李宏毅 2018最新GAN课程 class 2 Conditional Generation by GAN

HW2: input a sentence, output an ACG icon
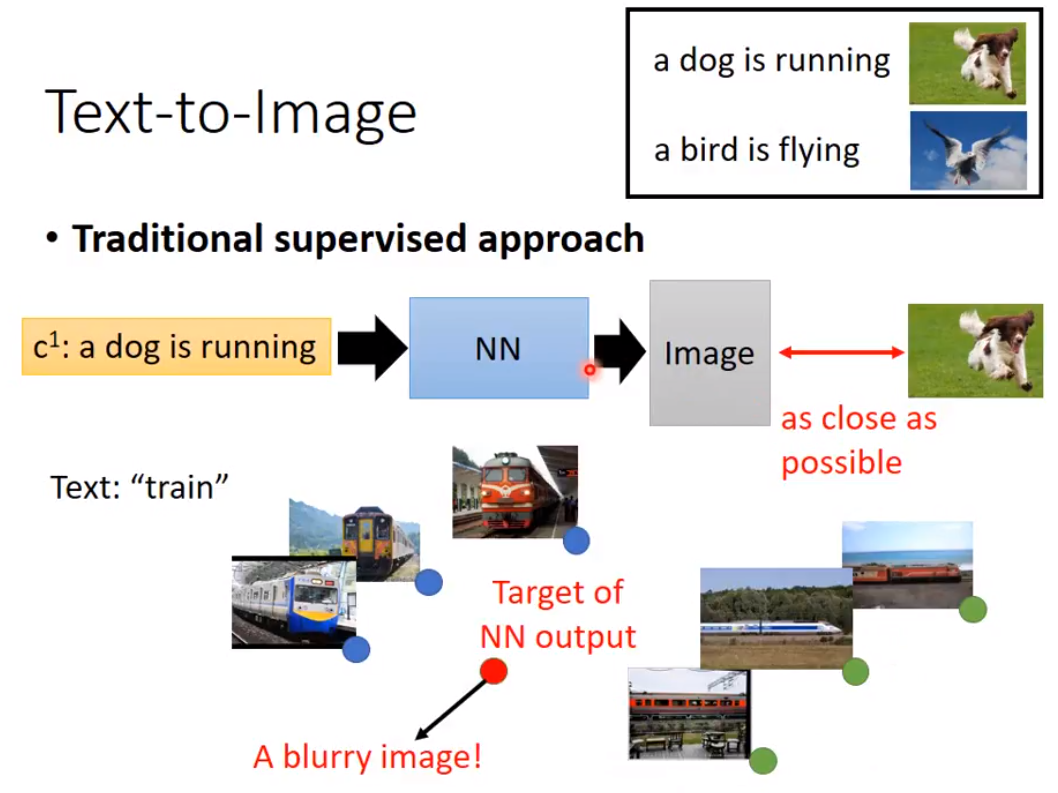
3 target: trains from front view, side views. So that the output would be the average of the three pictures... which is a totally wrong result.

G net has input of a word "train" and a gaussian noise.
However, if we use the formal way to train GAN, the resultant net will ignore the word...
train discriminator with c inputted
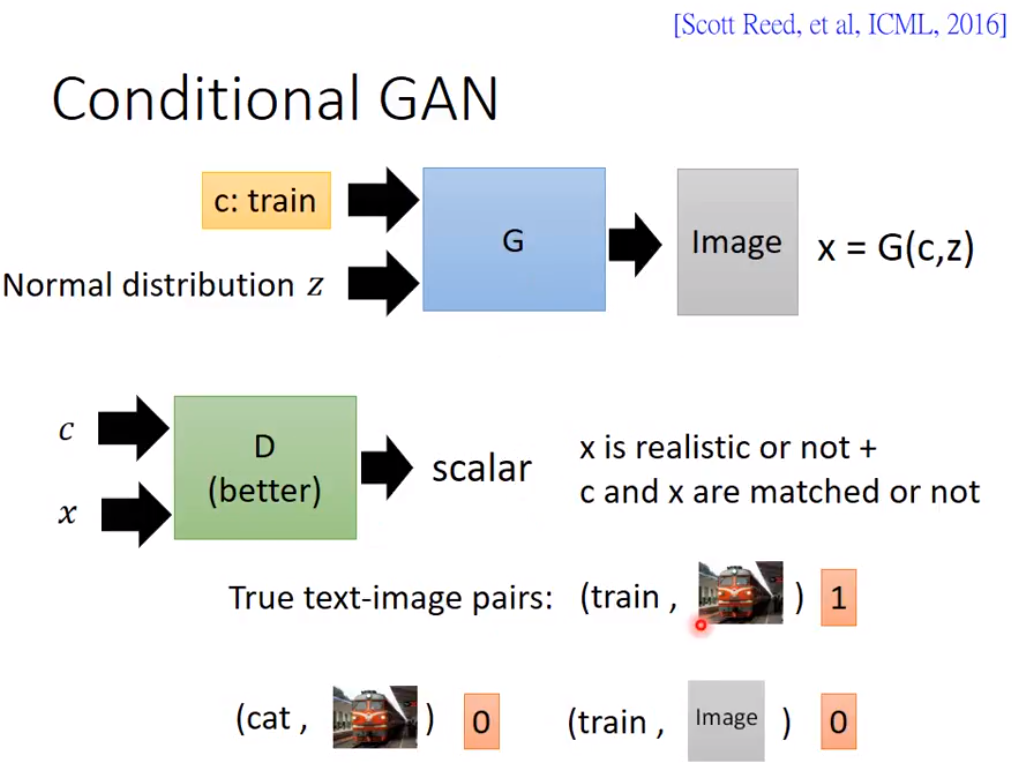
low scores should be given to wrong classification tags and non-realistic images

HW3-2
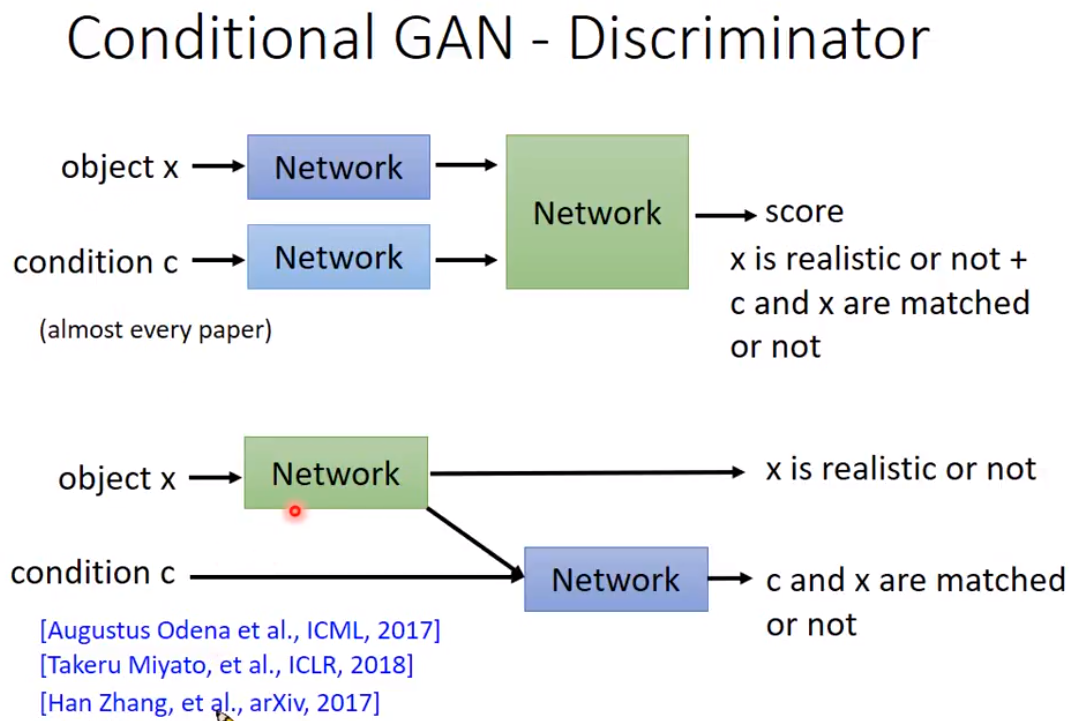
The second structure seems more resonable. Please try in your homework to judge which one is better.

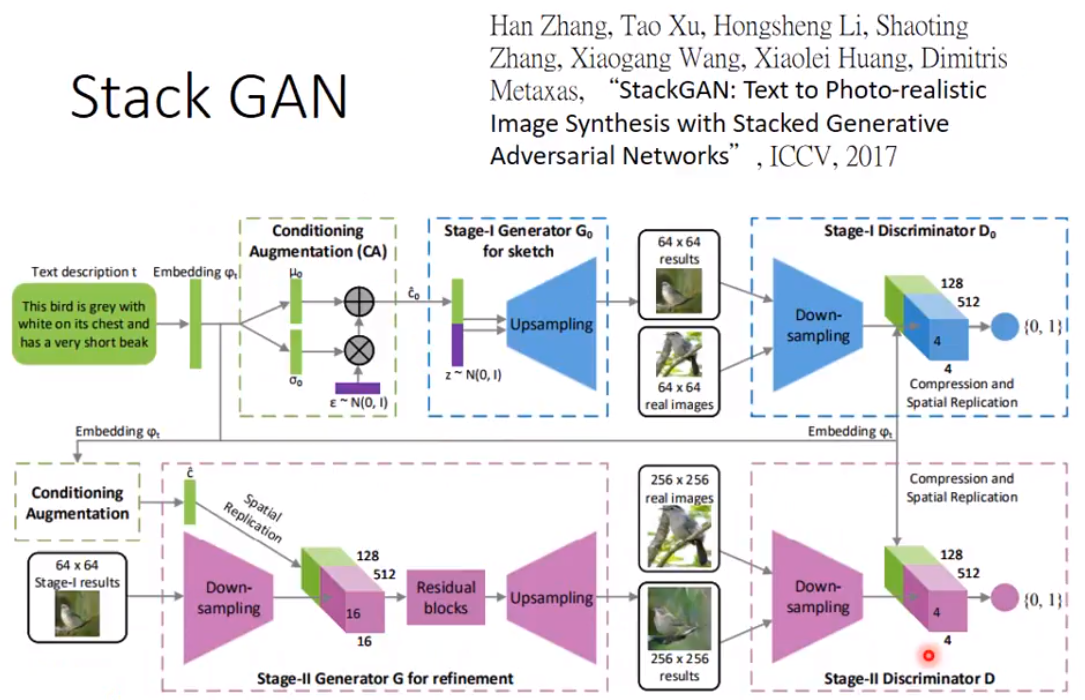
If you want to go beyond the baseline, use stack GAN
1, feed a sentence, add noise, and use the left blue box (G0) to upsampling to a small image (64x64)
2, Treat these small images with the Discriminator D0
3, Use the small image to generate a larger image (256x256)
4, Use the seconde Discriminator D1
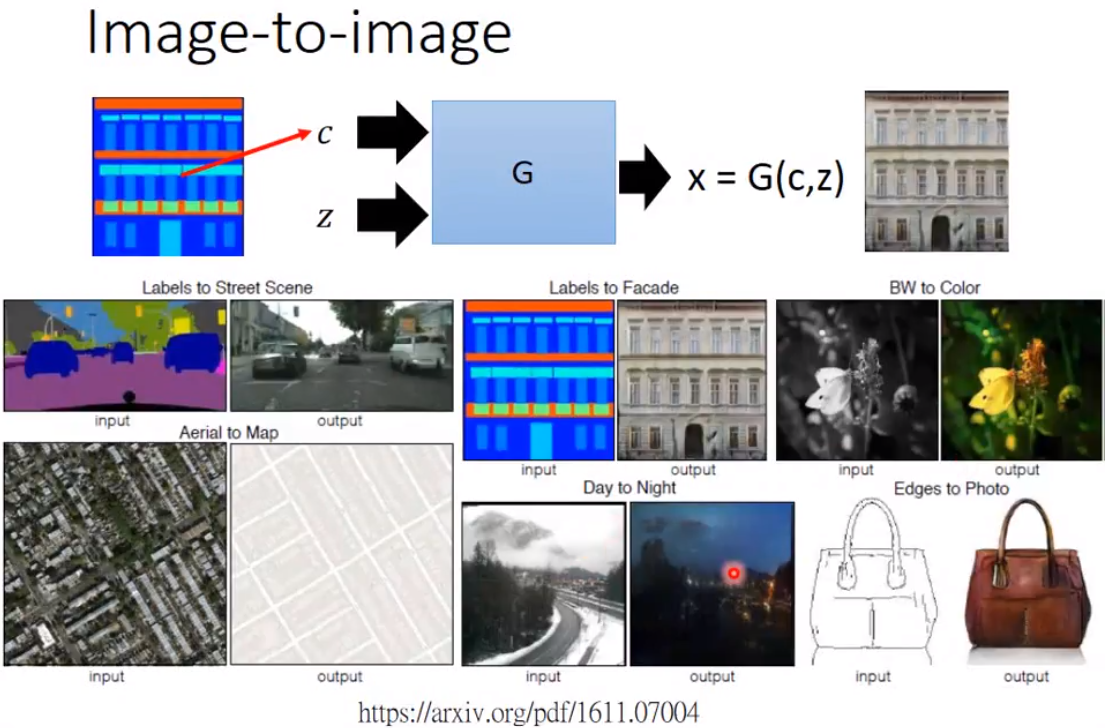
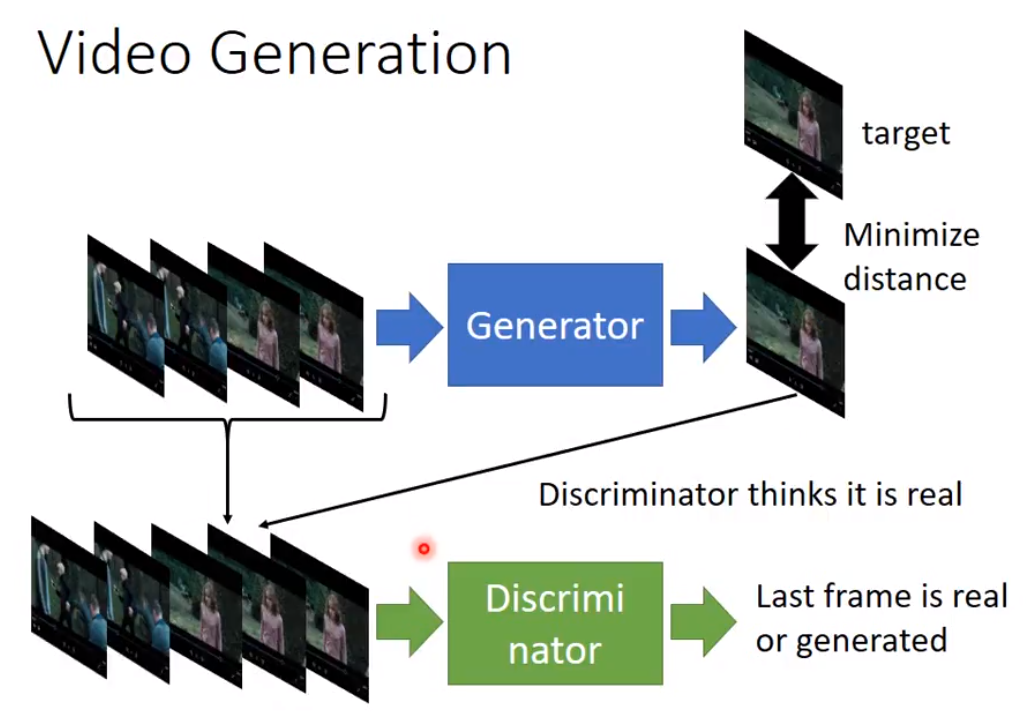
Another case: transform from 1 image to another, with a certain goal.
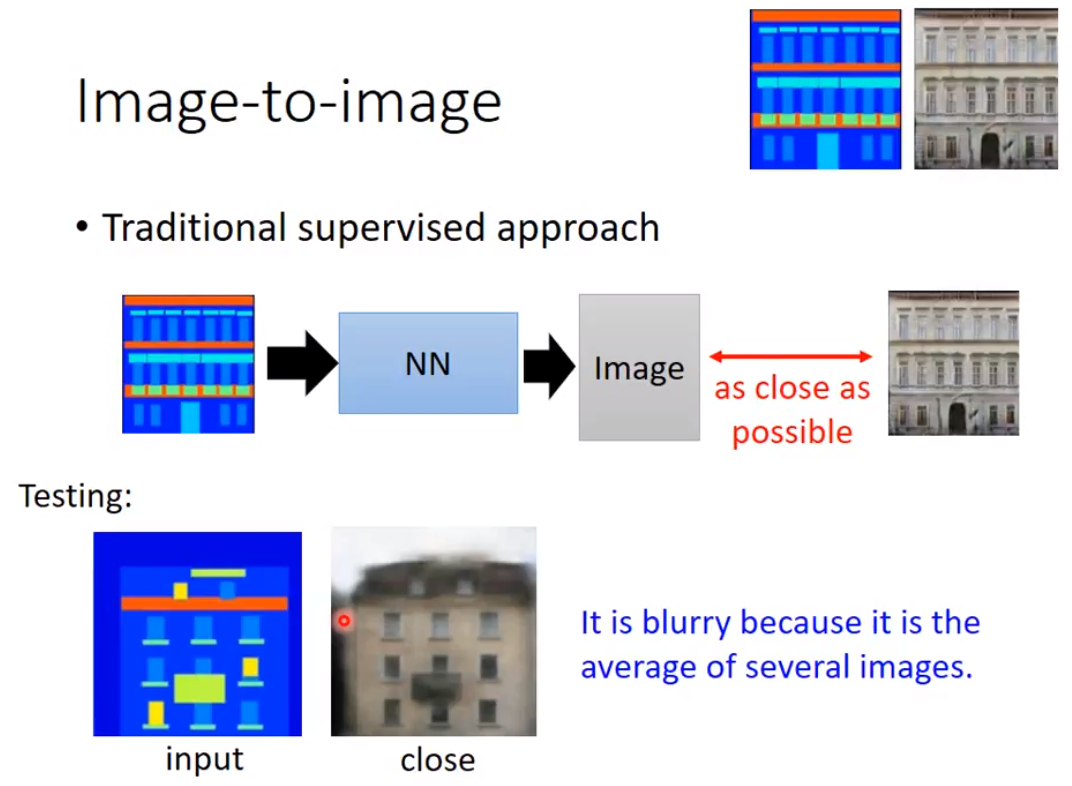
For traditional supervised approach, the output image is blurry, because it's the average of several images.

Image generated by generator has to be not only clear enough to pass discriminator, but also should be closed to the samples
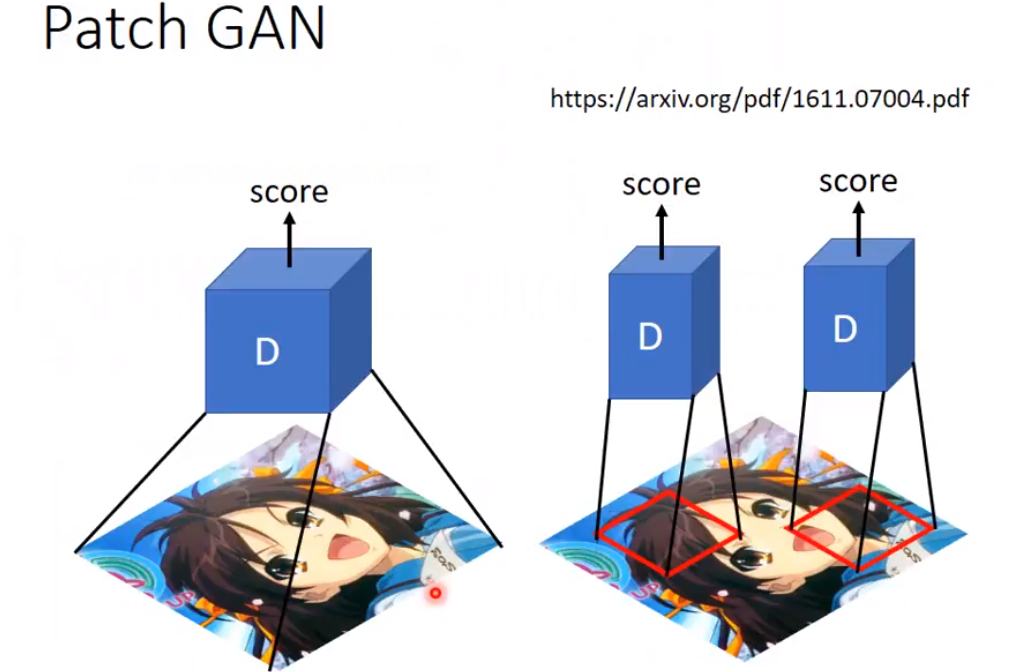
If your generated images has a large size, discriminator would be overloaded (overfitting or low training speed) --->>> PATCH GAN

Collect clear audio data, add noise to them, then use supervised learning to train the network --->>> that's the traditional way ---->>> Please use GAN :)
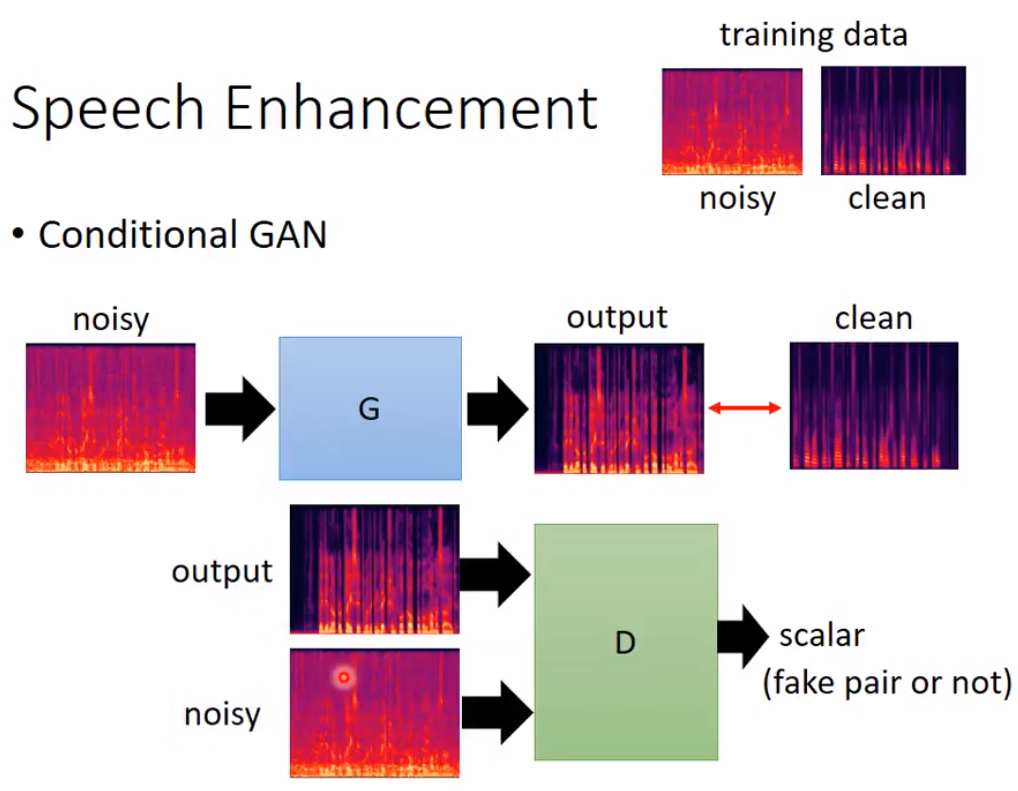
clear and paired


 浙公网安备 33010602011771号
浙公网安备 33010602011771号