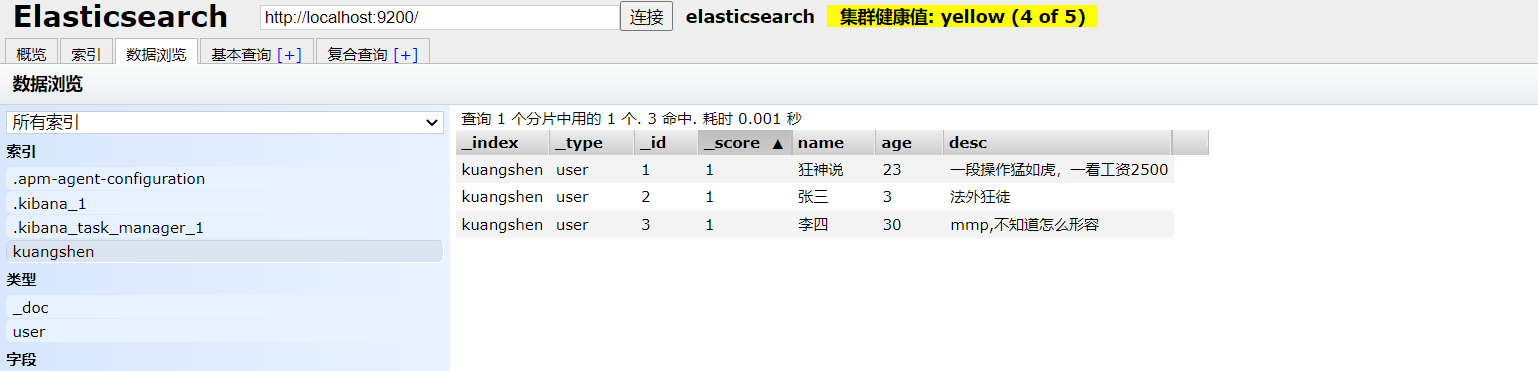
注意⚠ :当执行 命令时,如果数据不存在,则新增该条数据,如果数据存在则修改该条数据。
咱们通过 GET 命令查询一下 :
GET /kuangshen/user/1
返回结果:
#! Deprecation: [types removal] Specifying types in document get requests is deprecated, use the /{index}/_doc/{id} endpoint instead.
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "狂神说",
"age" : 23,
"desc" : "一段操作猛如虎,一看工资2500",
"tags" : [
"技术宅",
"暖男",
"直男"
]
}
}
如果你想更新数据 可以覆盖这条数据 :
PUT /kuangshen/user/3
{
"name":"李四233",
"age":30,
"desc":"mmp,不知道怎么形容",
"tags":["靓女","旅游","唱歌"]
}
返回结果:
#! Deprecation: [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}).
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "3",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
已经修改了 那么 PUT 可以更新数据。但是,麻烦的是 原数据你还要重写一遍要 这不符合我们规矩。
更新数据 POST
我们使用 POST 命令,在 id 后面跟 _update ,要修改的内容放到 doc 文档(属性)中即可。
POST /kuangshen/user/1/_update
{
"doc":{
"name":"狂神说Java"
}
}
返回结果:
#! Deprecation: [types removal] Specifying types in document update requests is deprecated, use the endpoint /{index}/_update/{id} instead.
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_version" : 4,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 6,
"_primary_term" : 1
}
条件查询_search?q=
简单的查询,我们上面已经不知不觉的使用熟悉了:
GET /kuangshen/user/1
我们来学习下条件查询 _search?q=
GET /kuangshen/user/_search?q=name:狂神说
通过 _serarch?q=name:狂神说 查询条件是name属性有狂神说的那些数据。
别忘 了 _search 和 q 属性中间的分隔符 ? 。
返回结果:
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 17,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.7796593,
"hits" : [
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_score" : 1.7796593,
"_source" : {
"name" : "狂神说Java",
"age" : 23,
"desc" : "一段操作猛如虎,一看工资2500",
"tags" : [
"技术宅",
"暖男",
"直男"
]
}
}
]
}
}
我们看一下结果 返回并不是 数据本身,是给我们了一个 hits ,还有 **_score ** 得分,就是根据算法算出的查询条件匹配度的得分。
构建查询
GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神"
}
}
}
上例,查询条件是一步步构建出来的,将查询条件添加到 match 中即可。返回结果还是一样的:
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.489748,
"hits" : [
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_score" : 1.489748,
"_source" : {
"name" : "狂神说Java",
"age" : 23,
"desc" : "一段操作猛如虎,一看工资2500",
"tags" : [
"技术宅",
"暖男",
"直男"
]
}
}
]
}
}
除此之外,我们还可以查询全部:
GET kuangshen/user/_search #这是一个查询但是没有条件
{
"query": {
"match_all": {}
}
}
match_all的值为空,表示没有查询条件,就像select * from table_name一样。
返回结果:全部查询出来了!
如果有个需求,我们仅是需要查看 name 和 desc 两个属性,其他的不要怎么办?
GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神"
}
},
"_source": ["name","desc"]
}
如上例所示,在查询中,通过 _source 来控制仅返回 name 和 age 属性。
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.00541,
"hits" : [
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_score" : 1.00541,
"_source" : {
"name" : "狂神说Java",
"desc" : "一段操作猛如虎,一看工资2500"
}
},
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "4",
"_score" : 0.90396726,
"_source" : {
"name" : "狂神说前端",
"desc" : "一段操作猛如虎,一看工资2500"
}
}
]
}
}
一般的,我们推荐使用构建查询,以后在与程序交互时的查询等也是使用构建查询方式处理查询条件, 因为该方 式可以构建更加复杂的查询条件,也更加一目了然
排序查询
我们说到排序 有人就会想到:正序 或 倒序 那么我们先来倒序:
GET kuangshen/user/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
上例,在条件查询的基础上,我们又通过 sort 来做排序,排序对象是 age , order 是 desc 降序。
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "3",
"_score" : null,
"_source" : {
"name" : "李四233",
"age" : 30,
"desc" : "mmp,不知道怎么形容",
"tags" : [
"靓女",
"旅游",
"唱歌"
]
},
"sort" : [
30
]
},
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_score" : null,
"_source" : {
"name" : "狂神说Java",
"age" : 23,
"desc" : "一段操作猛如虎,一看工资2500",
"tags" : [
"技术宅",
"暖男",
"直男"
]
},
"sort" : [
23
]
},
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "2",
"_score" : null,
"_source" : {
"name" : "张三",
"age" : 3,
"desc" : "法外狂徒",
"tags" : [
"交友",
"旅游",
"渣男"
]
},
"sort" : [
3
]
},
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "4",
"_score" : null,
"_source" : {
"name" : "狂神说前端",
"age" : 3,
"desc" : "一段操作猛如虎,一看工资2500",
"tags" : [
"技术宅",
"暖男",
"直男"
]
},
"sort" : [
3
]
}
]
}
}
正序,就是 desc 换成了 asc
GET kuangshen/user/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
注意:在排序的过程中,只能使用可排序的属性进行排序。那么可以排序的属性有哪些呢?
- 数字
- 日期
- ID
其他都不行!
分页查询
GET kuangshen/user/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "asc"
}
}
],
"from": 0, # 从第n条开始
"size": 1 # 返回n条数据
}
返回结果:
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "2",
"_score" : null,
"_source" : {
"name" : "张三",
"age" : 3,
"desc" : "法外狂徒",
"tags" : [
"交友",
"旅游",
"渣男"
]
},
"sort" : [
3
]
}
]
}
}
就返回了一条数据 是从第0条开始的返回一条数据 。可以再测试!
学到这里,我们也可以看到,我们的查询条件越来越多,开始仅是简单查询,慢慢增加条件查询,增加 排序,对返回 结果进行限制。所以,我们可以说:对于elasticsearch来说,所有的查询条件都是可插拔的,彼此之间可分割。比如说,我们在查询中,仅对返回结果进行限制:
GET kuangshen/user/_search
{
"query": {
"match_all": {}
},
"from": 0, # 从第n条开始
"size": 1 # 返回n条数据
}
布尔查询
must (and)
我要查询所有 name 属性为“ 狂神说 “的数据,并且年龄为3的!
GET kuangshen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "狂神说"
}
},
{
"match": {
"age": 3
}
}
]
}
}
}
我们通过在 bool 属性内使用 must 来作为查询条件!看结果,是不是 有点像 and 的感觉,里面的条件需要都满足!
should (or)
那么我要查询name为狂神说 或 age 为 3 的呢?
GET kuangshen/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "狂神说"
}
},
{
"match": {
"age": 3
}
}
]
}
}
}
返回结果:
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 2.3559508,
"hits" : [
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "4",
"_score" : 2.3559508,
"_source" : {
"name" : "狂神说前端",
"age" : 3,
"desc" : "一段操作猛如虎,一看工资2500",
"tags" : [
"技术宅",
"暖男",
"直男"
]
}
},
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_score" : 1.5081149,
"_source" : {
"name" : "狂神说Java",
"age" : 23,
"desc" : "一段操作猛如虎,一看工资2500",
"tags" : [
"技术宅",
"暖男",
"直男"
]
}
},
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "张三",
"age" : 3,
"desc" : "法外狂徒",
"tags" : [
"交友",
"旅游",
"渣男"
]
}
}
]
}
}
我们的返回结果 是不是 出现了一个 age : 23的。是不是有点像 or 呢
must_not (not)
我想要查询 年龄不是 3 的数据
GET kuangshen/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"age": 3
}
}
]
}
}
}
Fitter
我要查询 name 为狂神 的,age大于10的数据
GET kuangshen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "狂神"
}
}
],
"filter": {
"range": {
"age": {
"gt": 10
}
}
}
}
}
}
这里就用到了 filter 条件过滤查询,过滤条件的范围用 range 表示, gt 表示大于,大于多少呢?是10。
其余操作如下 :
- gt 表示大于
- gte 表示大于等于
- lt 表示小于
- lte 表示小于等于
要查询 name 是 狂神, age 在 1~30 之间的怎么查?
GET kuangshen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "狂神"
}
}
],
"filter": {
"range": {
"age": {
"gt": 1,
"lt": 30
}
}
}
}
}
}
短语检索
我要查询 tags为男的数据
GET kuangshen/user/_search
{
"query": {
"match": {
"tags": "男"
}
}
}
返回了所有标签中带 男 的记录!
既然按照标签检索,那么,能不能写多个标签呢?又该怎么写呢?
GET kuangshen/user/_search
{
"query": {
"match": {
"tags": "男 技术"
}
}
}
返回:只要含有这个标签满足一个就给我返回这个数据了。
term查询精确查询
term 查询是直接通过倒排索引指定的 词条,也就是精确查找。
term和match的区别:
- match是经过分析(analyer)的,也就是说,文档是先被分析器处理了,根据不同的分析器,分析出的结果也会不同,才会根据分词 结果进行匹配。
- term是不经过分词的,直接去倒排索引查找精确的值。
总结:
1、match的查询条件会分词,假如查询字段是text,即可分词查询,假如查询字段是keyword,那必须查询条件是keyword才可被查到
2、term的查询条件不会分词的,必须是倒排索引的词汇,才可查询。而keyword类型的字段的值一定在倒排索引的词汇中。
注意 ⚠ :我们现在 用的es7版本 所以我们用 mappings properties 去给多个字段(fields)指定类型的时候,不能给我们的 索引制定类型:
PUT testdb
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"desc":{
"type": "keyword"
}
}
}
}
// 插入数据
PUT testdb/_doc/1
{
"name":"狂神说Java name",
"desc":"狂神说Java desc"
}
PUT testdb/_doc/2
{
"name":"狂神说Java name",
"desc":"狂神说Java desc2"
}
上述中testdb索引中,字段name在被查询时会被分析器进行分析后匹配查询。而属于keyword类型不会被分析器处理。
我们来验证一下:
GET _analyze
{
"analyzer": "keyword",
"text":"狂神说Java name"
}
结果:
{
"tokens" : [
{
"token" : "狂神说Java name",
"start_offset" : 0,
"end_offset" : 12,
"type" : "word",
"position" : 0
}
]
}
是不是没有被分析啊。就是简单的一个字符串啊。再测试
GET _analyze
{
"analyzer": "standard",
"text":"狂神说Java name"
}
结果:
{
"tokens" : [
{
"token" : "狂",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "神",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "说",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "java",
"start_offset" : 3,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "name",
"start_offset" : 8,
"end_offset" : 12,
"type" : "<ALPHANUM>",
"position" : 4
}
]
}
那么我们看一下 字符串是不是被分析了啊。
总结:keyword 字段类型不会被分析器分析!
现在我们来查询一下:
GET testdb/_search // text 会被分析器分析 为 狂 神 说 Java name,倒排索引的文档中没有 狂神说 ,所以查询不到
{ // 假如只搜 name:狂,可以搜到数据
"query": {
"term": {
"name": {
"value": "狂神说"
}
}
}
}
GET testdb/_search // keyword 不会被分析,倒排索引的文档中有 狂神说Java desc,所以能被查到
{
"query": {
"term": {
"desc": {
"value": "狂神说Java desc"
}
}
}
}
查找多个精确值(terms)
官网地址:https://www.elastic.co/guide/cn/elasticsearch/guide/current/_finding_multiple_exact_values.html
PUT testdb/_doc/3
{
"t1":"22",
"t2":"2022-3-12"
}
PUT testdb/_doc/4
{
"t1":"33",
"t2":"2022-4-12"
}
# 查询 精确查找多个值
GET testdb/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"t1": "22"
}
},
{
"term": {
"t1":"33"
}
}
]
}
}
}
除了bool查询之外:
GET testdb/_search
{
"query": {
"terms": {
"t1": [
"22",
"33"
]
}
}
}
高亮显示
GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神"
}
},
"highlight": {
"fields": {
"name":{}
}
}
}
返回结果:
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.00541,
"hits" : [
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_score" : 1.00541,
"_source" : {
"name" : "狂神说Java",
"age" : 23,
"desc" : "一段操作猛如虎,一看工资2500",
"tags" : [
"技术宅",
"暖男",
"直男"
]
},
"highlight" : {
"name" : [
"<em>狂</em><em>神</em>说Java"
]
}
},
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "4",
"_score" : 0.90396726,
"_source" : {
"name" : "狂神说前端",
"age" : 3,
"desc" : "一段操作猛如虎,一看工资2500",
"tags" : [
"技术宅",
"暖男",
"直男"
]
},
"highlight" : {
"name" : [
"<em>狂</em><em>神</em>说前端"
]
}
}
]
}
}
我们可以看到已经帮我们加上了一个<em>标签
<em>狂</em><em>神</em>说前端
"highlight" : {
"name" : [
"<em>狂</em><em>神</em>说前端"
]
}
这是es帮我们加的标签。那我也可以自己自定义样式
GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神"
}
},
"highlight": {
"pre_tags": "<p class='key' stype='color:red'>",
"post_tags": "</p>",
"fields": {
"name":{}
}
}
}
结果:
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.00541,
"hits" : [
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_score" : 1.00541,
"_source" : {
"name" : "狂神说Java",
"age" : 23,
"desc" : "一段操作猛如虎,一看工资2500",
"tags" : [
"技术宅",
"暖男",
"直男"
]
},
"highlight" : {
"name" : [
"<p class='key' stype='color:red'>狂</p><p class='key' stype='color:red'>神</p>说Java"
]
}
},
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "4",
"_score" : 0.90396726,
"_source" : {
"name" : "狂神说前端",
"age" : 3,
"desc" : "一段操作猛如虎,一看工资2500",
"tags" : [
"技术宅",
"暖男",
"直男"
]
},
"highlight" : {
"name" : [
"<p class='key' stype='color:red'>狂</p><p class='key' stype='color:red'>神</p>说前端"
]
}
}
]
}
}
需要注意的是:自定义标签中属性或样式中的逗号一律用英文状态的单引号表示,应该与外部 es 语法 的双引号区分开。
说明:Deprecation
注意 elasticsearch 在第一个版本的开始 每个文档都储存在一个索引中,并分配一个 映射类型,映射类型用于表示被索引的文档或者实体的类型,这样带来了一些问题, 导致后来在 elasticsearch6.0.0 版本中 一个文档只能包含一个映射类型,而在 7.0.0 中,映射类型则将被弃用,到了 8.0.0 中则将完全被删除。
只要记得,一个索引下面只能创建一个类型就行了,其中各字段都具有唯一性,如果在创建映射的时候,如果没有指定文档类型,那么该索引的默认索引类型是 _doc ,不指定文档id则会内部帮我们生成一个id字符串。
API创建索引及文档
找文档
网上的es教程大都十分老旧,而且es的版本众多,个别版本的差异还较大,另外es本身提供多种api,导致许多文章各种乱七八糟实例!所以后面直接放弃,从官网寻找方案,这里我使用elasticsearch最新的 7.6.1版本来讲解:
1、进入es的官网指导文档 https://www.elastic.co/guide/index.html
2、找到 Elasticsearch Clients(这个就是客户端api文档)

3、我们使用java rest风格api,大家可以根据自己的版本选择特定的other versions。

4、rest又分为high level和low level,我们直接选择high level下面的 Getting started
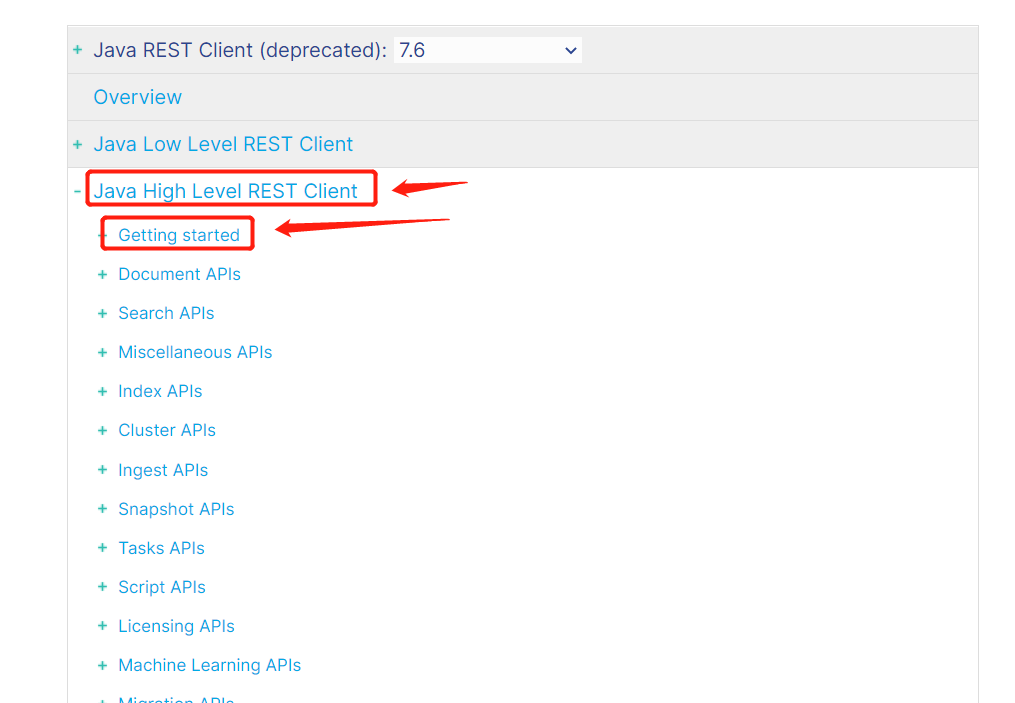
5、向下阅读找到Maven依赖和基本配置!
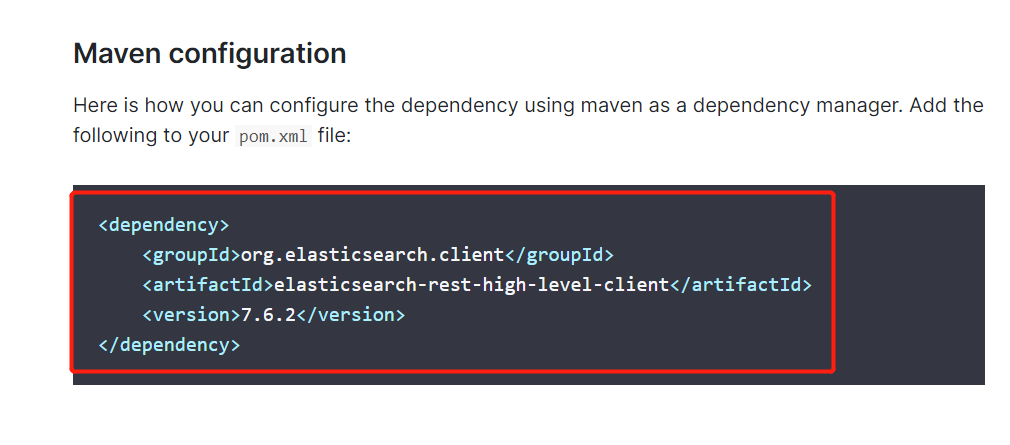
Java REST Client 说明
Java REST Client 有两种风格:
Java Low Level REST Client :用于Elasticsearch的官方低级客户端。它允许通过http与Elasticsearch集群通信。将请求编排和响应反编排留给用户自己处理。它兼容所有的Elasticsearch版本。(PS:学过WebService的话,对编排与反编排这个概念应该不陌生。可以理解为对请求参数的封装,以及对响应结果的解析)
Java High Level REST Client :用于Elasticsearch的官方高级客户端。它是基于低级客户端的,它提供很多API,并负责请求的编排与响应的反编排。(PS:就好比是,一个是传自己拼接好的字符串,并且自己解析返回的结果;而另一个是传对象,返回的结果也已经封装好了,直接是对象,更加规范了参数的名称以及格式,更加面对对象一点)
(PS:所谓低级与高级,我觉得一个很形象的比喻是,面向过程编程与面向对象编程)
网上很多教程比较老旧,都是使用TransportClient操作的,在 Elasticsearch 7.0 中不建议使用 TransportClient,并且在8.0中会完全删除TransportClient。因此,官方更建议我们用Java High Level REST Client,它执行HTTP请求,而不是序列号的Java请求。既然如此,这里我们就直接用高级了。
配置基本项目依赖
1、新建一个springboot(2.2.5版)项目 edgar-es-api,导入web依赖即可!
2、配置es的依赖!
<properties>
<java.version>1.8</java.version>
<!-- 这里SpringBoot默认配置的版本不匹配,我们需要自己配置版本! -->
<elasticsearch.version>7.6.1</elasticsearch.version>
</properties>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
3、继续阅读文档到Initialization ,我们看到需要构建RestHighLevelClient对象;
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http"))); // 构建客户端对象
// 操作....
// 高级客户端内部会创建低级客户端用于基于提供的builder执行请求。低级客户端维护一个连接池,
//并启动一些线程,因此当你用完以后应该关闭高级客户端,并且在内部它将会关闭低级客户端,以释放这
//些资源。关闭客户端可以使用close()方法:
client.close(); // 关闭
4、我们编写一个配置类,提供这个bean来进行操作
package com.edgar.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticsearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
return client;
}
}
常用方法工具类封装
package com.edgar.utils;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.List;
import java.util.concurrent.TimeUnit;
@Component
public class EsUtils<T> {
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
/**
* 判断索引是否存在
*
* @param index
* @return
* @throws IOException
*/
public boolean existsIndex(String index) throws IOException {
GetIndexRequest request = new GetIndexRequest(index);
boolean exists = client.indices().exists(request,
RequestOptions.DEFAULT);
return exists;
}
/**
* 创建索引
*
* @param index
* @throws IOException
*/
public boolean createIndex(String index) throws IOException {
CreateIndexRequest request = new CreateIndexRequest(index);
CreateIndexResponse createIndexResponse
= client.indices().create(request, RequestOptions.DEFAULT);
return createIndexResponse.isAcknowledged();
}
/**
* 删除索引
*
* @param index
* @return
* @throws IOException
*/
public boolean deleteIndex(String index) throws IOException {
DeleteIndexRequest deleteIndexRequest = new
DeleteIndexRequest(index);
AcknowledgedResponse response =
client.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
return response.isAcknowledged();
}
/**
* 判断某索引下文档id是否存在
*
* @param index
* @param id
* @return
* @throws IOException
*/
public boolean docExists(String index, String id) throws IOException {
GetRequest getRequest = new GetRequest(index, id);
//只判断索引是否存在不需要获取_source
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
return exists;
}
/**
* 添加文档记录
*
* @param index
* @param id
* @param t 要添加的数据实体类
* @return
* @throws IOException
*/
public boolean addDoc(String index, String id, T t) throws IOException {
IndexRequest request = new IndexRequest(index);
request.id(id);
//timeout
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
request.source(JSON.toJSONString(t), XContentType.JSON);
IndexResponse indexResponse = client.index(request,
RequestOptions.DEFAULT);
RestStatus Status = indexResponse.status();
return Status == RestStatus.OK || Status == RestStatus.CREATED;
}
/**
* 根据id来获取记录
*
* @param index
* @param id
* @return
* @throws IOException
*/
public GetResponse getDoc(String index, String id) throws IOException {
GetRequest request = new GetRequest(index, id);
GetResponse getResponse = client.get(request,
RequestOptions.DEFAULT);
return getResponse;
}
/**
* 批量添加文档记录
* 没有设置id ES会自动生成一个,如果要设置 IndexRequest的对象.id()即可
*
* @param index
* @param list
* @return
* @throws IOException
*/
public boolean bulkAdd(String index, List<T> list) throws IOException {
BulkRequest bulkRequest = new BulkRequest();
//timeout
bulkRequest.timeout(TimeValue.timeValueMinutes(2));
bulkRequest.timeout("2m");
for (int i = 0; i < list.size(); i++) {
bulkRequest.add(new IndexRequest(index)
.source(JSON.toJSONString(list.get(i))));
}
BulkResponse bulkResponse = client.bulk(bulkRequest,
RequestOptions.DEFAULT);
return !bulkResponse.hasFailures();
}
/**
* 批量删除和更新就不写了可根据上面几个方法来写
*/
/**
* 更新文档记录
*
* @param index
* @param id
* @param t
* @return
* @throws IOException
*/
public boolean updateDoc(String index, String id, T t) throws IOException {
UpdateRequest request = new UpdateRequest(index, id);
request.doc(JSON.toJSONString(t));
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
UpdateResponse updateResponse = client.update(
request, RequestOptions.DEFAULT);
return updateResponse.status() == RestStatus.OK;
}
/**
* 删除文档记录
*
* @param index
* @param id
* @return
* @throws IOException
*/
public boolean deleteDoc(String index, String id) throws IOException {
DeleteRequest request = new DeleteRequest(index, id);
//timeout
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
DeleteResponse deleteResponse = client.delete(
request, RequestOptions.DEFAULT);
return deleteResponse.status() == RestStatus.OK;
}
/**
* 根据某字段来搜索
*
* @param index
* @param field
* @param key 要收搜的关键字
* @throws IOException
*/
public void search(String index, String field, String key, Integer
from, Integer size) throws IOException {
SearchRequest searchRequest = new SearchRequest(index);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.termQuery(field, key));
//控制搜素
sourceBuilder.from(from);
sourceBuilder.size(size);
//最大搜索时间。
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
}
}
APIs 测试
测试创建索引:
// 测试索引的创建 Request
@Test
void testCreateIndex() throws IOException {
// 1、创建索引的请求
CreateIndexRequest request = new CreateIndexRequest("kuang_index");
// 2、客户端执行请求 IndicesClient,请求后获得响应
CreateIndexResponse createIndexResponse =
client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
测试获取索引:
// 测试获取索引,判断其是否存在
@Test
void testExistIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("kuang_index2");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
测试删除索引:
// 测试删除索引
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("kuang_index");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
测试添加文档记录:
创建一个实体类User
@Data
@AllArgsConstructor
@NoArgsConstructor
@Component
public class User {
private String name;
private int age;
}
测试添加文档记录
// 测试添加文档
@Test
void testAddDocument() throws IOException {
// 创建对象
User user = new User("狂神说", 3);
// 创建请求
IndexRequest request = new IndexRequest("kuang_index");
// 规则 put /kuang_index/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
// 将我们的数据放入请求 json
request.source(JSON.toJSONString(user), XContentType.JSON);
// 客户端发送请求,获取响应的结果
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
System.out.println(indexResponse.status()); // 对应我们命令返回的状态 CREATED
}
测试:判断某索引下文档id是否存在
// 获取文档,判断是否存在 get /kuang_index/_doc/1
@Test
void testIsExists() throws IOException {
GetRequest getRequest = new GetRequest("kuang_index", "1");
// 不获取返回的 _source的上下文了
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
测试:根据id获取记录
// 获取文档的信息
@Test
void testGetDocument() throws IOException {
GetRequest getRequest = new GetRequest("kuang_index", "1");
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString()); // 打印文档的内容
System.out.println(getResponse); // 返回的全部内容和命令是一样的
}
测试:更新文档记录
// 更新文档的信息
@Test
void testUpdateRequest() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("kuang_index", "1");
updateRequest.timeout("1s");
User user = new User("狂神说Java", 18);
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(updateResponse.status());
}
测试:删除文档记录
// 删除文档记录
@Test
void testDeleteRequest() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("kuang_index", "1");
deleteRequest.timeout("1s");
DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
测试:批量添加文档
// 特殊的,真实的项目一般都会批量插入数据!
@Test
void testBulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
ArrayList<User> users = new ArrayList<>();
users.add(new User("kuangshen1",3));
users.add(new User("kuangshen1",3));
users.add(new User("kuangshen1",3));
users.add(new User("qinjiang1",3));
users.add(new User("qinjiang1",3));
users.add(new User("qinjiang1",3));
// 批处理请求
for (int i = 0; i < users.size(); i++) {
// 批量更新和批量删除,就在这里修改对应的请求就可以了
bulkRequest.add(
new IndexRequest("kuang_index")
.source(JSON.toJSONString(users.get(i)),XContentType.JSON));
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulkResponse.hasFailures()); // 是否失败,返回 false 代表成功!
}
查询测试:
// 查询
// SearchRequest 搜索请求
// SearchSourceBuilder 条件构造
// HighlightBuilder 构建高亮
// TermQueryBuilder 精确查询
// MatchAllQueryBuilder
// xxxQueryBuilder 对应我们刚才看到的所有命令!
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("kuang_index");
// 构建搜索的条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 查询条件,我们可以使用 QueryBuilders 工具类来实现
// QueryBuilders.termQuery 精确
// QueryBuilders.matchAllQuery() 匹配所有
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "qinjiang1");
// MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
System.out.println("=============================");
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
System.out.println(documentFields.getSourceAsMap());
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号