Redis入门02
概述
Redis是什么
Redis:REmote DIctionary Server(远程字典服务器)!
是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
免费和开源!是当下最热门的NoSQL技术之一!也被人们称之位结构化数据库!
Redis能干嘛
1、内存存储和持久化(rdb、aof):redis支持异步将内存中的数据写到硬盘上,同时不影响继续服务
2、效率高,可以用于高速缓存
3、取最新N个数据的操作,如:可以将最新的10条评论的ID放在Redis的List集合里面
4、发布、订阅消息系统
5、地图信息分析
6、定时器、计数器(浏览量!)
......
特性
1、多样的数据类型
2、持久化
3、集群
4、事物
......
学习中需要用到的东西
1、官网:https://redis.io/
2、中文网:http://www.redis.cn/
3、下载地址:通过官网下载即可
注意:Windows在Github上下载(停更很久了!)
Redis推荐都是在Linux服务器上搭建的,我们是基于Linux学习
Windows安装
1、下载安装包:https://github.com/microsoftarchive/redis/releases/tag/win-3.2.100
2、下载完毕得到压缩包

3、解压到自己电脑上的环境目录即可!Redis十分的小,只有5M
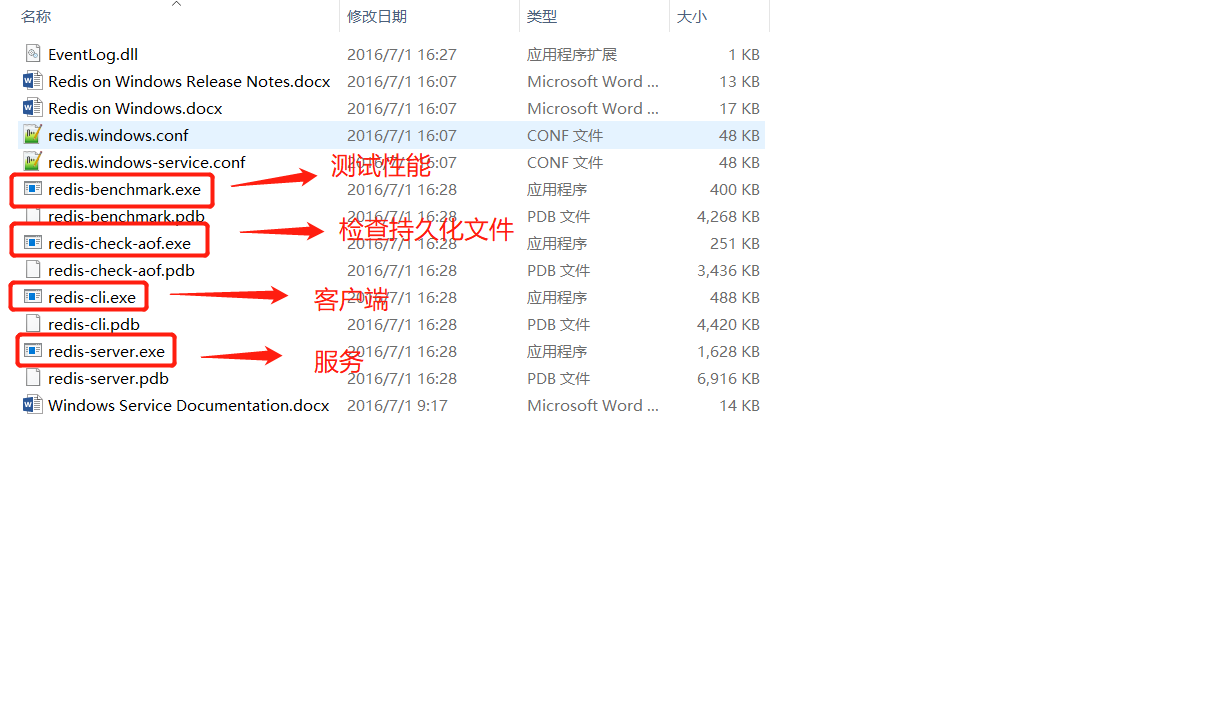
4、双击 redis-server.exe 启动即可
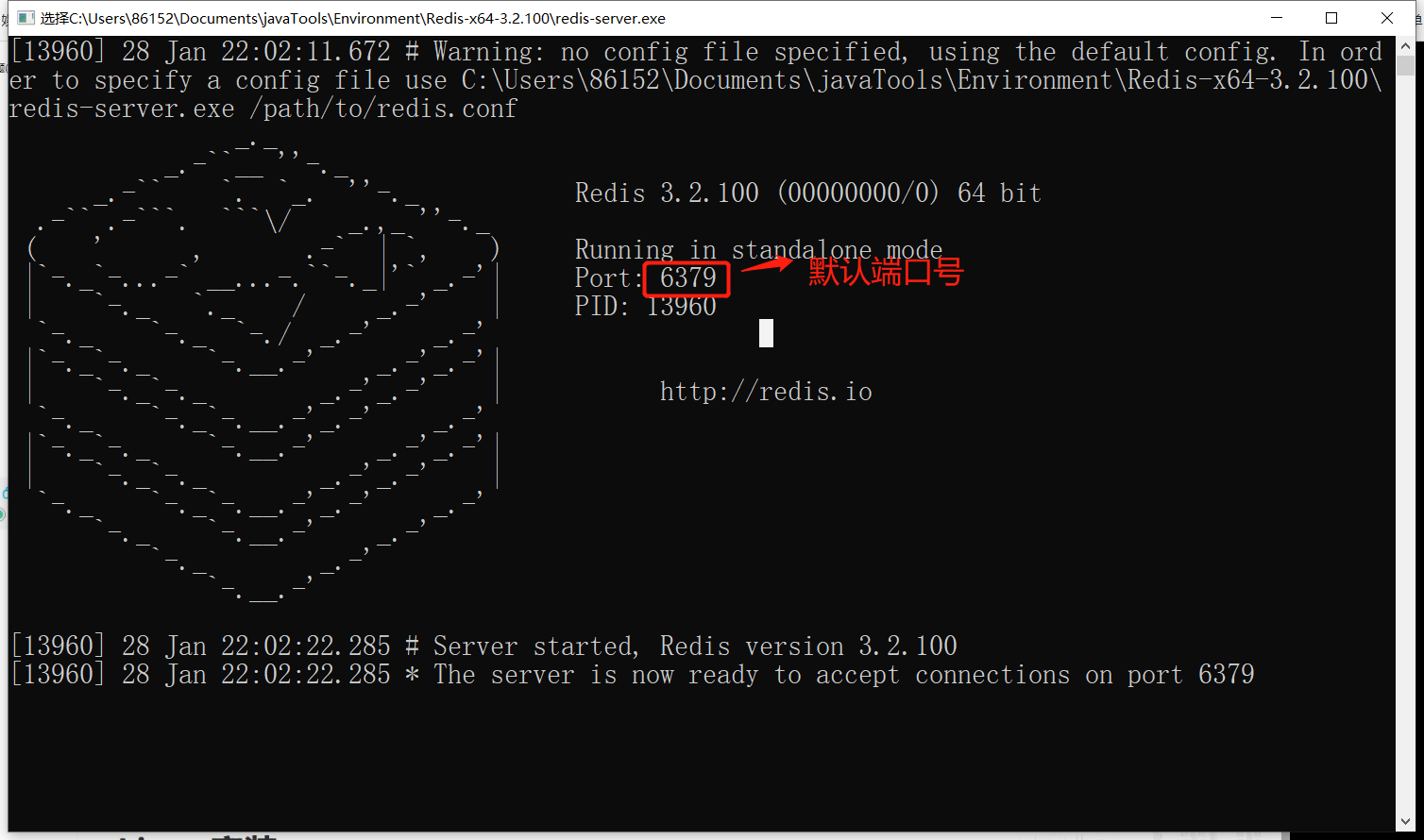
5、通过客户端去访问 redis-cli

重要提示
由于企业里面做Redis开发,99%都是Linux版的运用和安装,几乎不会涉及到Windows版,上一步的讲解只是为了知识的完整性,Windows版不作为重点,大家可以自己玩,企业实战就认一个版:Linux版

Linux安装
下载地址:https://download.redis.io/releases/
安装步骤
1、下载获得 redis-6.2.6.tar.gz 后将它放到我们Linux的目录下 /opt
2、/opt 目录下,解压命令 : tar -zxvf redis-6.2.6.tar.gz
3、解压完成后出现文件夹:redis-6.2.6
4、进入目录: cd redis-6.2.6,可以看到我们redis的配置文件 redis.conf

5、基本的环境安装
# 安装gcc (gcc是linux下的一个编译程序,是c程序的编译工具)
yum install gcc-c++
# 查看版本
gcc -v
# 在 redis-6.2.6 目录下执行 make 命令
二次 make
6、如果make完成后继续执行 make install
7、redis的默认安装目录:usr/local/bin
/usr 这是一个非常重要的目录,类似于windows下的Program Files,存放用户的程序

8、拷贝配置文件(备用)

cd /usr/local/bin
ls -l
# 在/usr/local/bin目录下创建一个文件夹
mkdir myconfig
cp /opt/redis-6.2.6/redis.conf myconfig/# 拷一个备份,养成良好的习惯,我们就修改这个文件
9、redis默认不是后台启动的,修改配置文件!
cd myconfig
# 修改配置保证可以后台应用
vim redis.conf

- A、redis.conf配置文件中daemonize守护线程,默认是NO。
- B、daemonize是用来指定redis是否要用守护线程的方式启动。
daemonize 设置yes或者no区别
- daemonize:yes
- redis采用的是单进程多线程的模式。当redis.conf中选项daemonize设置成yes时,代表开启 守护进程模式。在该模式下,redis会在后台运行,并将进程pid号写入至redis.conf选项 pidfile设置的文件中,此时redis将一直运行,除非手动kill该进程。
- daemonize:no
- 当daemonize选项设置成no时,当前界面将进入redis的命令行界面,exit强制退出或者关闭 连接工具(putty,xshell等)都会导致redis进程退出。
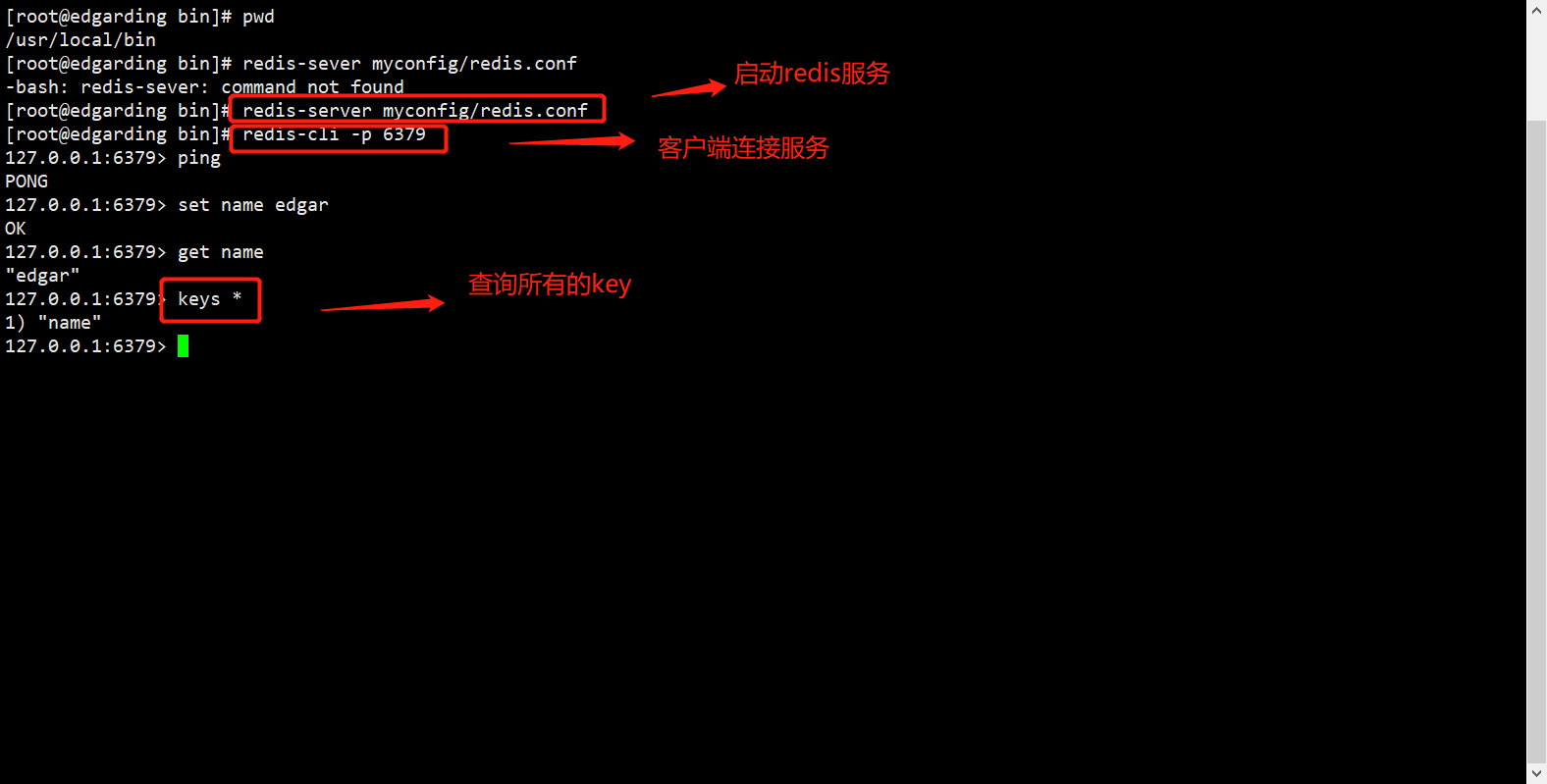
10、启动测试一下!
# 【shell】启动redis服务
[root@edgarding bin]# redis-server myconfig/redis.conf
# redis客户端连接===> 观察地址的变化,如果连接ok,是直接连上的,redis默认端口号 6379
[root@edgarding bin]# redis-cli -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> set name edgar
OK
127.0.0.1:6379> get name
"edgar"
127.0.0.1:6379> keys *
1) "name"
127.0.0.1:6379>
11、查看redis的进程是否开启!ps -ef|grep redis
12、如何关闭redis的服务呢?shutdown 和 exit

13、再次查看进程是否存在 ps -ef|grep redis
14、后面我们会使用单机多redis启动集群测试!
基础知识说明
准备工作:开启redis服务,客户端连接
redis压力测试工具-----Redis-benchmark
Redis-benchmark是官方自带的Redis性能测试工具,可以有效的测试Redis服务的性能。
redis 性能测试工具可选参数如下所示:
| 序号 | 选项 | 描述 | 默认值 |
|---|---|---|---|
| 1 | -h | 指定服务器主机名 | 127.0.0.1 |
| 2 | -p | 指定服务器端口 | 6379 |
| 3 | -s | 指定服务器 socket | |
| 4 | -c | 指定并发连接数 | 50 |
| 5 | -n | 指定请求数 | 10000 |
| 6 | -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 | -P | 通过管道传输 |
1 |
| 10 | -q | 强制退出 redis。仅显示 query/sec 值 | |
| 11 | --csv | 以 CSV 格式输出 | |
| 12 | *-l*(L 的小写字母) | 生成循环,永久执行测试 | |
| 13 | -t | 仅运行以逗号分隔的测试命令列表。 | |
| 14 | *-I*(i 的大写字母) | Idle 模式。仅打开 N 个 idle 连接并等待。 |
# 测试一:100个并发连接,100000个请求,检测host为localhost 端口为6379的redis服务器性
能
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
# 测试出来的所有命令只举例一个!
====== SET ======
100000 requests completed in 1.88 seconds # 对集合写入测试
100 parallel clients # 每次请求有100个并发客户端
3 bytes payload # 每次写入3个字节的数据,有效载荷
keep alive: 1 # 保持一个连接,一台服务器来处理这些请求
17.05% <= 1 milliseconds
97.35% <= 2 milliseconds
99.97% <= 3 milliseconds
100.00% <= 3 milliseconds # 所有请求在 3 毫秒内完成
53248.14 requests per second # 每秒处理 53248.14 次请求
基本数据库常识
默认16个数据库,类似数组下标从零开始,初始默认使用零号库
查看 redis.conf ,里面有默认的配置
databases 16
# Set the number of databases. The default database is DB 0, you can select
# a different one on a per-connection basis using SELECT <dbid> where
# dbid is a number between 0 and 'databases'-1
databases 16
Select命令切换数据库
127.0.0.1:6379> select 3
OK
127.0.0.1:6379[3]>
Dbsize查看当前数据库的key的数量
127.0.0.1:6379> select 3
OK
127.0.0.1:6379[3]> DBSIZE
(integer) 0
127.0.0.1:6379[3]> set name edgar
OK
127.0.0.1:6379[3]> DBSIZE
(integer) 1
127.0.0.1:6379[3]> select 7
OK
127.0.0.1:6379[7]> DBSIZE
(integer) 0
127.0.0.1:6379[7]> get name
(nil)
127.0.0.1:6379[7]> select 3
OK
127.0.0.1:6379[3]> get name
"edgar"
127.0.0.1:6379[3]> keys * # 查看具体的key
1) "name"
清除当前数据库 FLUSHDB
127.0.0.1:6379[3]> FLUSHDB
OK
127.0.0.1:6379[3]> keys *
(empty array)
清除全部数据库的内容 FLUSHALL
127.0.0.1:6379> set name edgar
OK
127.0.0.1:6379> keys *
1) "name"
127.0.0.1:6379> select 3
OK
127.0.0.1:6379[3]> keys *
(empty array)
127.0.0.1:6379[3]> FLUSHALL
OK
127.0.0.1:6379[3]> select 0
OK
127.0.0.1:6379> keys *
(empty array)
为什么默认端口是6379?
6379在是手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字。MERZ长期以来被antirez及其朋友当作愚蠢的代名词。Redis作者antirez同学在twitter上说将在下一篇博文中向大家解释为什么他选择6379作为默认端口号。而现在这篇博文出炉,在解释了Redis的LRU机制之后,向大家解释了采用6379作为默认端口的原因。
为什么redis是单线程
我们首先要明白,Redis很快!官方表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis 的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就 顺理成章地采用单线程的方案了!
Redis采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,由C语言编写,官方提供的数据是 可以达到100000+的QPS(每秒内查询次数)。这个数据不比采用单进程多线程的同样基于内存的 KV 数据库 Memcached 差!
Redis为什么这么快?
1)以前一直有个误区,以为:高性能服务器 一定是多线程来实现的
原因很简单因为误区二导致的:多线程 一定比 单线程 效率高,其实不然!
在说这个事前希望大家都能对 CPU 、 内存 、 硬盘的速度都有了解了! CPU > 内存 > 硬盘
2)redis 核心就是 如果我的数据全都在内存里,我单线程的去操作 就是效率最高的,为什么呢,因为 多线程的本质就是 CPU 模拟出来多个线程的情况,这种模拟出来的情况就有一个代价,就是上下文的切 换,对于一个内存的系统来说,它没有上下文的切换就是效率最高的。redis 用 单个CPU 绑定一块内存 的数据,然后针对这块内存的数据进行多次读写的时候,都是在一个CPU上完成的,所以它是单线程处 理这个事。在内存的情况下,这个方案就是最佳方案。
因为一次CPU上下文的切换大概在 1500ns 左右。从内存中读取 1MB 的连续数据,耗时大约为 250us, 假设1MB的数据由多个线程读取了1000次,那么就有1000次时间上下文的切换,那么就有1500ns * 1000 = 1500us ,我单线程的读完1MB数据才250us ,你光时间上下文的切换就用了1500us了,我还不算你每次读一点数据 的时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号