Loki日志聚合分析系统-docker-compose
一、说明
Grafana Loki 是什么?
Loki 是一个水平可扩展,高可用性,多租户的
日志聚合系统 。它的设计非常经济高效且易于操作,因为它不会为日志内容编制索引,而是为每个日志流编制一组标签。Loki 组成:
- loki : 主服务器,负责存储日志和处理查询
- promtail : 代理,负责收集日志并将其发送给 loki
- Grafana : Go语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能
Loki : https://github.com/grafana/loki
二、docker-compose
本文以一台centos 7.6主机来演示一下loki,ip地址为:192.168.31.229
Docker-compose.yml 可以参考Loki的文档介绍。
创建目录/opt/loki,文件结构如下:


version: "3" networks: loki: services: loki: image: grafana/loki:latest ports: - "3100:3100" networks: - loki promtail: image: grafana/promtail:latest container_name: promtail_dongjian restart: unless-stopped volumes: - ./promtail:/etc/promtail #- ./log:/var/log command: -config.file=/etc/promtail/config.yml networks: - loki grafana: image: grafana/grafana:master ports: - "3000:3000" networks: - loki
promtail 配置
server: http_listen_port: 9080 grpc_listen_port: 0 positions: filename: /tmp/positions.yaml clients: - url: http://loki:3100/loki/api/v1/push scrape_configs: - job_name: system static_configs: - targets: - localhost labels: job: varlogsd1 host: djhost1 __path__: /var/log/*log - job_name: dongjiansystem static_configs: - targets: - localhost labels: job: dongjian1 host: djhost2 __path__: /var/log/*log
四、运行一个java小程序测试日志
新建 docker-compose.yml
温馨小提示:
- 这是个定时打印日志任务的java小程序;
- 该文件需与上面安装loki的
docker-compose-grafana-promtail-loki.yml文件在同一级,目的:同步java程序的日志到promtail日志采集端,当然这里也可以通过将promtail放到容器中去采集日志
- java程序,log-demo.yaml
version: '3' services: log-demo: image: harbor.insightone.cn/insightlog/insightlog/log-demo:v1.0.1 container_name: log-demo volumes: - ./grafana_promtail_loki/logs:/var/log ports: - "88:88"
运行程序
docker-compose up -d
目录结构
四、Grafana Loki 配置
访问地址:
http://127.0.0.1:3000 默认登录账号密码:admin/admin配置loki数据源
填写loki地址:
http://loki:3100保存成功后,选择
Explore这里选择以文件名的方式查看日志信息
五,选择器
于查询表达式的标签部分,将其包装在花括号中{},然后使用键值对的语法来选择标签,多个标签表达式用逗号分隔,比如:
{app="mysql",name="mysql-backup"}
目前支持以下标签匹配运算符:
=等于!=不相等=~正则表达式匹配!~不匹配正则表达式
比如:
{name=~"mysql.+"}
{name!~"mysql.+"}
适用于Prometheus标签选择器规则同样也适用于Loki日志流选择器。
六、过滤器
编写日志流选择器后,您可以通过编写搜索表达式来进一步过滤结果。搜索表达式可以只是文本或正则表达式。 查询示例:
{job="mysql"} |= "error"
{name="kafka"} |~ "tsdb-ops.*io:2003"
{instance=~"kafka-[23]",name="kafka"} != kafka.server:type=ReplicaManager
过滤器运算符可以被链接,并将顺序过滤表达式-结果日志行将满足每个过滤器。例如:
{job="mysql"} |= "error" != "timeout"
已实现以下过滤器类型:
- |= 行包含字符串。
- != 行不包含字符串。
- |~ 行匹配正则表达式。
- !~ 行与正则表达式不匹配。 regex表达式接受RE2语法。默认情况下,匹配项区分大小写,并且可以将regex切换为不区分大小写的前缀(?i)。
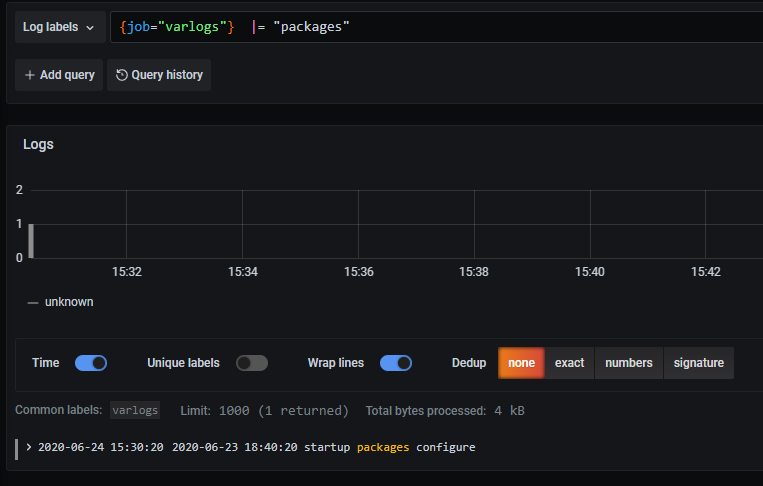
举例,我需要查询包含关键字packages
{job="varlogs"} |= "packages"
本文来自博客园,作者:王竹笙,转载请注明原文链接:https://www.cnblogs.com/edeny/p/16903360.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号