GPU服务器配置cuda和cudnn计算密集型任务的加速
一、命令行安装
进入虚拟环境
conda activate py3.8
# 卸载
sudo apt-get remove --purge nvidia*
sudo apt autoremove
# 安装 sudo apt-get install nvidia-driver-515
有些显卡只支持455
版本对比
https://blog.csdn.net/K1052176873/article/details/114526086
# 查看安装后的显卡版本
ls /usr/src | grep nvidia
安装完成记得重启一下,然后验证一下:
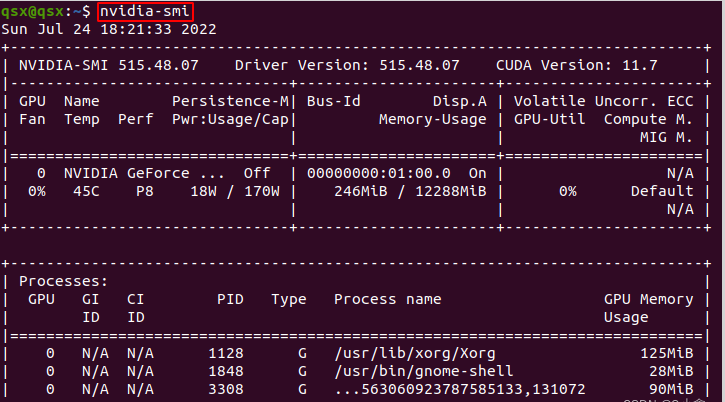
nvidia-smi
若显示下图则说明安装成功~
二、安装CUDA
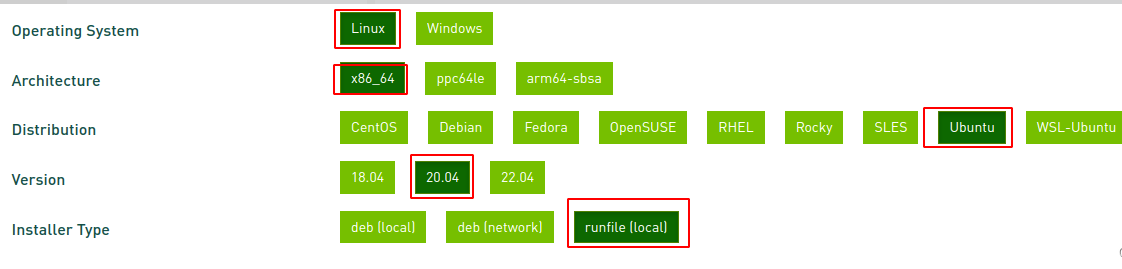
下载地址:https://developer.nvidia.cn/cuda-downloads
选择Linux->x86_64->Ubuntu->20.04->runfile(local)
wget https://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda_11.7.0_515.43.04_linux.run
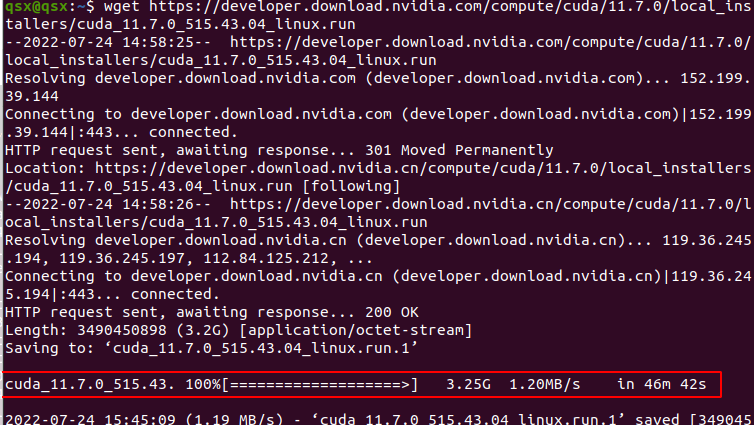
等待30m即可(取决于网速)
三、安装cuda
sudo sh cuda_11.7.0_515.43.04_linux.run
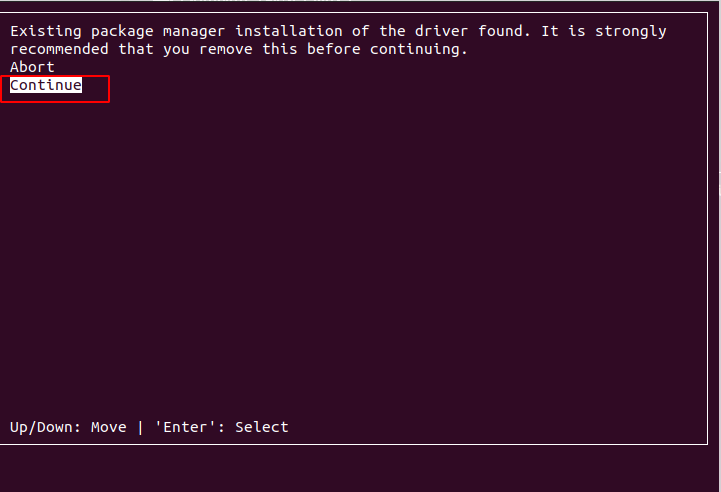
选择Continue(上下移动选择,Enter确定)
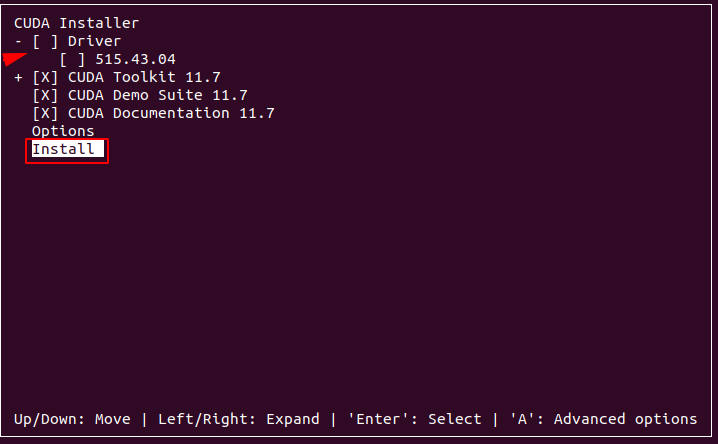
在对应的选项上空格,然后移动到Install,显示如下就表示安装成功了!
配置环境变量
vim ~/.bashrc
export PATH=$PATH:/usr/local/cuda/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64 export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda/lib64
source ~/.bashrc
查看版本显示
nvcc -V
四、安装cudnn
下载地址:https://developer.nvidia.com/rdp/cudnn-archive
cudnn-local-repo-ubuntu2004-8.6.0.163_1.0-1_amd64
安装
sudo apt-get install zlib1g # 可以看官方文档 sudo dpkg -i cudnn-local-repo-ubuntu2004-8.6.0.163_1.0-1_amd64.deb # 安装完之后执行 sudo cp /var/cudnn-local-repo-ubuntu2004-8.6.0.163/cudnn-local-B0FE0A41-keyring.gpg /usr/share/keyrings/ sudo apt-get update # 进入安装目录 cd /var/cudnn-local-repo-ubuntu2004-8.6.0.163/ sudo apt-get install libcudnn8=8.6.0.163-1+cuda11.8 sudo apt-get install libcudnn8-dev=8.6.0.163-1+cuda11.8 sudo apt-get install libcudnn8-samples=8.6.0.163-1+cuda11.8
测cudnn
cp -r /usr/src/cudnn_samples_v8/ $HOME cd $HOME/cudnn_samples_v8/mnistCUDNN make clean && make ./mnistCUDNN
重要:cd /usr/local/cuda/lib64 拷贝对应的so 名称
例: sudo cp libcufft.so.10.0 libcufft.so.10
五、安装
# ubuntu20
pip3 install tensorflow==2.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
测试python3文件


import tensorflow as tf a = tf.test.is_built_with_cuda() # 判断CUDA是否可以用 b = tf.test.is_gpu_available( cuda_only=False, min_cuda_compute_capability=None ) # 判断GPU是否可以用 print(a) print(b)
import os import time os.environ["CUDA_VISIBLE_DEVICES"] = "0,1" import tensorflow as tf cifar = tf.keras.datasets.cifar10 (x_train, y_train), (x_test, y_test) = cifar.load_data() model = tf.keras.applications.VGG16( include_top=True, weights=None, input_shape=(32, 32, 3), classes=100,) start = time.time() loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False) model.compile(optimizer="adam", loss=loss_fn, metrics=["accuracy"]) model.fit(x_train, y_train, epochs=1, batch_size=512) print(">>>>> use time:", time.time()-start)
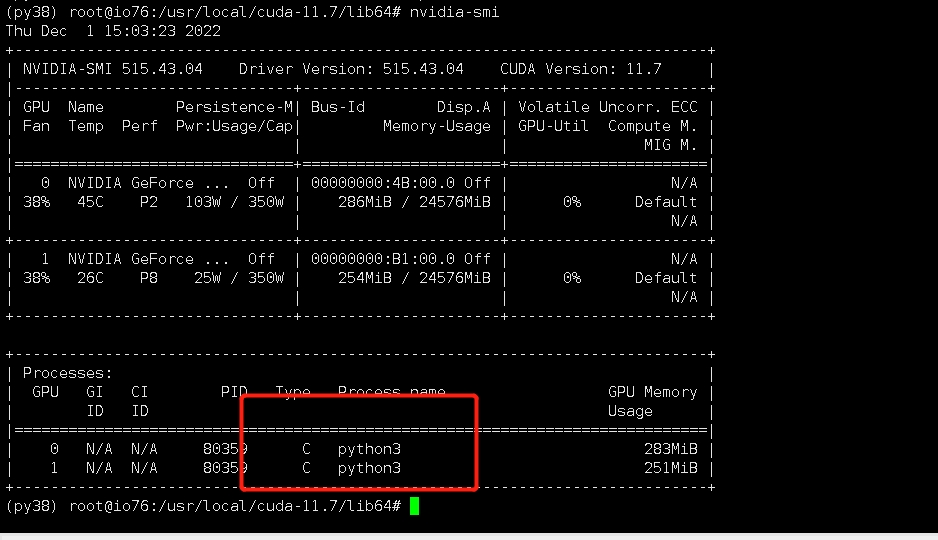
在次查看已有python项目
nvidia-smi
本文来自博客园,作者:王竹笙,转载请注明原文链接:https://www.cnblogs.com/edeny/p/16942858.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号