
YOLOv2&YOLO9000
论文信息
Joseph Redmon, Ali Farhadi. YOLO9000: Better, Faster, Stronger. CVPR 2017.
前言
我习惯用红笔标记出论文内容的重点, 一般的论文我一页划十来行的样子, 在整理这篇文章时我几乎每页都划满了, 其创新型也可见一斑, 内容众多, 请仔细阅读下文的详解.
本文实际是从YOLOv1先进化到YOLOv2后又脑洞大开创造了YOLO9000.
论文标题中有Better, Faster, Stronger三个关键词, 因此本文也是围绕这三个关键词进行的.
Introduction
由于分类和检测二者虽然工作有一定类似的地方, 但从数据集的角度来看, 分类的类别远远大于检测的类别, 换句话说分类分的类别比检测精细的多(e.g. 分类可能将图片中的一条狗精细的分为金毛犬, 而检测只会判定其为狗). 而对于目标检测进行labelling比分类labelling复杂得多, 因此短期内不可能出现精细分类的目标检测数据集.
因此本文的一个重要工作就是打通目标检测数据集和分类数据集之间的桥梁, 使分类工作可以直接利用分类数据集.
当然, 本文作为YOLOv1的进化体, 也提升了其检测速度和检测质量.
Better
上一篇博文中我们提到了YOLOv1在localization上表现较差, 而且它的recall与proposal-base方法相比也很低, 因此本文对于上一代主要改进也是围绕二者进行的.
CV在当时的趋势朝着越来越复杂的网络发展, 高质量的表现往往来自复杂网络和使用multiple models together. 而本文为了提升速度选择使用简化的网络和设法使representation更容易优化, 作者融合了此前的一些优秀的方法来提升新模型的性能.
Batch Normalization
作者使用Batch Normalization来提高收敛速度, 归一化各成分, 并且在没有overfitting的情况下去掉了网络的dropout层.
High Resolution Classifier
作者将输入图像分辨量从YOLO的\(224 \times 224\)分辨率提升到\(448 \times 448\). 因此作者将分类网络在新的分辨率下与训练, 这样在fin tune detection时回去的更好地结果.
不断用因子32下采样, 最终输出的feature map尺寸为\(13 \times 13\).
Convolutional With Anchor Boxes
首先提一下YOLOv1中是直接预测coordinate, 作者这里去掉了原模型中最后的fc层, 并利用了Faster R-CNN中的anchor来预测bbox.
作者也移除了pooling层来提升分辨率, 同时作者将网络缩小来操作416个输入图像而不是直接操作\(448 \times 448\)的图像, 作者此举是为了在feature map中获得奇数个location, 这样的话就能使map有一个正中间的cell, 因为在预测物体, 尤其是大型物体时, 通过正中间一个cell比利用偶数时四个cell预测好的多.
对于anchor box, 作者将class prediction与空间信息解耦, 并用YOLOv1中confidence score式的信息来表示anchor box的参数. 也就是利用\(IOU\)和\(Pr(Class|Object)\)表示.
YOLOv1每张图只预测98个box, 而本文用了超过1k个anchor却导致mAP的轻微下降, 但recall却得到提升, 因此说明有一定提升空间.
Dimension Clusters
作者将anchor机制应用到YOLO上时遇到两个困难. 一个是box dimensions是手选的, 另一个是如果提供一个比较有利的预设条件, 那么就会很容易优化模型到一个较好的状态.
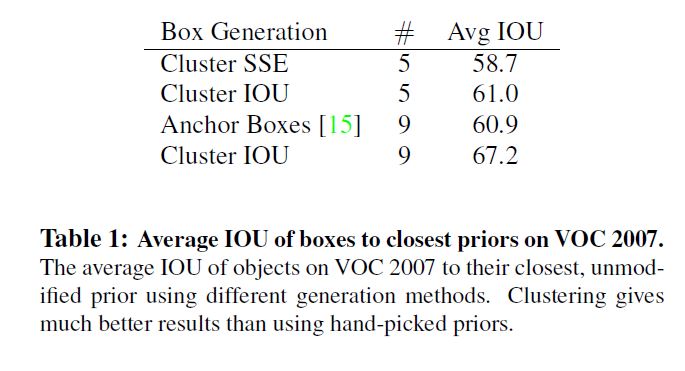
作者用k-means来代替手选box dimensions, 但这里不能直接使用欧几里得距离因为会使大box产生比小box大得多的权重而使小box得不到足够的优化, 因此作者设计了一种新的距离计算方法:
作者用扫参的方法找到了一个兼顾复杂度和recall的参数: \(k = 5\)
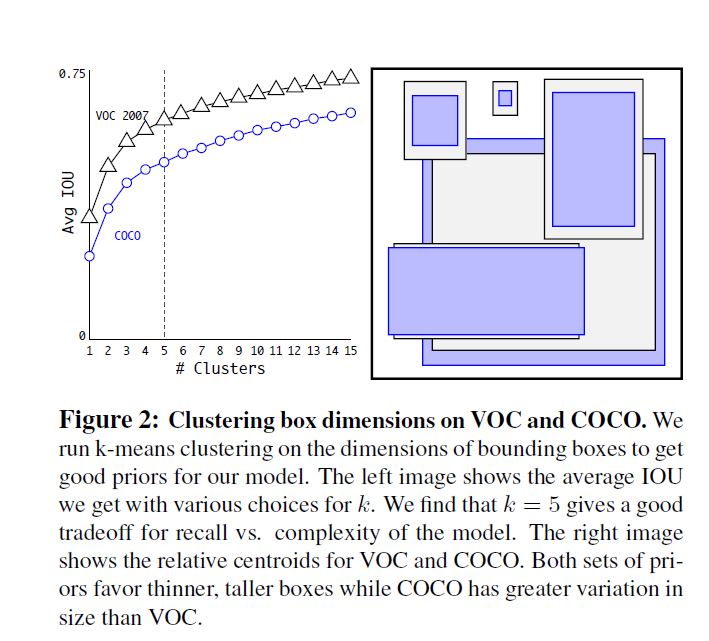
作者通过实验验证使用k-means产生的5个box达到了和手选9个box的水平.
Direct location prediction
经典的bbox regression在YOLOv1 + anchor表现并不好, 其不稳定性主要来自预测box位置时的\((x, y)\), 在预测位置时用到了需要被产生和优化的参数\(t_x\)与\(t_y\), 并遵循以下公式:
这种定义最大的问题是不管原始box在哪里, anchor box可以被优化优化到图像的任何位置. 如果随机生成参数的话就会使优化时间非常长.
作者针对这种问题, 借助YOLO中从cell中预测坐标的思想, 提出了一种使ground truth落入区间\([0, 1]\)的方法.
在输出的feature map上对每个cell预测5个bbox, 且每个bbox再预测5个参数\(t_x, t_y, t_w, t_h, t_o\), 并设图像的左上角为\((c_x, c_y)\), 对每个bbox预设\(p_w\)和\(p_h\), 利用下面一系列定义:
其中\(\sigma\)表示sigmoid.
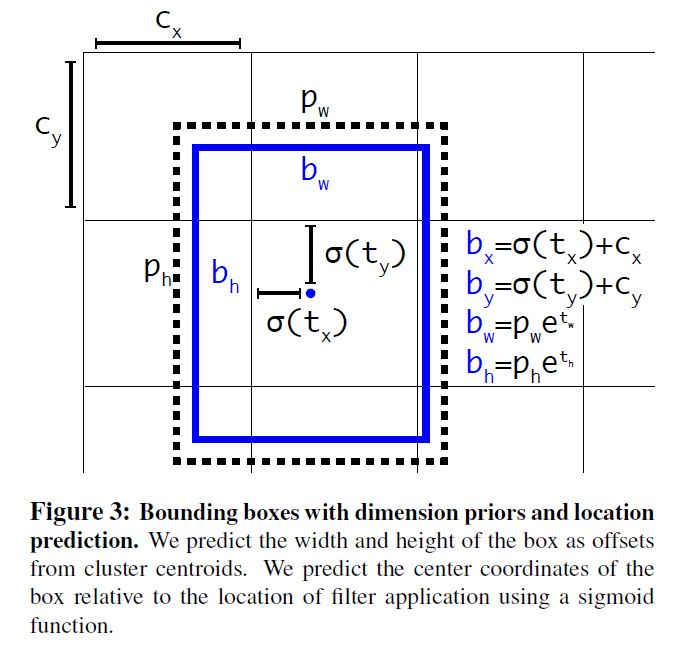
通过这种方法也同样使结果得到提升.
Fine-Grained Features
对\(13 \times 13\)的feature map直接操作, 除了对大的目标检测有帮助, 也能对小的物体有所帮助. 与Faster R-CNN/SSD等利用不同的feature map的算法不同, 本文将一些相对浅层的\(26 \times 26\)的feature map做了直通.直通层将深浅层的feature map通过将相邻层视作不同的channel而不是空间对应位置直接相加进行连接, 此举与ResNet的方法类似. 将detector在此输出上运行也可以得到1%的提升.
Multi-Scale Training
采用multi-scale的方法同样取得一定提升.
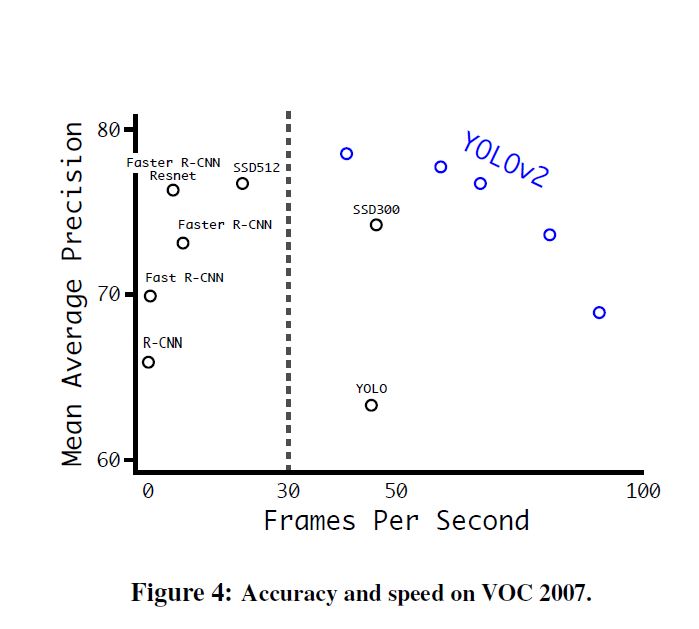
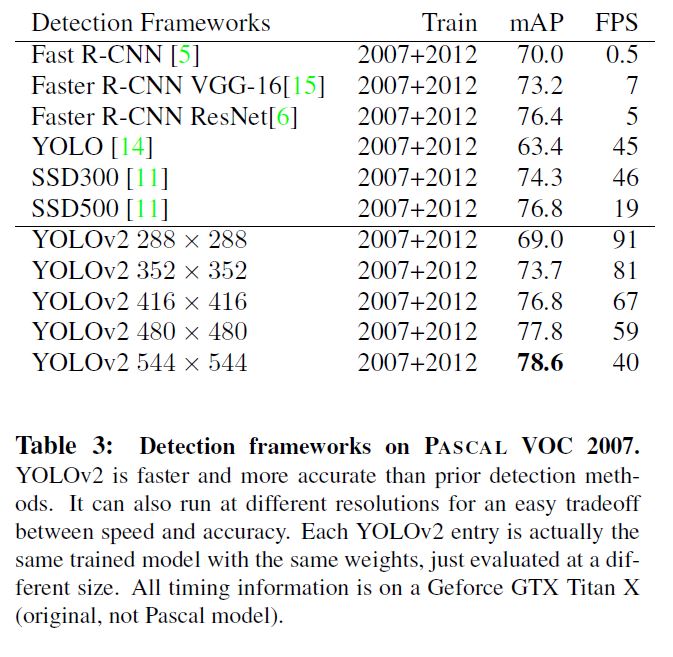
Faster
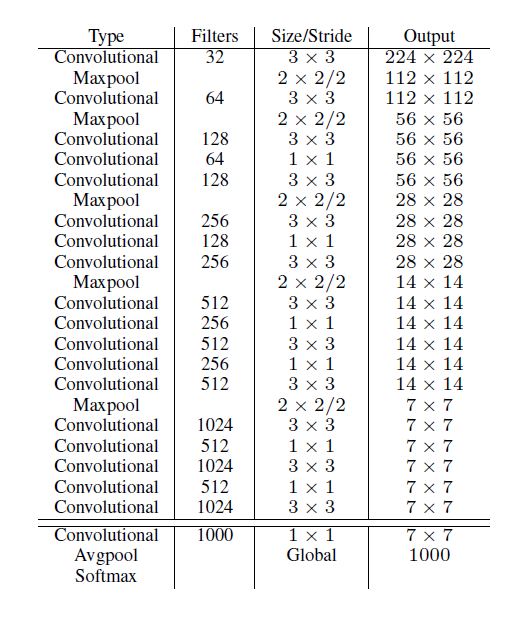
作者认为VGG-16过于复杂, 提供的准确度提升远不及其速度的下降, 因此层尝试过GoogLeNet, 后来又提出了一种新的他称为Darknet-19的模型:
Training for detection
作者将最后的卷积层移除, 换为1024filters的\(3 \times 3\)卷积层, 并最后跟上一个\(1 \times 1\)的有类别数个filter的卷积层.
Stronger
作者设计模型既能利用detection data来训练detection时的参数如bbox coordinate, 又能利用classification data来训练classification能力如精细label. 以此来提升预测物体label的精细程度.
当处理detection数据时, loss函数使用完整的YOLOv2的loss, 当处理classification数据时, 只计算该结构中的classification部分的loss.
这个想法最大的问题时detection过程label不够精细, 如类别"dog", 而classification过程label精细, 如类别"Norfolk terrier(诺福克猎犬)", "Bedlington terrier(贝灵顿猎犬)". 必须找一种方法将二者融合.
softmax分类的前提是个成分独立, 而对于"dog"和"Norfolk terrier"显然不独立.
Hierarchical classification
作者引入了一种关系模型: WordNet, 在这个模型中"Norfolk terrier(诺福克猎犬)"和"Bedlington terrier(贝灵顿猎犬)"都是"terrier(猎犬)"的子集, 同样属于"dog"的孙集, 属于"canine"的曾孙集...
WordNet因为语言的复杂性是一个有向图结构而不是树, 例如"dog"同时属于平行集"canine"和"domestic animal", 作者为简单, 将其简化为树结构.
因为我们的目标是检测实体, 作者首先去除了WordNet中的抽象名词(药水哥等), 并对每一个终端回溯到根节点同时记录路径, 有的只有一条路径, 作者直接将其加入树中, 许多同时属于平行集的集合因此存在多条路径, 作者只选择边最少的路径将其加入树中.
最终每层的节点的条件概率只与上层有关:
最终计算概率时利用条件概率公式逐层计算即可:
另外, 令\(Pr(\text{physical object}) = 1\).
训练时, 原训练集有1000个class, 经过关系树构建后有了1396个class, 物体属性继承, 例如"Norfolk terrier"也被视为"dog"也同时被视为"mammal", 计算条件概率, 模型预测了1396个值的向量, 再利用softmax预测相同concept的物体, 如下图:
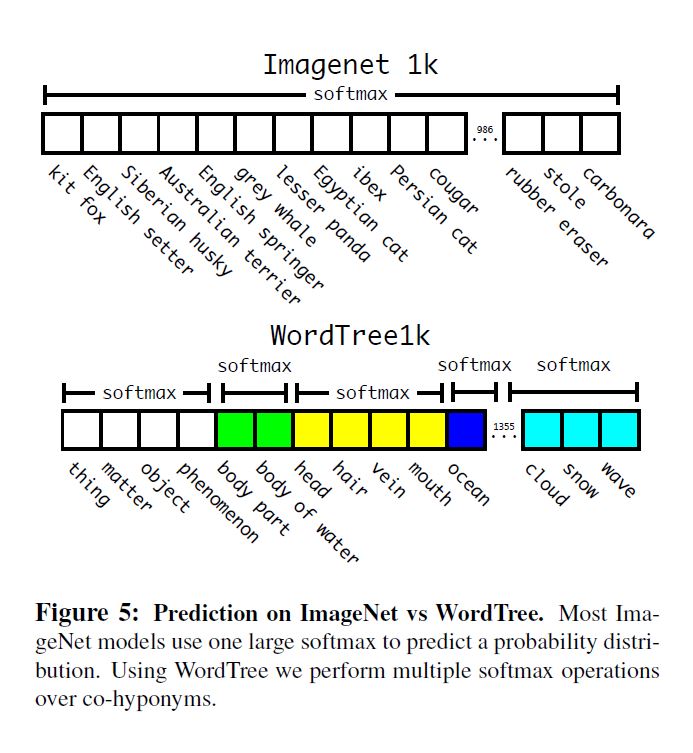
虽然多了369个class, 但是精度损失很小, 特别的, 在预测未知或是新的object categories时, 表现下降很小. 例如, 当预测一只此前没有训练过的品种的狗时, 虽然不能预测出品种, 但可以比较容易地预测它是一只狗.
预测时便是自下而上从最高confidence向上寻找, 直到confidence下降到某个水平后停止寻找.
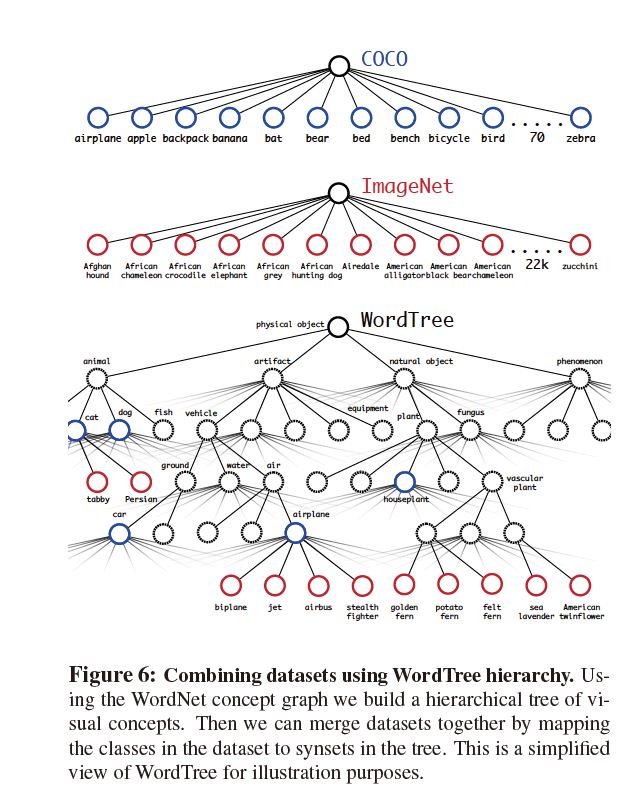
Dataset combination with WordTree
可以用WordTree将不同数据集进行整合, 如图所示:
Joint classification and detection
首先设置classification和detection数量比例为4:1, 其后对于detection的loss不变, 对于classification的loss只取到对应level的score. 例如, 如果实际label打的"dog", 那么我们confidence score只计算到"dog"层, 无论下面预测其为何品种都不继续向下计算.
反向传播classification时的loss, 本文直接选择了得分最高的bbox, 此反向传播基于假设该bbox有\(IOU > 0.3\)
Conclusion
本文的几个创新点: 使用anchor来更好地表示位置信息, 使用新的bbox regression使位置信息更加完善, 迁移WordNet使detection能利用classification dataset以获得更精细的结果.
另外对于一个目标检测模型, 其综合结果都是碾压当时的模型.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号