
R-FCN
论文信息
Jifeng Dai, Yi Li, Kaiming He, Jian Sun. R-FCN: Object Detection via Region-based Fully Convolutional Networks. Tech report.
https://arxiv.org/abs/1605.06409
Introduction
历史
因为当时的two stage目标检测模型都用ResNet等高准确率classification network作为backbone, 在当时的现象是backbone都能达到较高的accuracy, 但是最终目标检测模型accuracy都不高, 当时常见的解决方法时在backbone和detector之间加入RoI pooling层, 作者认为这样做时unnatural的.
unnatural的一方面原因是因为每个RoI unshared从而增加了计算量导致速度变慢.
本文的基本思想
作者认为直接这样套用太粗暴, 他认为对于目标检测应该有两个重心对其兼顾:
- image classification应该是translation invariant - 对图片放缩不应该影响分类.
- object classification应该是translation variant - detector应该对其不同位置有不同的responses.
解决方案
Basic Approach
对于上文提到的第一点, 现有方法基本都能实现, 因此本文重点在于提出了一种实现第二点的方法 - 加入一个position-sensitive部分. 下图便是basic approach.
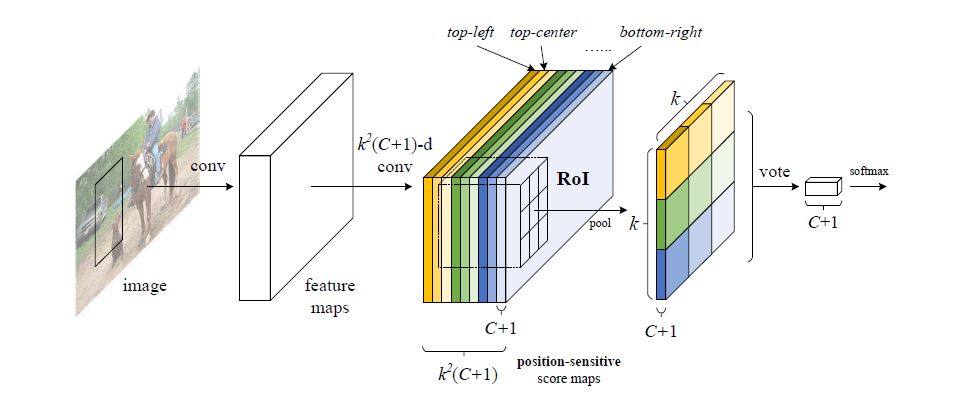
可以看出从proposal先经过conv, 对得到的feature maps进行了\(k^2(C+1)\)-d的conv, 其中\(k\)表示预设将proposal划成\(k \times k\)个区域(e.g. \(k = 3\), 就化成左上, 中上, 右上等9个区域), 而\(C+1\)表示预测\(C\)个目标类别和\(1\)个背景类别.
将这样操作产生的score maps用产生\(k \times k\)个RoIs, 在这些RoIs中只取对应位置的RoI(e.g. 左上层只取左上角RoI)称之为bin, 将各个位置的bin拼接产生\(k \times k\)个responses, 此过程称为position-sensitive RoI pooling, 各个response投票并SoftMax得到预测结果.
Practical Approach
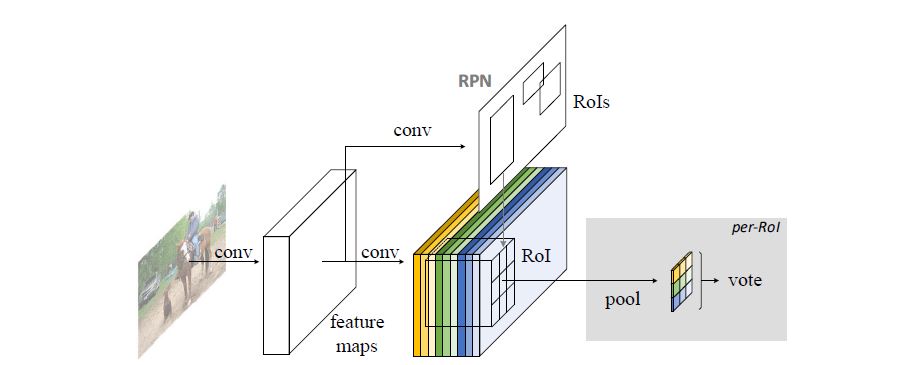
实际模型就是用RPN共享backbone的权重, 产生proposals, 将其与score maps对应, 其他基本不变.
Backbone Architecture
移除avg pooling layer和fc layer, 只保留conv layer. 并且在最底部加入了一个randomly initialized 1024-d conv layer来减小维度.
Position-sensitive score maps & Position-sensitive RoI pooling.
bin产生的response如此定义:
关于各个成分定义我们使用原文中的描述:
Here\(r_c(i, j)\)is the pooled response in the \((i, j)\)-th bin for the c-th category, \(z_{i, j, c}\) is one score map
out of the \(k^2(C + 1)\) score maps, \((x_0, y_0)\) denotes the top-left corner of an RoI, \(n\) is the number
of pixels in the bin, and \(\Theta\) denotes all learnable parameters of the network.
该等式是一个avg pooling, 作者提到max pooling同样可以实施.
关于投票部分就是对每个class的response相加:
之后送入SoftMax中预测:
特别的, 作者除了classification还在每个RoI在position-sensitive RoI pooling过程中进行了bbox regression.
Loss
整个loss包含classification loss和bbox regression loss:
其中\(L_{reg}\)时bbox regression, \(\lambda\)设置为1, \([c^*>0]\)是指当分类为bg时为0, 否则为1.
作者还提供了一个可视化的instance:

实验
实验结果
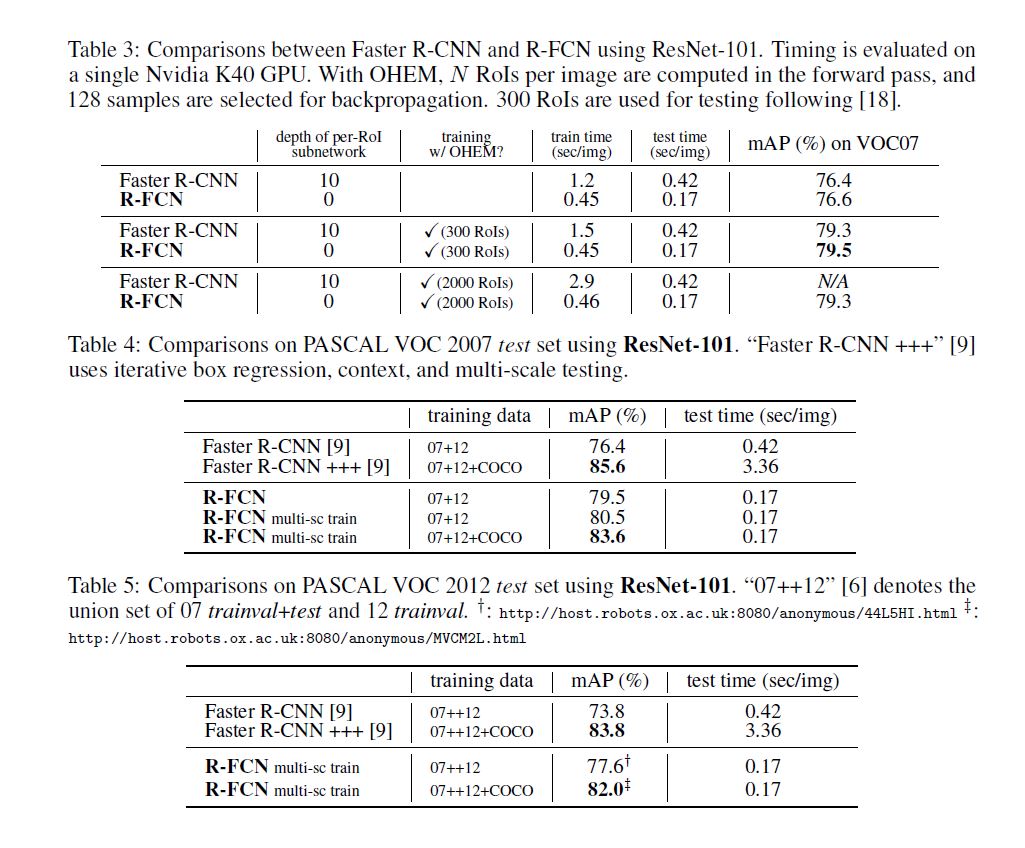
实验中作者尝试用OHEM, multi-scale等方法训练, accuracy达到了state-of-the-art的效果, speed远超当时流行的two stage方法.
后来作者又尝试增加网络深度, 使用不同的proposal方法, 结果显而易见:
- 网络越深accuracy越高.
- 使用RPN达到最好效果.
总结
我对作者实验的看法:
作者本意可能为了提升accuracy, 但并没有对于state-of-the-art拉开较大的gap, 这是因为后半部分网络结构比其他网络简单一些, 又因为利用了新的算法以应对RoI pooling的位置信息损失, 因此能达到相对比较高的accuracy. 而在用时上达到了一半甚至更小的指标, 便是因为后半部分网络结构简单.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号