
Light-Head R-CNN
论文信息
Zeming Li, Chao Peng, Gang Yu, Xiangyu Zhang, Yangdong Deng, Jian Sun. Light-Head R-CNN: In Defense of Two-Stage Object Detector. open source.
https://arxiv.org/abs/1711.07264
Introduction
作者称two stage模型的第一步生成proposal的部分为body, 第二步识别proposal的部分为head. 而目前的做法为了提高准确率, 将head设计的很复杂(heavy). 因此当时的two stage算法大多数都是低速高精的.
作者分析经典的two stage模型发现存在共性: 除了上文提到的head设计较为复杂以外, 对于Faster R-CNN, RoIPooling的输出channel很大, 导致其后的fc层占用大量内存并潜在降低运算速度. 对于R-FCN(以前博文介绍过它), 采取了share computation的措施, 但因为它的score map channel(\(class \times p \times p\))是在太大, 导致内存消耗太多同时也影响其运算速度.
本文提出的方法具体有以下两点:
- 使用大卷积核来产生small channel(\(\alpha \times p \times p\))输出.
- 使用一种简单的fc层与pooling层相连来进行classification和regression的任务.
本文介绍的模型同样适用于复杂和简单的backbone.
Their Approach
具体的来说, 作者所指的head是连接backbone的部分.
Light-Head RCNN
R-CNN subnet
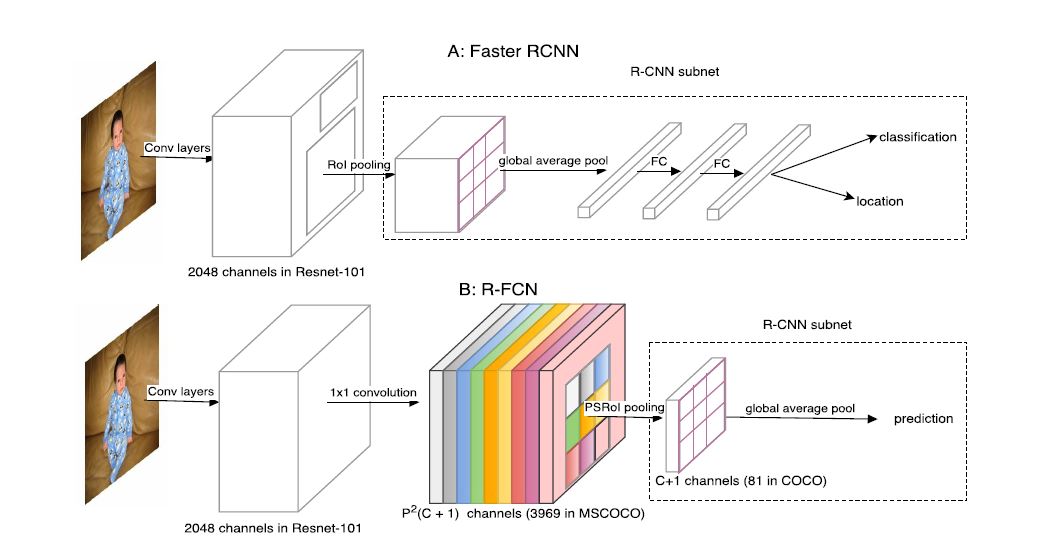
从精度方面考虑: R-CNN通常会进行global average pooling来减少数据量, 但此操作会影响空间信息. R-FCN利用了空间信息, 因此对空间特征有更好地表示, 也正因此如果没有他的RoI层, 它的表现就会差得多.
从速度方面考虑: Faster R-CNN将每个RoI都独立地传入后层, 此举极大地降低了其速度, 当proposal较多时, 其所受影响更大. R-FCN则使用较为简单的后层, 但其中间过程会产生一个巨大的score map占用大量内存.
Thin feature maps for RoI warping
当时非常流行在将proposal送入subnet之前通过RoI获取fixed feature map. 在本文中也进行了类似于RoIPooling
的操作, 但本文是产生small channel number feature maps(thin maps)后送入RoIPooling.
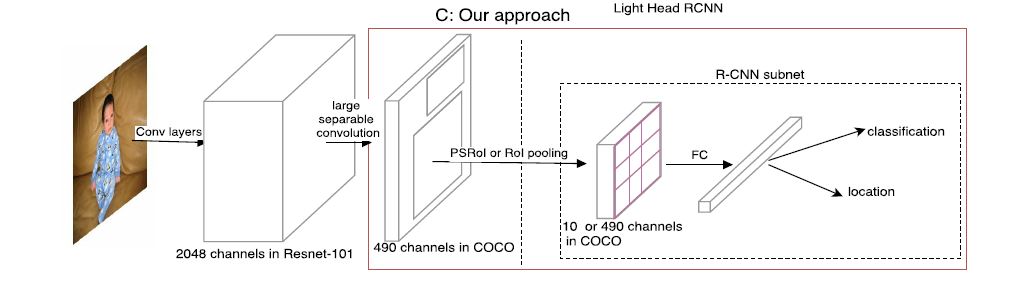
作者发现使用这种thin maps不但提升精度还能节省大量内存. 通过此方法, 便可舍弃global average pooling并能使用large conv.
Light-Head R-CNN for Object Detection
作者设置了两套配置:
- 配置L: 使用ResNet-101作为backbone.
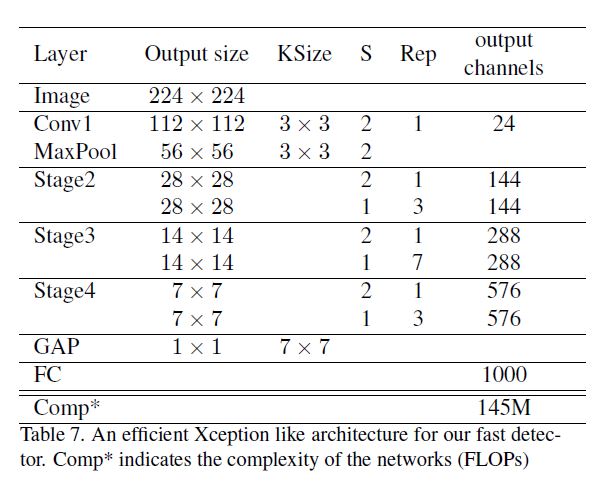
- 配置S: 使用Xception作为backbone, 其中Xception网络结构如下图.
先前图中提到的所谓separable conv如下图所示:
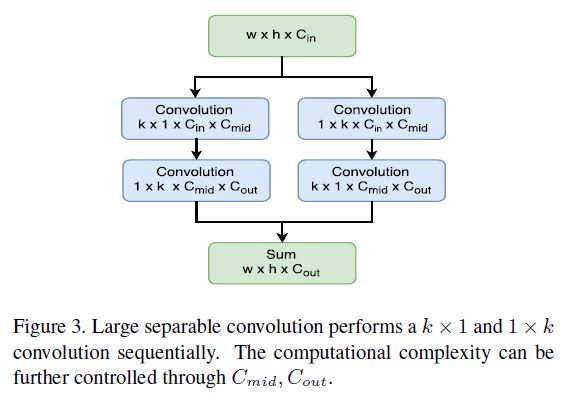
对于L, 图中\(C_{mid} = 256\), 对于S, \(C_{mid} = 64\). 另外设置\(C_out = 10 \times p\ times p\)使其运算量比此前的模型小得多. 而因使用了较大的卷积核, 因此feature map的感受野也很大.
最终用了一个2048-d的fc层(no dropout)作为subnet, 其后跟有classification和regression.
Experiment
作者也尝试一些trick如multi-scale, RoIAlign来提升精度. 对于这种浅层网络也没有加入激活. 最终在精度和速度上基本碾压了 当时的one stage. 实验若干结果, 包括使用大卷积核若下图:
其中B1和B2分别是R-FCN和作者对其改进获得的结果.






Conclusion
作者为了减轻运算运算量将backbone以后的内容简化, 提出一种所谓separable conv的方法, 和通过减少channel与fc深度的方法简化. 但并没有impressive, 而且翻来覆去重复讲那几点让人读论文时感觉很不爽!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号