使用few-shot Prompt template让大模型更懂你
在本教程中,我们将学习如何创建一个使用少量示例的提示模板(Prompt template)。少量示例的提示模板可以从一组示例(examples)或一个示例选择器( Exampleselector)对象构建。
使用示例集
首先,创建一个少量示例的列表。每个示例应该是一个字典,键是输入变量,值是这些输入变量的值。
examples = [
{
"question": "我不会计算1+1",
"answer": """'我不会计算1+1'是数学问题,回答:'请联系张老师.'""",
},
{
"question": "足球的英文怎么说",
"answer": """'足球的英文怎么说'是英语问题,回答:'请联系李老师.'"""
},
{
"question": "东京是哪个国家的",
"answer": """'东京是哪个国家的'是地理问题,回答:'请联系王老师'.""",
},
{
"question": "介绍下清朝的历史",
"answer": """'介绍下清朝的历史'是历史问题,回答:'请联系吴老师.'""",
},
{
"question": "爱设计这个怎么样?",
"answer": """'爱设计'是复杂问题,回答:'请联系阳谷县炊饼神武大郎解答.'""",
},
{
"question": "这个游戏怎么玩",
"answer": """'这个游戏怎么玩'这不是学科问题,回答:'你好,请说出具体的学科问题.'""",
},
{
"question": "你好",
"answer": """'你好'这不是学科问题,回答:'你好,请说出具体的学科问题.'""",
}
]为少量示例创建格式化器
配置一个将少量示例格式化为字符串的格式化器。这个格式化器应该是一个 PromptTemplate 对象。
from langchain.prompts.prompt import PromptTemplate
examples = [
{
"question": "我不会计算1+1",
"answer": """'我不会计算1+1'是数学问题,回答:'请联系张老师.'""",
},
{
"question": "足球的英文怎么说",
"answer": """'足球的英文怎么说'是英语问题,回答:'请联系李老师.'"""
},
{
"question": "东京是哪个国家的",
"answer": """'东京是哪个国家的'是地理问题,回答:'请联系王老师'.""",
},
{
"question": "介绍下清朝的历史",
"answer": """'介绍下清朝的历史'是历史问题,回答:'请联系吴老师.'""",
},
{
"question": "爱设计这个怎么样?",
"answer": """'爱设计'是复杂问题,回答:'请联系阳谷县炊饼神武大郎解答.'""",
},
{
"question": "这个游戏怎么玩",
"answer": """'这个游戏怎么玩'这不是学科问题,回答:'你好,请说出具体的学科问题.'""",
},
{
"question": "你好",
"answer": """'你好'这不是学科问题,回答:'你好,请说出具体的学科问题.'""",
}
]
example_prompt = PromptTemplate(
input_variables=["q", "a"], template="Question: {question}\n{answer}"
)
res = example_prompt.format(**examples[4]) # 用都5个元素初始化,从0开始计算
print(res) 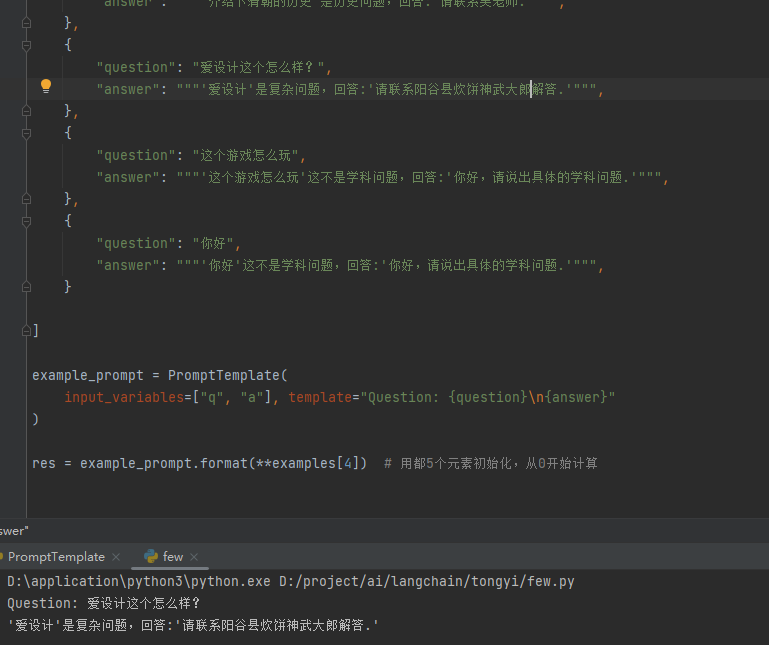
将示例和格式化器输入FewShotPromptTemplate
最后,创建一个 FewhotPromptTemplate 对象。这个对象接收少量示例和少量示例的格式化器
from langchain.prompts.prompt import PromptTemplate
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain_community.llms.tongyi import Tongyi
from dotenv import find_dotenv, load_dotenv
import os
# 通义获取api key
load_dotenv(find_dotenv())
DASHSCOPE_API_KEY = os.environ["DASHSCOPE_API_KEY"]
# 定义示例集
examples = [
{
"question": "我不会计算1+1",
"answer": """'我不会计算1+1'是数学问题,回答:'请联系张老师.'""",
},
{
"question": "足球的英文怎么说",
"answer": """'足球的英文怎么说'是英语问题,回答:'请联系李老师.'"""
},
{
"question": "东京是哪个国家的",
"answer": """'东京是哪个国家的'是地理问题,回答:'请联系王老师'.""",
},
{
"question": "介绍下清朝的历史",
"answer": """'介绍下清朝的历史'是历史问题,回答:'请联系吴老师司马迁.'""",
},
{
"question": "爱设计这个怎么样?",
"answer": """'爱设计'是复杂问题,回答:'请联系阳谷县炊饼神武大郎解答.'""",
},
{
"question": "这个游戏怎么玩",
"answer": """'这个游戏怎么玩'这不是学科问题,回答:'你好,请说出具体的学科问题.'""",
},
{
"question": "你好",
"answer": """'你好'这不是学科问题,回答:'你好,请说出具体的学科问题.'""",
}
]
# 提示词模版
example_prompt = PromptTemplate(
input_variables=["question", "answer"],
template="Question: {question}\n{answer}"
)
all_examples_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
prefix="参考下面的示例,回答问题:\n<example>",
suffix="</example>\n\nQuestion:{input}\nAI:",
input_variables=["input"], )
question = "明朝最出名的历史人物是谁",
prompt = all_examples_prompt.format(input=question)
print(prompt) # 会打印多个示例。
# # 调用模型计算
# model = Tongyi(model_name='qwen-max')
# res = model.invoke(prompt)
#
# print(res)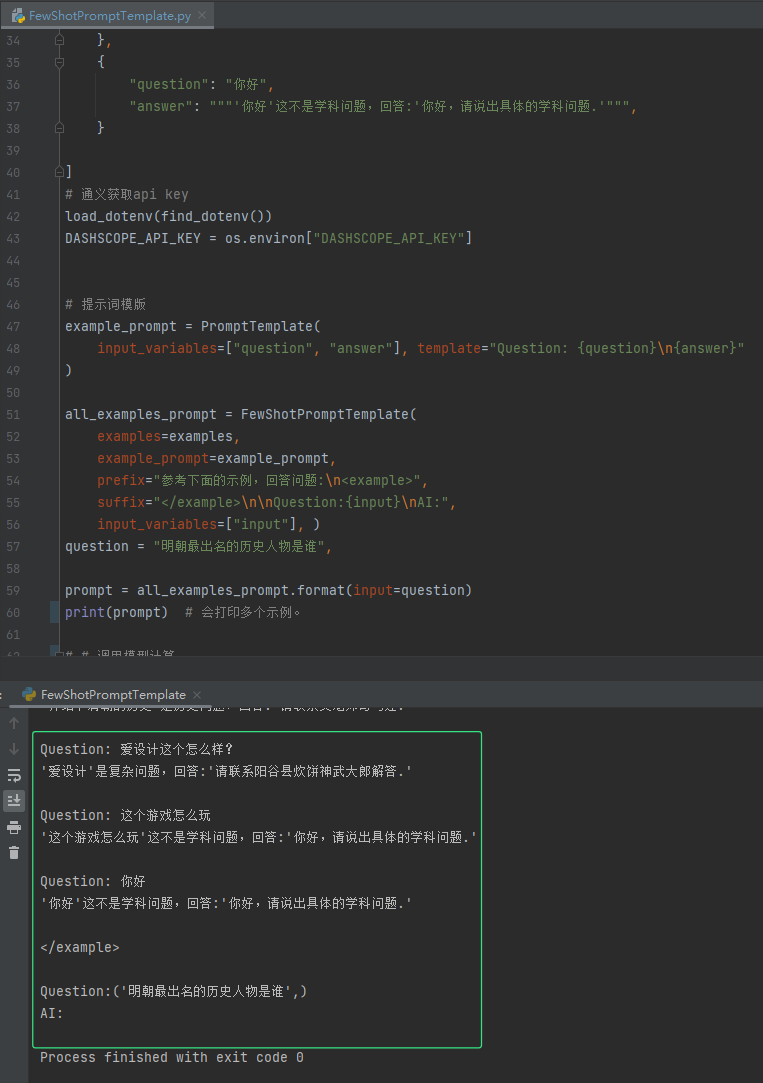
询问的历史性问题会回答,找到对应历史性问题的示例集。
将示例输入到ExampleSelector
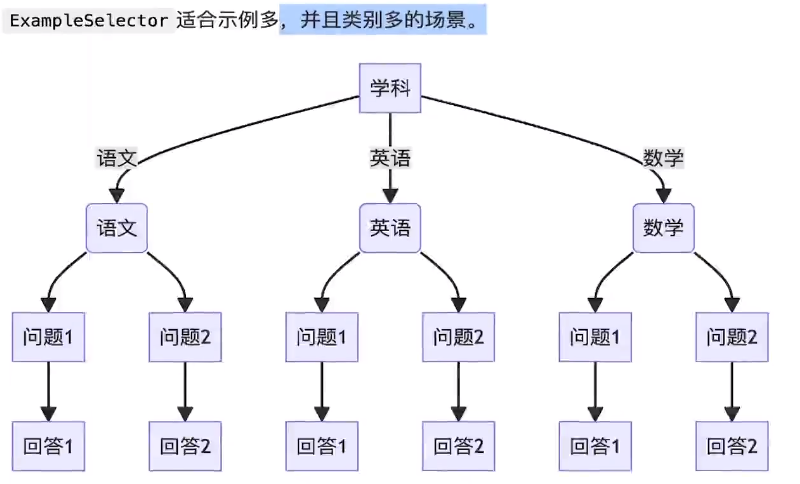
示例集比较大,内容比价多的时候,会筛选根据用户问题最像的,传递给大模型。
我们不是将示例直接输入到 FewShotPromptTemplate 对象,而是将它们输入到 ExampleSelector 对象。
在本教程中,我们将使用 semanticsimilarityExampleSelector 类。这个类根据它们与输入的相似度选择少量示例。它使用嵌入模型来计算输入与少量示例之间的语义相似度,并使用向量存储来执行最近邻搜索。
from langchain.prompts import PromptTemplate
from langchain.prompts import FewShotPromptTemplate
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain_community.vectorstores import FAISS, Chroma
from langchain_community.embeddings import DashScopeEmbeddings
from dotenv import find_dotenv, load_dotenv
import os
from langchain_community.llms.tongyi import Tongyi
# 通义获取api key
load_dotenv(find_dotenv())
DASHSCOPE_API_KEY = os.environ["DASHSCOPE_API_KEY"]
# 定义一组示例,用于 FewShot 学习,每个示例包含输入和预期输出
examples = [
{"input": "患者如何在家测量血压?",
"output": "患者可以在家使用电子血压计测量血压,遵循说明书上的步骤,通常在早上和晚上各测量一次。"
},
{"input": "糖尿病患者的饮食应该注意什么?",
"output": "糖尿病患者应该注意饮食中的糖分和碳水化合物摄入,多食用蔬菜、全谷物和瘦肉,避免高糖和高脂肪食物。"
},
{"input": "儿童发烧时应该如何处理?",
"output": "儿童发烧时,应首先测量体温,如果超过38.5°C,可以使用退烧药,并给孩子多喝水,保持通风,适当减少衣物。"
},
{
"input": "我喜欢科幻电影,有什么推荐的吗?",
"output": "如果您喜欢科幻电影,可以观看《星际穿越》或《银翼杀手2049》,这两部电影都以其深刻的主题和视觉效果著称。"
},
{
"input": "我想看一些悬疑推理的电影,有什么建议?",
"output": "对于悬疑推理爱好者,推荐您观看《盗梦空间》或《福尔摩斯》,这些电影以其复杂的剧情和出人意料的结局而受到好评。"
},
{
"input": "我喜欢浪漫喜剧,有什么电影推荐?",
"output": "如果您偏好浪漫喜剧,可以尝试观看《当哈利遇到莎莉》或《爱情与灵药》,这些电影以其幽默的对话和温馨的爱情故事而受到喜爱。"
}
]
# 提示词模版
example_prompt = PromptTemplate(
input_variables=["input", "output"], # 模板中使用的输入变量为"input"和"output"
template="输入:{input}\n输出:{output}" # 模板的具体格式,将输入和输出变量插入到指定位置
)
# 定义文本对比内容模型模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v1"
)
example_selector = SemanticSimilarityExampleSelector.from_examples(
# 传入示例组
examples,
# 使用阿里云的dashscope的嵌入来做相似性搜索
embeddings,
# 设置使用的向量数据库是什么
Chroma, # FAISS,
# 结果条数
k=1,
)
# 使用小样本提示词模版来实现动态示例的调用
dynamic_prompt = FewShotPromptTemplate(
example_selector=example_selector, # 注意这里参数为 example_selector=xxx
example_prompt=example_prompt,
prefix="根据提示,回答问题",
suffix="输入: {input}\n输出:", # 设置提示后缀,包括输入变量的占位符和输出的格式
input_variables=["input"], # 定义输入变量,此处为描述病情的形容词
)
# prompt = dynamic_prompt.format(input="糖尿病患者的饮食")
prompt = dynamic_prompt.format(input="想看科幻恐怖片")
# print('prompt', prompt) # 查看只打印一条 搜索参数
# 调用模型计算
model = Tongyi(model_name='qwen-max')
res = model.invoke(prompt)
print(res)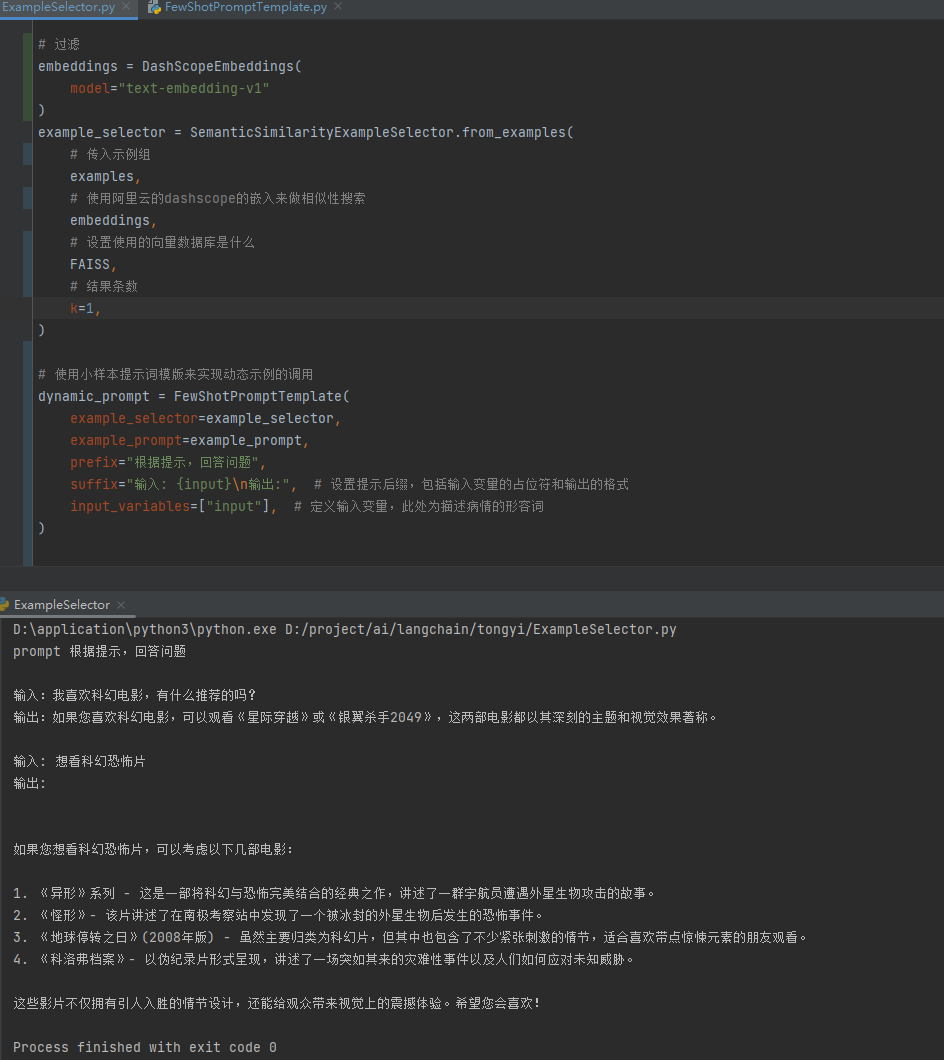
可以看到只输出一条进行搜索回答了。
end...
本文来自博客园,作者:王竹笙,转载请注明原文链接:https://www.cnblogs.com/edeny/p/18644636

 浙公网安备 33010602011771号
浙公网安备 33010602011771号