OHEM
论文信息
Abhinav Shrivastava, Abhinav Gupta, Ross Girshick. Training Region-based Object Detectors with Online Hard Example Mining. CVPR 2016.
http://arxiv.org/abs/1604.03540
Introduction
为了解决class imbalance问题, 有人在至少20年前提出bootstraping(现在称作hard negative mining). 这种算法逐渐流行, 产生了一类交替算法, 这种算法在以下两个状态中交替进行:
- 用样本优化检测模型.
- 用优化后的检测模型选取新的false positive样本.
从先前的利用SVM检测目标开始, R-CNN, SPPnet都有使用hard negative mining.
而在本文发表时, 已有的检测模型Fast R-CNN却没有使用bootstraping, 作者认为其主要原因是在深ConvNet(用SGD优化)的算法中, 很难把这种方法加入进去.
具体的bootstraping实现案例:
- 使用固定的模型寻找新的样本, 并将样本加入训练集中.
- 之后, 模型在固定的训练集中进行训练.
作者认为, 正是这种依次固定的算法使整体训练速度较低. 对此, 作者提出了一种用SGD优化的, 从non-uniform & non-stationary的样本利用新设计的loss的算法以期望解决此问题. 新模型的贡献主要有以下几点
- 不需要当时流行的试探性取样.
- 能取得稳定的mAP.
- backbone越复杂, 速度优势越明显.
Related work
Hard example mining.
作者认为当前有两种hard example方法:
-
在优化SVM时使用.
去除易分类的easy examples - 因此真正使用的训练集是实际训练集的一小部分.
-
在优化non-SVM时使用.
主要是应用在浅神经网络或是决策树中, 一般因为不易收敛, 会把false positives重新加入训练集中重复训练两次.
Overview of Fast R-CNN
作者选择改进Faster R-CNN的主要原因有:
- 他是一个fast end-to-end system.
- 当时Faster R-CNN很流行, 衍生出很多算法.
- Faster R-CNN可以训练整个网络而不是必须使部分网路固定.
- 不使用SVM, 且Faster R-CNN的作者证明了是否使用SVM基本对结果不造成大的影响.
Training
作者认为background RoIs是suboptimal的, 因为它丢掉了一些infrequent, but important, difficult background regions, 因此本文作者移除了对background的最大阈值限制.
他们也发现, 1:3的fg, bg比例在使用他们的算法之后也没有存在的价值, 因此他们同样去掉了该比例限制.
Their approach
Online hard example mining
先前的算法的取样阶段都是当examples数量达到某个阈值后进入训练阶段也是导致速度慢的一个原因.
本文中的算法主要进行了如下几个阶段:
- 使用卷积网络生成feature map.
- RoINet利用该feature map产生RoIs, 并且所有的RoI都进行前向传播.
- 通过排序输入RoI的loss, 选取\(B/N\)个"hard example"
因为shared和选取部分example的原因, 前向传播的计算量比较小.
特别的, 作者提到一个caveat: 如果有overlap就会有重复统计相对接近的box的loss的情况, 作者采用NMS并设置阈值0.7来解决此问题.
额外的, 作者还提到不需要fg, bg比例的原因: 如果缺失class, 那么loss就会上升, 最终该现象将得到解决.
Implementation details
作者提出了两个将OHEM应用到Fast R-CNN的方法:
-
直接将loss排序, 将non-hard example置零. 因为这样仍然需要分配内存且置零后他们对导数没有贡献, 因此会造成资源浪费.
-
产生两个RoINet, 其中一个是只读的. 整个过程中只读部分会只分配内存给前向传播, 标准部分正常分配内存.每次迭代只读网路会前向传播并计算每个输入RoI的loss, 之后用OHEM来筛选sample, 将筛选结果送入原网络的RoI网络中.
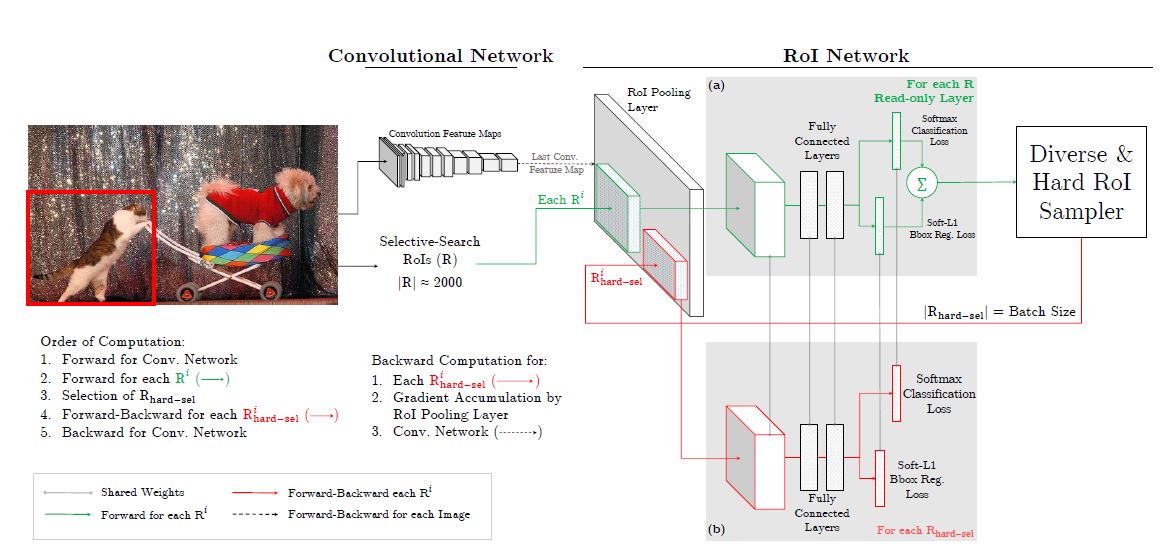
第二种方法和第一种方内存用量基本相同, 但速度达到二倍.
Analyzing online hard example mining
本文每个batch只用2张图片, 作者本以为会有类似会有类似于相近图像loss重复计算的问题. 为了验证猜想, 作者选择只用一张图片的极端情况, 实验发现二者结果相差不大, 也侧面说明了OHEM具有一定鲁棒性的特点.
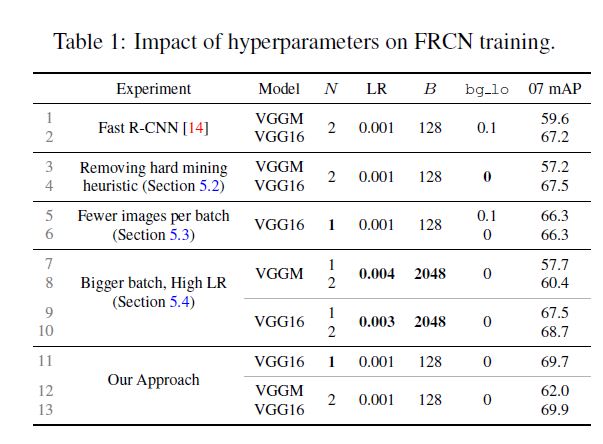
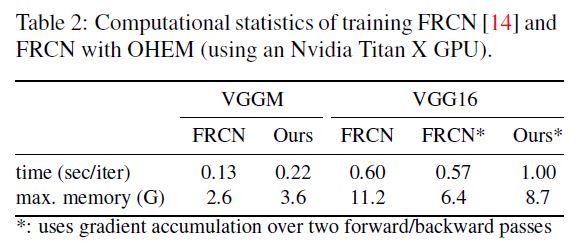
作者又实验测试只使用hard examples是否比使用全部examples更优越, 发现二者mAP相近, 但毫无疑问只使用hard examples训练速度更快.
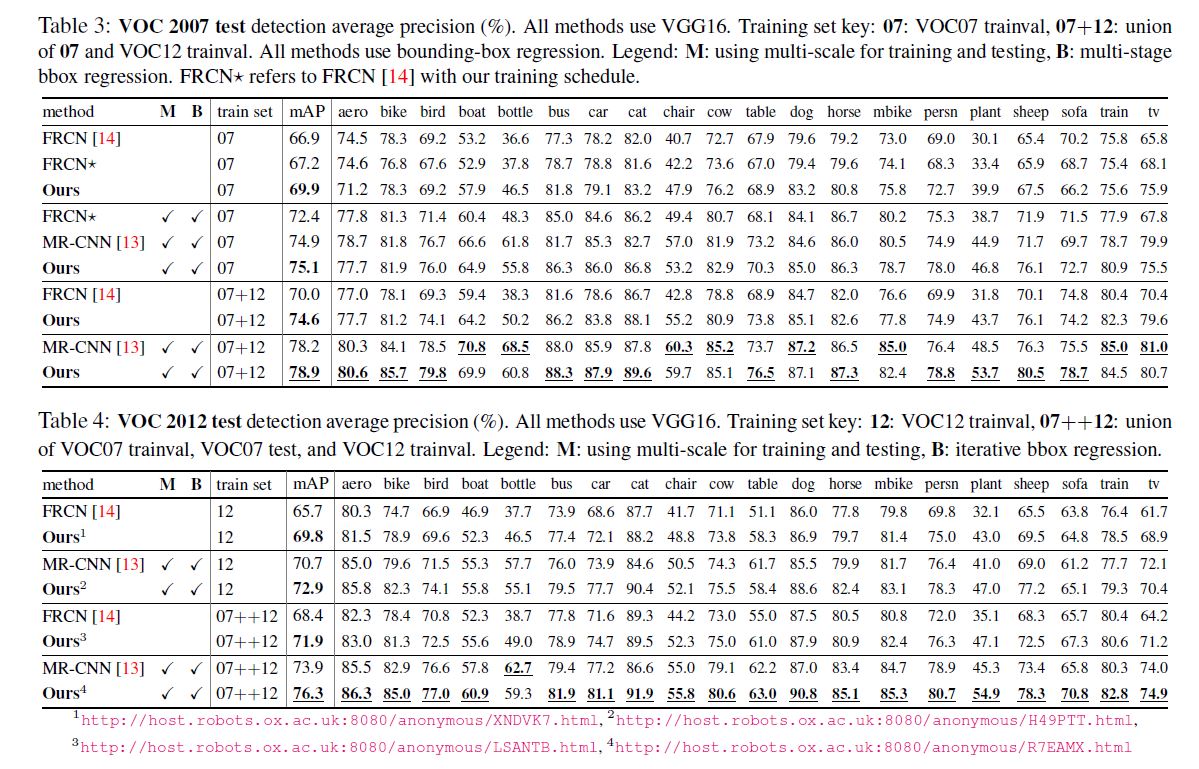
之后作者又尝试使用一些当时流行的trick来提升效果如: multi scale(M), bbox regression(B). 都实现了一定提升.
Conclusion
at 2:26 am, 太困了, 不想写.
比较有意思的有只读网络的设计和不用分阶段训练.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号