
CS294-112 深度强化学习 秋季学期(伯克利)NO.6 Value functions introduction NO.7 Advanced Q learning

--------------------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------------------------------------------------------



understand that correlated samples cause problem. and how paralled solve the problem
another solution is replay buffers, fully ultilizing the advantage of off policy in Q-learning.
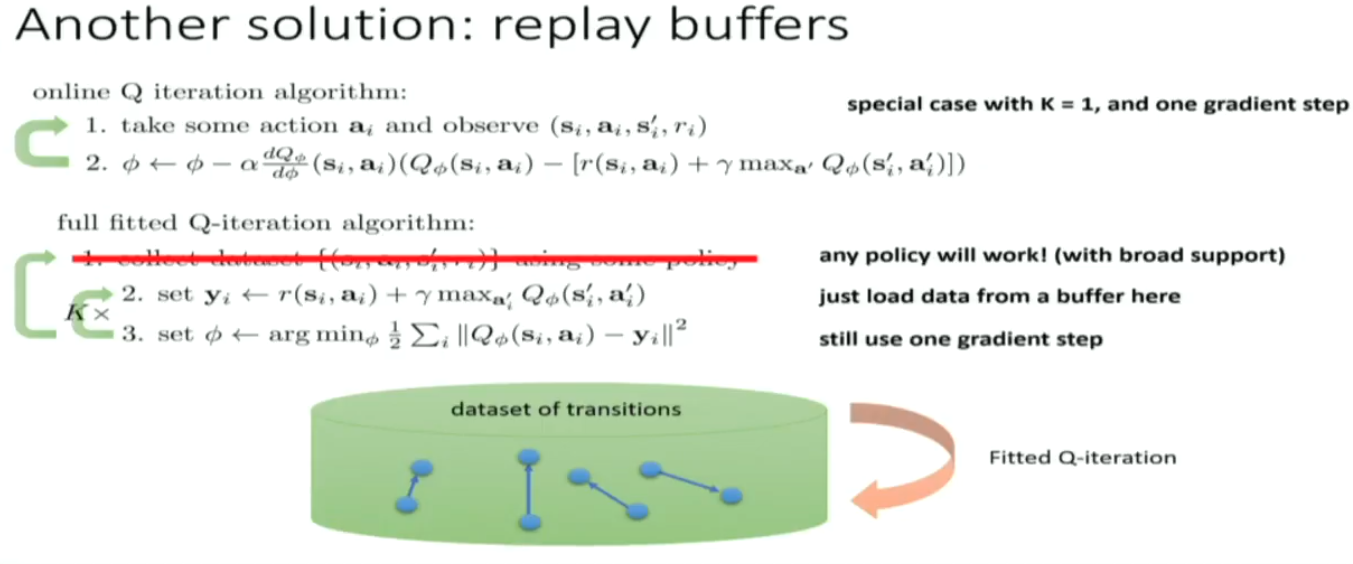
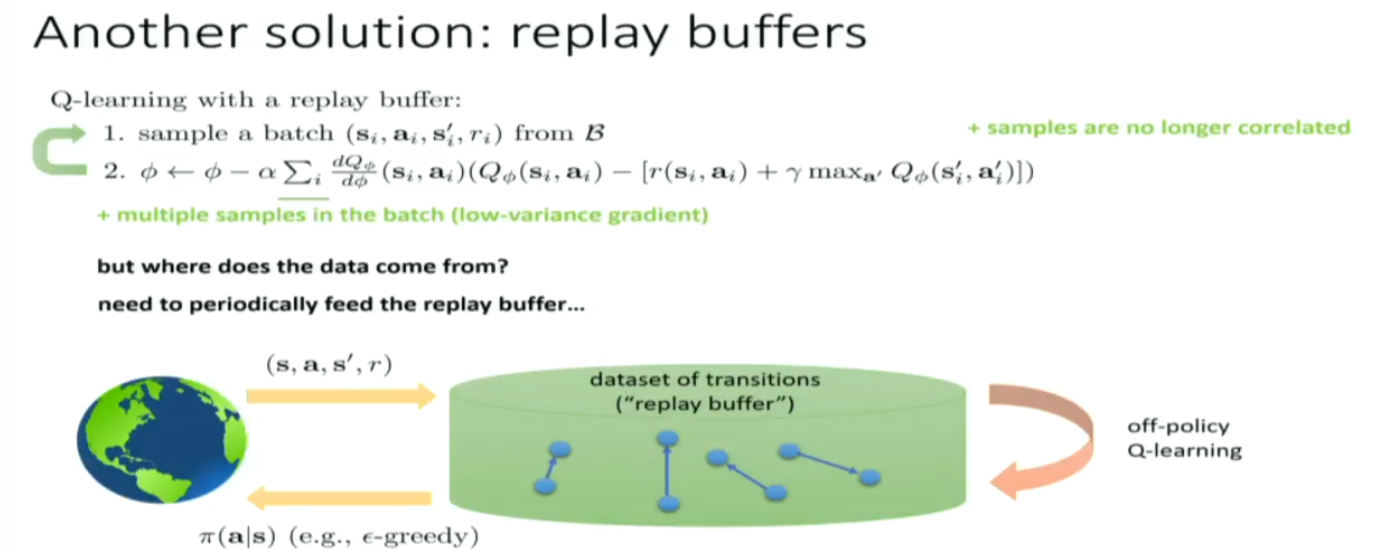


there's still a problem: Q learning is not gradient descent


divide Q function into two parts: the target net and the evolving net.
sacrifice speed to get the convergence.





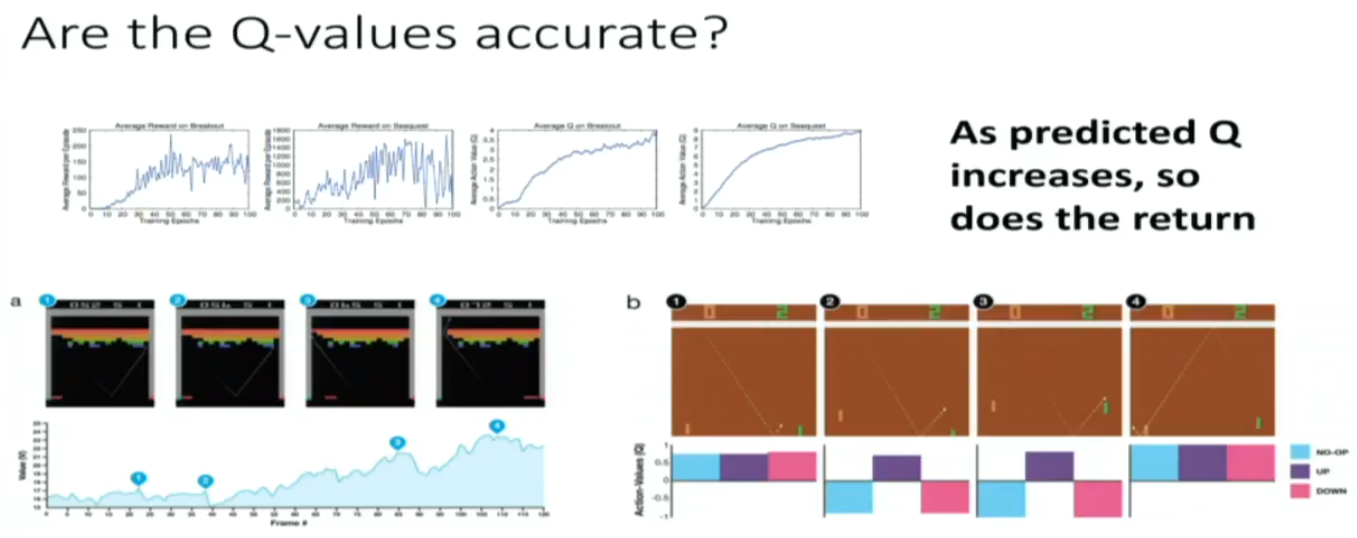
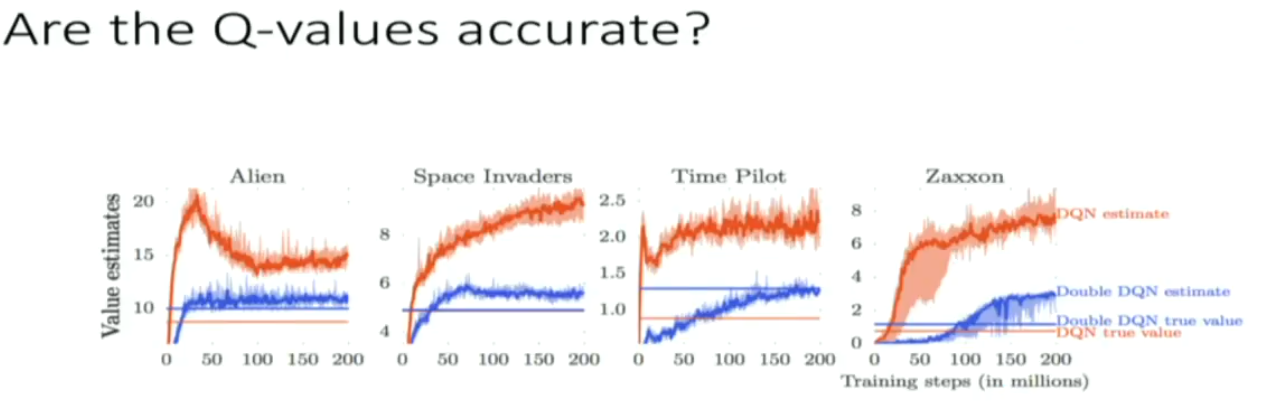
overestimation of Natural DQN








get trouble in left and right dilemma of avoiding bumping on a tree









 浙公网安备 33010602011771号
浙公网安备 33010602011771号