
YOLOv3
论文信息
Joseph Redmon, Ali Farhadi. YOLOv3: An Incremental Improvement. Tech report.
https://arxiv.org/abs/1804.02767
前言
本文是作者百忙之中于2018年四月更新(YOLOv2是2016年12月发布), 值得注意的是本文并不是一篇journal or conference paper, 只是一篇tech report形式的文章, 因此作者行文时时常出现口语化文字, 且有一些猜想更为大胆或是未验证的写了上来, 还写了作者试验过不能取得效果的方法, 另外作者也没有花十分多的时间来设计和进行实验.
总之, 此文章不太"八股", 读起来有一些新鲜的感觉.
The Deal
作者从Reddit, Email在这一年半的时间获取了若干建议, 最终应用下来构建了新的classifier.
Bounding Box Prediction
bbox是在YOLOv2的基础上改进的, 我直接将其定义复制过来并不会将原始内容复述, 不熟悉的朋友可以看我上一篇的介绍. 其定义如下:
如果ground truth的coordinate prediction为\(\hat{t}_*\), 作者将梯度定义为\(\hat{t}_* - t_*\), 这样就十分容易计算.
本文的一个重要创新是每个bbox用logistics regression预测objectness score(是否存在物体的score). 如果一个bbox与ground truth的IOU比其他的bbox都大, 那么这个数值应为1, 同时如果一个bbox与ground truth的IOU没有最大, 但是其高于某个阈值(本文为0.5), 那么同样把他留下. 这样的话一个物体就可能对应多个bbox, 当然如果bbox达不到阈值, 那么我们就不会在反向传播时计算它的loss.
Class Prediction
每个bbox可能不止包含了一种物体, 作者放弃使用softmax, 使用logistic classifier和binary cross-entropy loss来预测和训练.
原因我们曾经提过, softmax假定送入的内容都是不相干, 对于有很多重叠的数据集, 这种多标签方法才是最合适的.
Predictions Across Scales
作者bbox预测3个不同的scale, 利用FPN的思想(我以后也许会讲一下, 简单来说就是利用不同深度网络层输出feature map来获得semantic & grained 都丰富的综合信息.), 添加了数个卷积层, 并在最后输出了一个三维张量, 此向量包含了bbox, objectness and class predictions信息, e.g. 在COCO上有80个class, 那么输出的张量是\(N \times N \times [3 * (4 + 1 + 80)]\)式的张量.
作者利用新加入的每一层的feature map, 对于不同尺寸的进行上采样, 最终组合后得到了新的张量大概比上一版本输出feature map大了一倍.
同样作者还使用k-means来决定使用box的数量尺寸.
Feature Extractor
作者在原来的Darknet-19的基础上构建了新的Darknet-53, 详情如下图:
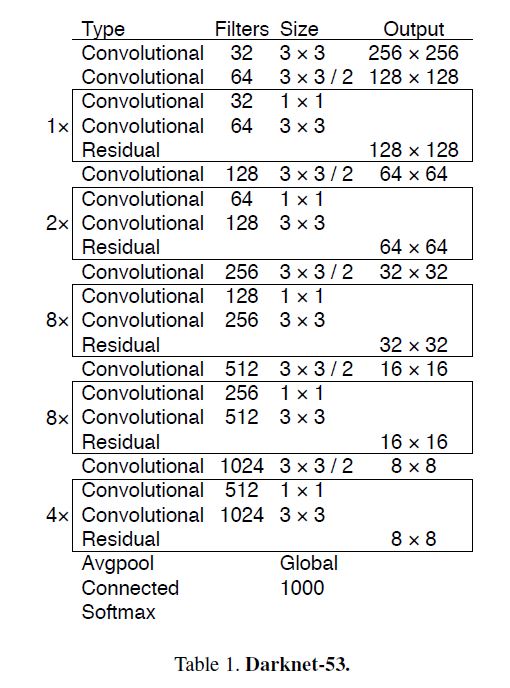
值得一提的是, 这个新的网络质量居然和ResNet-101/152旗鼓相当:
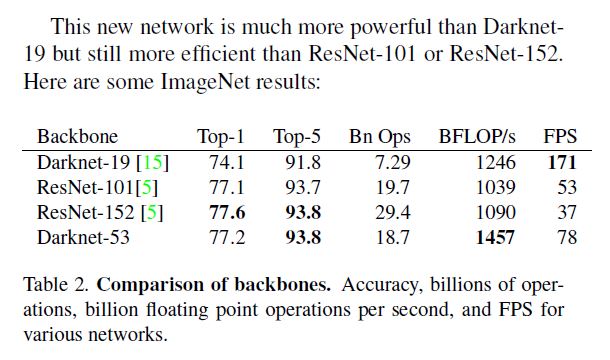
毫无疑问, 此网络速度比ResNet快得多, 确切是足足快了一倍, 原因是浮点计算少了.
Training
作者的训练没有使用hard negative mining.
How We Do
下面又进行了实验对YOLOv3和当时一些流行的方法比较, 取得以下数据:
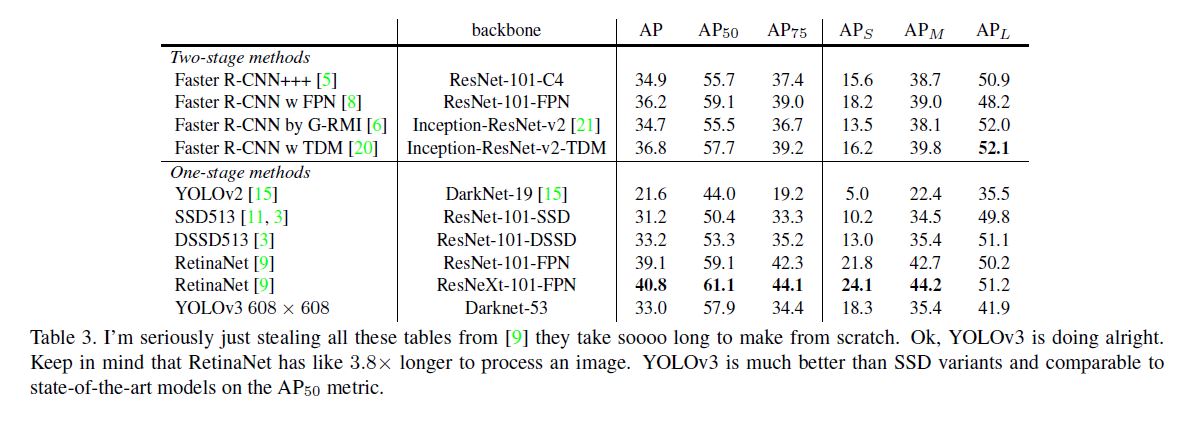
另外作者在实验时发现提升IOU阈值并不能取得较好的结果, 本文中的0.5就是最合适的参数.
Things We Tried That Didn’t Work
- YOLOv2曾尝试过的传统bbox regression在这里同样不好用.
- 线形预测bbox coordinate同样不好用.
- Focal Loss也不好用, 我们直到Focal Loss(在我们曾经的博文RetinaNet引出)是为了解决class imbalance问题的, 可能是因为已经进行了objectness和条件概率预测, 而不会产生此问题, 对此本文作者并没有强行解释.
- Dual IOU threshold也不好用, 它就是指当IOU大于某个阈值如0.7, 则视作positive, 若小于某个阈值如0.3则视为negative, 剩下的区间则直接忽略.
What This All Means
作者认为IOU阈值设置太高或是太低都不合适, 太高造成positive样本稀少导致训练不充分, 太低的话人类都不能分清物体更何谈机器对其检测呢.
Rebuttal
这是本文最有意思的一部分之一, 虽然可能和模型无关我还是是想简单介绍一下.
作者先是说了自己工作比较繁忙, 后来话锋一转对一些直接开喷, 以下是她提到的两个评论:
一个人认为没有创新型, 另一个人认为MSCOCO metrics不够说服力.
-
对第一个, 作者直接嘲讽他是酸柠檬, 吼吼.
-
对第二个作者说:"我做出接过来还必须得吹吹水你才能满意吗?" 这还没完, 作者直接对传统metrics表示不满.
作者提供了一个例子, 下例中两种情况都有高mAP, 但有一个表现显然比另一个差:
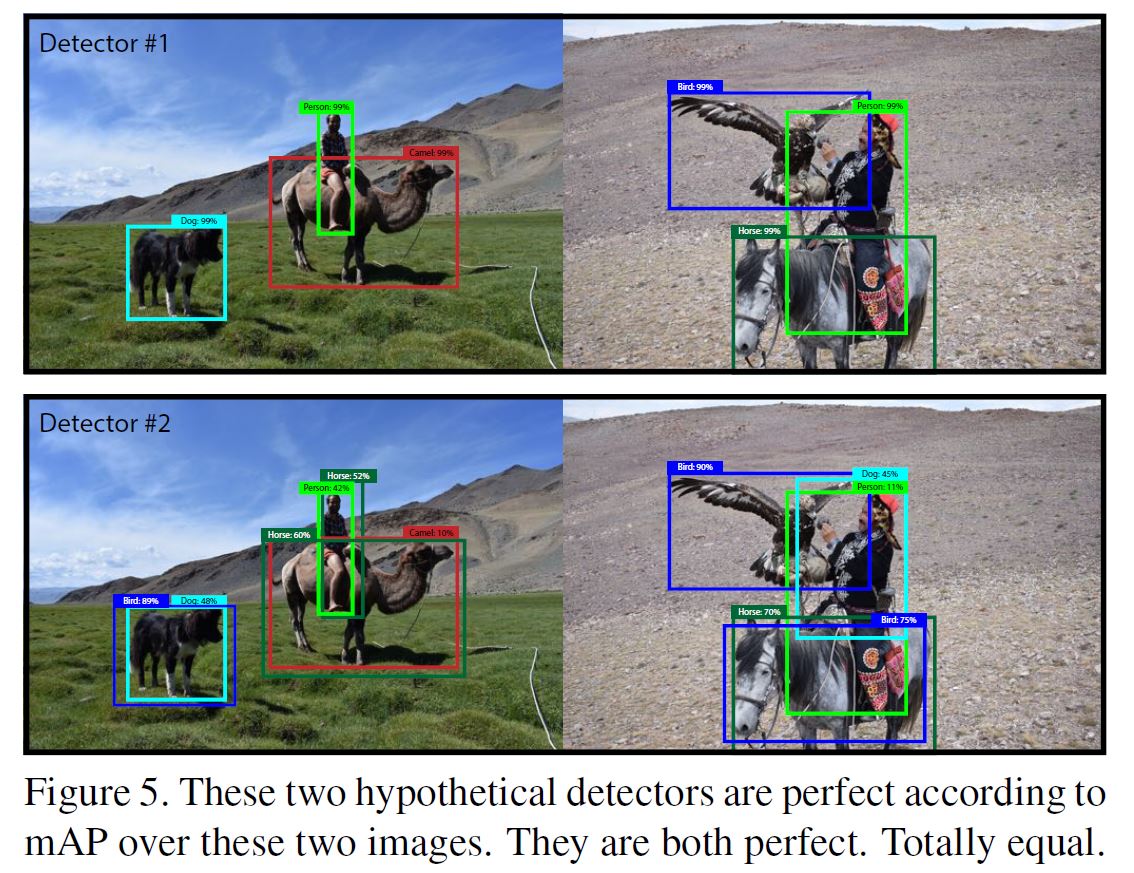
具体原因是因为将各类别求平均(图中预测出了根本没有的类别根本谈不上recall, 该类别的AP就始终是0, 最终各类别求平均使二者mAP相同), 作者认为detection的任务应该是关注detector能否发现物体且分类多好, 他认为也许我们可以去掉per-class AP, 只是对全局预测精度求平均(global average precision), 或者对每幅图像单独计算AP并取平均(也许作者是指只针对单独类别AP求平均而不会将所有类别混为一谈求平均).


 浙公网安备 33010602011771号
浙公网安备 33010602011771号