04_Python爬蟲入門遇到的坑__向搜索引擎提交關鍵字02
4. 向百度提交關鍵字:
上一篇文章我們向360提交了關鍵字,這次的內容是向百度提交關鍵字
在獲取接口之後我們直接套用上一次的代碼先試試看:
import requests # 接口 url = "https://www.baidu.com/s?" # 需要提交的字典(我們要搜索的內容,此處假設為python) kv = {"wd": "python"} # 訪問偷 head = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36", } try: # 請求頁面 r = requests.get(url, headers=head, params=kv) # 判斷請求狀態 r.raise_for_status() # 輸出源碼 print(r.text) print("成功!!") except: print("頁面獲取失敗!")
這時候你會發現輸出的內容特別少,其中還有這樣一行:
<div class="timeout-title">网络不给力,请稍后重试</div>
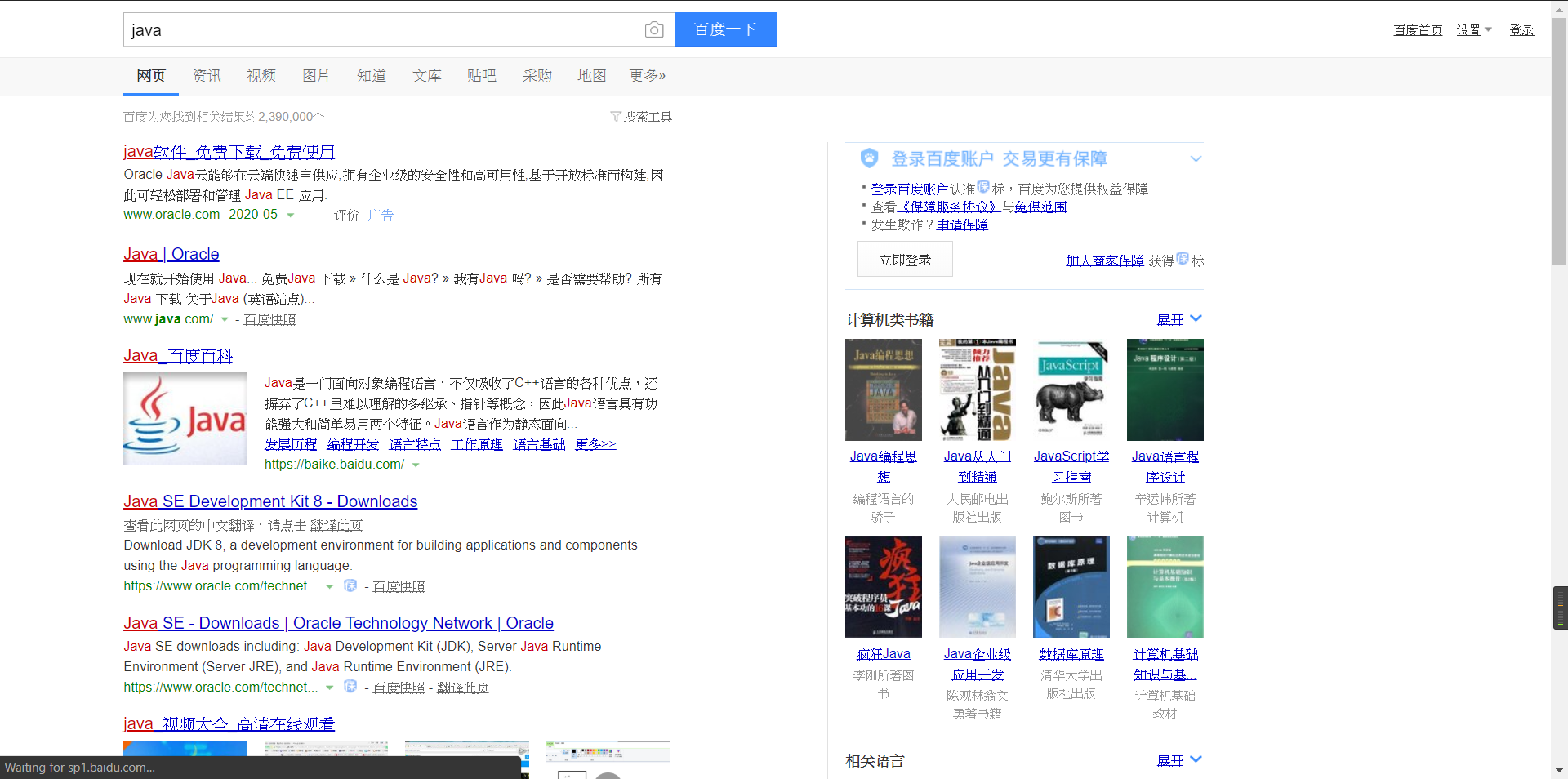
這顯然不對,因為你爬取下來的頁面是這個:

或許你馬上就會想到加上cookie,沒問題的,這完全是可以的,但是我今天要講的是另外一種方法.
在header中添加accept:
import requests # 接口 url = "https://www.baidu.com/s?" # 搜索的關鍵字 kv = {"wd": "java"} # 頭部信息 head = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3", } try: # 請求頁面 r = requests.get(url, headers=head, params=kv) # 判斷請求狀態 r.raise_for_status() # 使用備用編碼 r.encoding = r.apparent_encoding # 輸出源碼 print(r.text) print("成功!!") except: print("頁面獲取失敗!")
這時候便能得到正確的結果:
總結:cookie很有用,但不代表每次都需要!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号