
RefineNet
论文信息
Shifeng Zhang, Longyin Wen, Xiao Bian, Zhen Lei, Stan Z. Li. Single-Shot Refinement Neural Network for Object Detection. CVPR2018.
前言
本来打算下SSOD的结果看错, 最后阴差阳错地下下来, 看了不少发现不是, 但是既来之则安之, 我们就把它讲一讲吧.
本文希望继承one stage和two stage的优点, 并克服其缺点, 本文主要做了以下两件事:
- 在proposal阶段预先筛选出bg, 其实就是anchor的功能.
- 先用anchor获取粗略的location和size而不是用selective search等方法获得低质量的proposal, 其后送入后层classification和regression模块中.
如此看来, 本文就是在当时流行的object detection方法中加入了anchor二次预测, 另外本文也利用了SSD的多层次feature map合作分类思想.
我还想讲一下我的关于语义看法:
我认为卷积层数越深其从对纹理的表现越差, 对语义信息的表现越好, 当然深度越深尺寸越小其同样尺寸box内感受野也更大, 也更容易对大型物体识别. 因此深层网络除了scale问题, 我还想加入我对语义的理解.
Introduction
作者提到two stage时用了一个词sparse形容candidate object box我觉得让我觉得优点耳目一新的感觉, 确实two stage因为有一个预binary classification用于区分bg与fg, 那么与one stage直接输入若干box相比, 用sparse形容确实有一定概括性. 这里也引申先前我们提过多次的class imbalance问题, 在此我们就不再重复解释了.
作者受two stage的顺序级联结构启发设计以下结构:
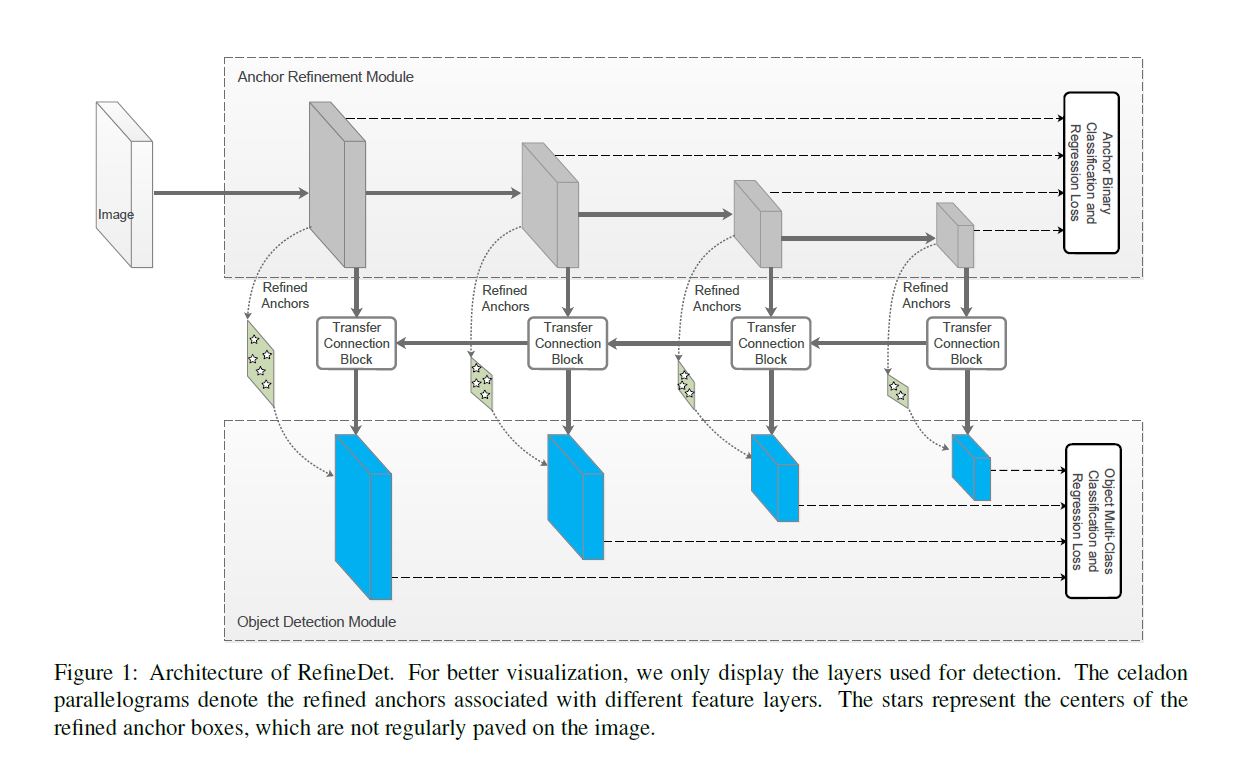
本结构的构建目的在前言已经提过, 我们重点分析一下结构.
首先我们可以看见途中有两个沟通上下两结构的connection:
- 一个是通过resample使特征图相连.
- 另一个是借助transfer connection block(TCB for short)与后层相连.
这样做主要是使二者沟通且能使下层(Object Detection Module, ODM for short)继承上层(Anchor Refinement Module, ARM for short)的一些好的属性.
我想指出的是, 下层其实是一个one stage的典型应用, 上层是two stage中常见的anchor为主要元素, 这样就实现作者所说的既有one stage速度又有two stage的anchor预分类预回归优势.
Network Architecture
本文的RefineDet是基于SSD式输出bbox和score最后用NMS修正的模型.
ARM是由移除classification并加入两个网络(本文是VGG-16和ResNet-101)的auxiliary structure构成的.
ODM是由TCB后接prediction层(如卷积核为3的卷积层), 此层最终输出score和bbox coordinate.
这样我们将结构主要总结为以下几点:
- 从TCB的输入将ARM的输出送入ODM.
- 前后进行两步regression使位置更精准.
- 预先筛选bg以避免按imbalance的麻烦.
Transfer Connection Block
对于TCB的连接功能来说, ARM只使用TCB在anchor对应的feature map对应.
TCB还有另一个功能是整合多层次的feature map以提高预测的准确率. 为了使不同层的feature map组合相匹配, 作者先对高层次小尺寸的map反卷积使其扩大, 其后将其相加. 之后紧跟一个卷积层来保证容易分类, 其具体网络结构如下图:
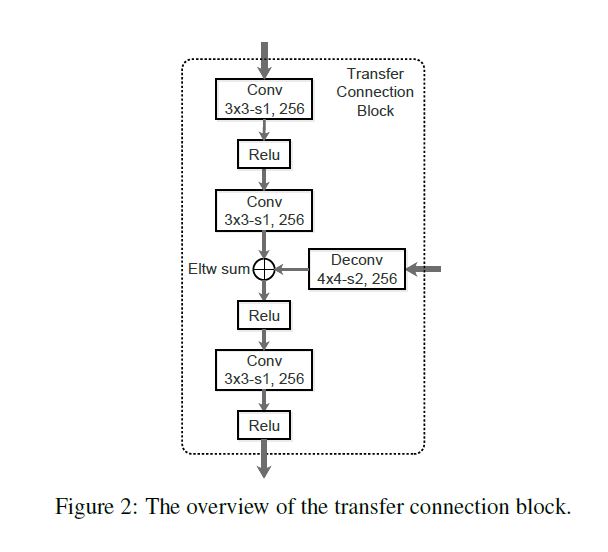
Two-Step Cascaded Regression
此前的one stage方法都是在不同scale来预测各类信息, 这样做不够精确, 在小物体上表现更差.
本文改进的具体方法如下:
首先设置每个cell产生anchor box的个数\(n\), 每个box与cell的初始相对位置都是固定的, 每个box都预测四个我们所熟知的regression参数和两个关于是bg还是fg的score.
当我们获得了初调的box后, 我们将其输出的feature map送入ODM中来进一步确定class, location, size信息(预测信息).
ARM与ODM输出的预测信息是想同维度的(c + 4).
利用多层次信息的思想来自SSD, 但这里和SSD还是有一定不同的, SSD是直接将原始的box生成的不同层次特征图整合到一起预测, 而本文是用ARM预调整, ODM精修的结果整合后预测, 这样大大提高了准确率, 尤其是对于小物体表现提升较大.
Training and Inference
Data Augmentation
本文随机扩大或剪切原始图像并进行了随机扭曲或是翻转.
Backbone Network
之前提到过使用魔改VGG-16和ResNet-101作为backbone, 其后因为conv4_3和conv5_3的scale不同而对其进行L2 normalization以使他们的scale变为10和8. 其次, 为获取高语义层次信息并利用不同scale的信息, 作者又加了两个卷积层和一个残差层.
Anchor Design and Matching
每一层由不同的stride从backbone生成, 每一层的scale都与其对应的anchor size相关(e.g. scale等于anchor size的4倍), 并且有三个长宽比.
作者借用\(\text{S}^3\)D中的方法使不同scale的anchor在最终整合时density相同.
Hard Negative Mining
设置negative: positive = 3: 1.
Loss Function
由ARM和ODM共同贡献loss, 对ARM只进行binary classification, 最终loss为:
其中\(i\)是序号, \(l_i^*\)是ground truth的class label, \(g_i^*\)是位置信息和尺寸信息, \(p_i, x_i\)是ARM预测的class和位置尺寸, \(c_i, t_i\)是ODM预测的class和位置尺寸.\(N_{arm}, N_{odm}\)分别是ARM和ODM中positive example个数. \(L_b, L_m\)分别是二值交叉熵和多值softmax损失. 对于regression loss本文使用L1.
Inference
在推理阶段, 首先ARM丢弃低于阈值的negative examples, 其后对剩下的anchor正向传播, 再将其输入至ODM继续正向传播, 将最终输出保留top 400 score detection. 最终利用NMS以阈值0.45压缩并保留top 200生成结果.
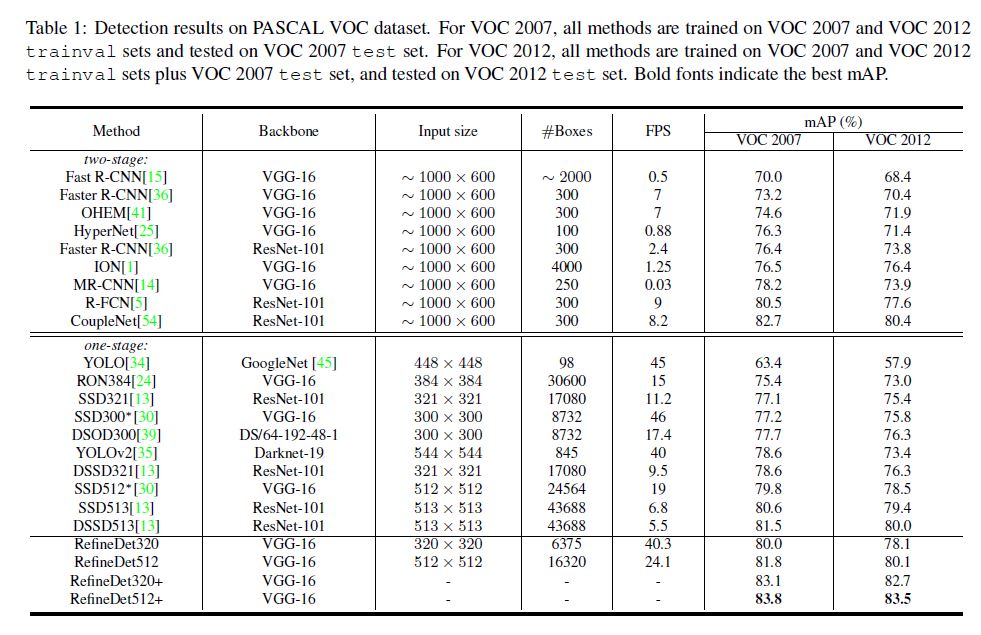
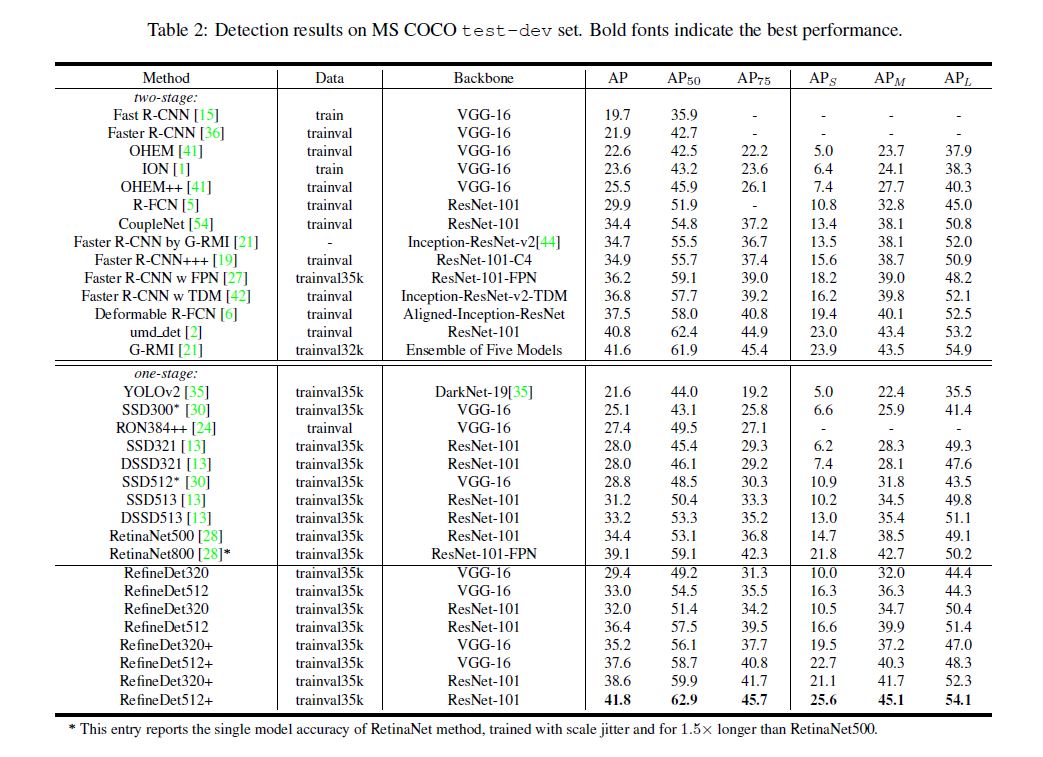
Experiments
没什么特别想提的, 直接上图, 很直观:

Conclusion
其实就是干了搬砖的活, 但是搬好砖也能发CVPR, 哭了哭了...


 浙公网安备 33010602011771号
浙公网安备 33010602011771号