大模型你得知道它
语言建模(Language Model,LM)
语言建模是提高机器语言智能的主要方法之一。一般来说,LM旨在对词序列的生成概率进行建模,以预测未来失)tokens的概率。
统计语言模型-->神经语言模型-->预训练语言模型-->大模型 统计语言模型(Statistical Language Model,SLM)
基于统计学习方法开发,例如根据最近的上下文预测下一个词。统计语言模型的一个经典例子是n-gram模型。在n-gram模型中,一个词出现的概率只依赖于它前面的n-1个词。
例如,一个三元模型(trigram model)会使用以下的公式来计算序列中某个词的概率:
[ P(w_i | w_{i-2}, w_{i-1}) ]
这里只考虑了前两个词对第三个词出现概率的影响。神经语言模型(Neural Language Model,NLM)
是使用神经网络来预测词序列的概率分布的模型。与传统的统计语言模型(如n-gram模型)使用固定窗口大小的词来预测下一个词的概率不同,神经语言模型可以考虑更长的上下文或整个句子的信息。
循环神经网络(RNN):包括LSTM和GRU等变体,能够处理变长的序列数据。
分布式表示:在神经语言模型中,每个单词通常被编码为一个实数值向量,这些向量也被称为词嵌入(wordembeddings)。词嵌入可以捕捉词与词之间的语义和语法关。预训练语言模型(Pre-trained Language Model,PLM)
这些模型通常在大规模无标签语料库上进行预训练任务,学习词汇、短语、句子甚至跨句子的语言规律和知识。通过这种预训练,模型能够捕获广泛的通用语义特征,然后可以在特定任务上进行微调(fine-tuning),以适应特定的应用场景。
Transformer
2017年在论文《Attention Is All You Need》提出的Transformer,Transformer模型通过其自注意力机制和高度的并行化能力,极大地提高了序列处理任务的效率和效果,它能够在处理序列数据时捕捉全局依赖关系,同时具有并行计算的能力,是近年来自然语言处理领域的重要进展之一。- 自注意力机制
- 并行化能力
大语言模型(Large Language Models,LLM)
大语言模型(大模型)是指那些具有大量参数、在大规模数据集上训练的语言模型。这些模型能够理解和生成自然语言,通常是通过深度学习和自注意力机制(如Transformer架构)实现的。它们在自然语言处理(NLP)的多个领域都有广泛的应用,包括但不限于文本生成、翻译、摘要、问答和对话系统。大语言模型通常有数十亿甚至数万亿个参数。例如,GPT-3拥有1750亿个参数。大模型应用
ChatGPT
BERT vs GPT
BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pretrained Transformer)都是基于Transformers的架构.
BERT (Bidirectional Encoder Representations from Transformers)
BERT是由Google Al在2018年提出的一种预训练语言表示模型。它的主要特点是双向的Transformer编码器。这意味着BERT在处理一个单词时,会同时考虑这个单词前面和后面的上下文,这种全方位的上下文理解使得BERT在理解语言时更为精准。
预训练
我喜[MASK]跑步应用示例:
BERT非常适合用于理解单个文本或者文本对的任务,比如:
情感分析:判断一段文本的情感倾向是正面还是负面。问答系统:给定一个问题和一段包含答案的文本,BERT可以帮助找到文本中的答案。命名实体识别(NER):从文本中识别出特定的实体,如人名、地点、组织名等。
GPT (Generative Pretrained Transformer)GPT (Generative Pretrained Transformer)
GPT由OpenAI提出,是一种基于Transformer的预训练语言生成模型。与BERT不同,GPT使用的是单向的Transformer解码器。它在处理文本时主要关注当前单词之前的上下文,这使得GPT在生成连贯文本方面表现出色。
预训练
我
我喜
我喜欢
我喜欢跑
我喜欢跑步应用示例:
GPT可以应用于任何需要生成文本的场景,比如:
文本生成:生成新闻文章、故事、代码等。
机器翻译:将一种语言的文本翻译成另一种语言。
摘要生成:从一篇长文中生成摘要。
大模型特点
参数数量庞大:大模型通常含有极多的参数,这些参数是模型在训练过程中学习到的权重和偏置。
数据需求巨大:为了训练这些模型,需要大量多样化的数据。数据的多样性可以帮助模型更好地泛化到未见过的情况。·
计算资源密集:训练大模型需要大量的计算资源,这通常依赖于高性能的GPU或TPU集群。·
泛化能力强:由于模型参数众多,大模型通常具有更好的学习能力和泛化能力。·
迁移学习效果佳:大模型在一个任务上训练好之后,可以通过迁移学习的方式快速适应新的任务。
大模型问题
幻觉:幻觉是指LLM生成的输出是错误的,胡编乱造。比如“钢丝球炒西红柿”,由于大语言模型会预测下一个语法正确的字词或短语,因此并不能完全解读人类的意思。这导致有时会产生所谓的“幻觉”。·
资源消耗:训练大模型需要消耗大量的电力和计算资源,这带来了环境和经济成本。·
数据偏见:训练数据的代表性不足可能导致模型继承并放大现实世界的偏见和不平等。·
可解释性差:大模型的决策过程往往是黑箱的,难以解释和理解。·
安全性问题:大模型可能被用于生成假新闻、欺诈性内容等,引发安全和道德问题。
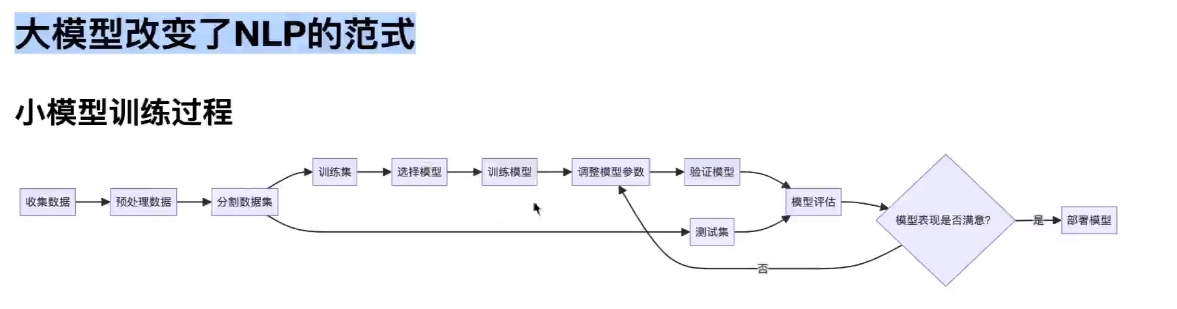
大语言模型与AIGC之间的区别?
AlGC(Artificial Intelligence Generated Content)是一个总称,是指有能力生成内容的人工智能模型。IAIGC可以生成文本、生成代码、生成图像、视频和音乐。
热门的开源AIGC技术:LLaMA、Stable Diffusion
大模型也是一种AIGC,它基于文本进行训练并生成文本内容。
可以看看 OPENAI GPT 发展史
本文来自博客园,作者:王竹笙,转载请注明原文链接:https://www.cnblogs.com/edeny/p/18615362

 浙公网安备 33010602011771号
浙公网安备 33010602011771号