
从零开始的 dbt 入门教程 (dbt core 开发进阶篇)

引
在上一篇文章中,我们花了专门的篇幅介绍了 dbt 更多实用的命令,那么我们继续按照之前的约定来聊 dbt 中你可能会遇到的疑惑以及有用的概念,如果你是 dbt 初学者,我相信如下知识点一定会对你有极大的帮助:
- 了解
dbt_project配置文件,以及不同字符的作用 - 了解 dbt 工程化,为 dev 以及 prod 模式配置不同的目标数据集
- 了解
model禁用与动态禁用 - 引用表的三种方式,dbt 如何维护
model的依赖关系? macro使用说明- 如何创建和使用增量表
那么让我们开始本篇内容的学习。
一、了解 dbt_project 字段含义
dbt 项目中有两个非常重要的配置文件:
profiles.yml:用于定义项目的 dbt 适配器配置,如果连接的数据库或者数据平台不同,字段会有所不同,此配置可区分开发和生产环境(一个环境一个配置)
dbt_project.yml:dbt 项目自身的配置,例如定义项目模型文件的存放地址,不同模型的创建规则等等。
以下是一个非常常见的 dbt_project 配置,事实上你需要特别注意的字段并不多,因此我会解释你在工作中需要留意的字段,如果某个字段我没过多解释,那说明你只需要跟着这么配置就好了:
name: 'dbt_models'
version: '1.0.0'
config-version: 2
profile: 'bigquery_profile'
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
docs-paths: ["docs"]
target-path: "target" # directory which will store compiled SQL files
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_packages"
models:
dbt_models:
+materialized: table
details:
+materialized: view
+schema: "{{ 'mc_data_statistics' if target.name == 'dev' else 'details' }}"
summary:
+materialized: table
+schema: "{{ 'mc_data_statistics' if target.name == 'dev' else 'summary' }}"
dau:
+enabled: true
mau:
+enabled: "{{ var('run_mau', false) }}"
name:项目名称,在上篇 dbt 命令篇章我们也提到了这个字段,当你需要指定运行某个项目的所有模型,或者为某个项目的一些目录配置不同权限时都会用到这个字段;命令上篇文章有解释,而关于权限配置我们在下文会详细介绍。
profile:dbt 项目需要配合 dbt 适配器连接数据库,前面我们已经提过了 profiles.yml 用于定义适配器配置,而这里的 profiles 提供 profiles.yml 内的名称即可(配置中的第一行代码),比如我当前的 profiles.yml 配置如下。
bigquery_profile:
target: prod
outputs:
dev:
type: bigquery
method: service-account
project: notta-data-analytics
dataset: dev
threads: 1
timeout_seconds: 300
location: US
priority: interactive
retries: 1
keyfile: xxx.json
prod:
type: bigquery
method: service-account
project: notta-data-analytics
dataset: dbt_models
threads: 1
timeout_seconds: 30000
location: US
priority: interactive
retries: 1
keyfile: xxx.json
model-paths:告诉 dbt 项目你的模型在哪个目录,其实我之前也好奇,为什么我运行 dbt run dbt 就知道去哪找到我定义的模型并运行它们, 那么这里的配置其实就是在告诉 dbt 项目中模型在哪个目录下,一般情况下直接用模版仓库默认的目录名与配置名并它们能一一匹配对应即可。
model-paths 下面的几个字段同理,都是在告诉 dbt 不同功能文件所在的目录地址,如果某个目录你不要,那么对应的配置你可以删除。
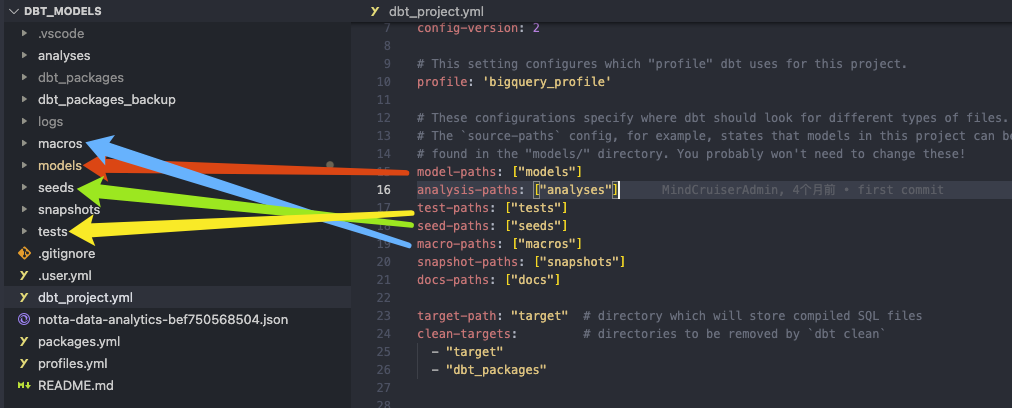
比如上图中我们并未使用 docs ,理论上docs-paths: ["docs"]这行配置可以删掉。
接下来让我们将目光聚焦到 models 开头的这一串配置代码:
models:
dbt_models:
+materialized: table
details:
+materialized: view
+schema: "{{ 'mc_data_statistics' if target.name == 'dev' else 'details' }}"
summary:
+materialized: table
+schema: "{{ 'mc_data_statistics' if target.name == 'dev' else 'summary' }}"
dau:
+enabled: true
mau:
+enabled: "{{ var('run_mau', false) }}"
通过这段配置,我将解释 dbt 项目中权限覆盖的优先级以及文章开头提到的如何通过配置区分开发与生产环境,不同环境将 model 写入到不同的数据集中,让我们接着聊。
二、dbt 项目中的配置优先级
在 dbt 项目中像 models、seeds 目录都代表了不同重要意义的文件,事实上我们会遇到对不同项目,或者项目下不同目录的 model 运行不同规则的情况;
举个例子,由于 dbt 项目能通过 package 直接引用三方 dbt 包,而这些包本质上就是一个独立的 dbt 项目,所以我现在希望 A 项目下的所有 model 运行后创建的都是 view,而 B 项目 models 的 a 目录下所有 model 创建的都是 table,b 目录下创建的都是 view,我们可以在 dbt_project 文件中添加如下配置:
models:
A:
+materialized: view
B:
a:
+materialized: table
b:
+materialized: view
其实你已经发现了,与常规项目配置中以项目作为开头不同,dbt 是以 models 、seeds 这些特殊含义的字段作为开头,然后由项目到目录,由目录到具体文件对不同层级下不同文件定义不同的配置规则,因此如果你需要对 models 以及 seeds 做不同的配置,你完全可以定义类似如下的配置代码:
models:
A:
a:
+materialized: table
+schema: "{{ 'mc_data_statistics' if target.name == 'dev' else 'details' }}"
+enabled: true
b:
+materialized: view
+enabled: false
seeds:
A:
+schema: "{{ 'mc_data_statistics' if target.name == 'dev' else 'ga4' }}"
所以让我们再回头理解上文中的配置文件,如下图:
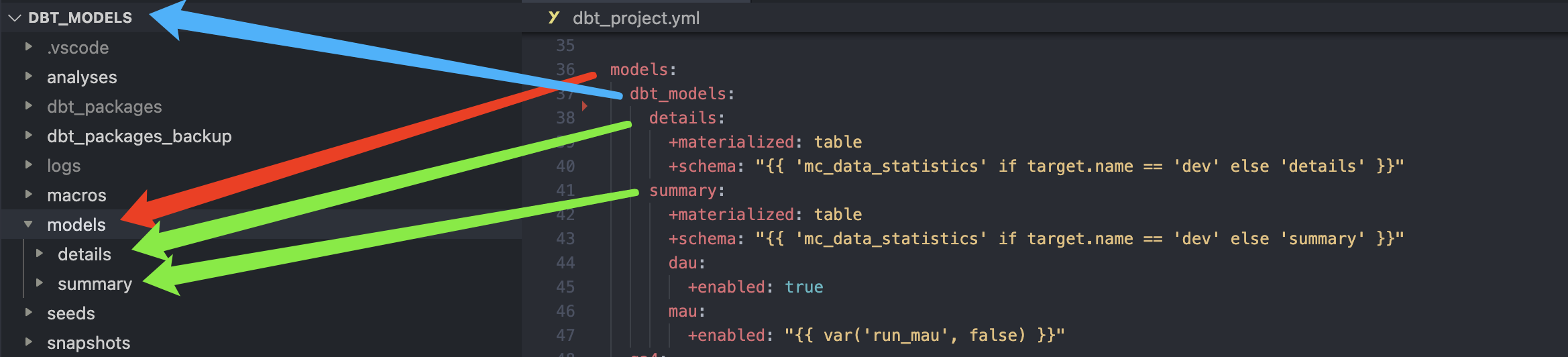
我们其实是在定义 models 相关的配置,同时指定了是为 dbt_models 这个项目做 model 的配置,然后我们为 models 下两个不同的文件夹 details 和 summary 下的 model 定义了不同的配置。
需要注意的是 dbt 项目配置优先级中目录层级越靠下权重越高,举个例子,即便我们为 summary 目录下定义了所有 model 运行都得创建 table,但是我现在就是希望这个目录下的 dau.sql 运行后创建的就是 view,怎么做呢?两种做法,一种是在配置下指定文件夹,然后单独设置 materialized:
models:
dbt_models: -- project name
summary: -- folder name
+materialized: table
dau: -- file name
+materialized: view
第二种做法就是在某个文件上方直接通过宏单独定义配置,比如:
-- dau.sql
{{ config(materialized='view') }}
select
...
可能有点啰嗦,但到这里我们介绍了如何对 models 或者 seeds 进行不同层级的配置定义。
三、区分开发与生产环境并配置数据集
在上方代码中类似 +schema: "{{ 'mc_data_statistics' if target.name == 'dev' else 'details' }}" 的代码已经出现了多次,这里我们顺带解释如何通过配置达到不同目录在不同环境下写入到不同数据集的目的。
为了方便理解,我将上方两个配置文件中核心再做一次摘要:
-- profiles
bigquery_profile:
target: prod
outputs:
dev:
dataset: dev
prod:
dataset: dbt_models
-- dbt_project
dbt_models:
details:
+materialized: table
+schema: "{{ 'mc_data_statistics' if target.name == 'dev' else 'details' }}"
事实上,我们能通过 profiles 配置中的 dataset 字段以及 dbt_project 中的 schema 字段用于控制在 dev 或者 prod 模式下,将 details 下的所有 model 写入到不同的数据集。
当我们运行的是 dev 时,那么 details 目录下的 所有 model 会被写入到 dev + mc_data_statistics也就是 dev_mc_data_statistics数据集中;同理,当运行的是 prod 环境,那么 details 下的所有 model 会被写入到 dbt_models_details 数据集中,很好理解不是吗?
为什么需要这样做呢?因为对于一个 dbt 项目而言,它的 model 定义数量可能会非常庞大,如果我们不区分环境,对于实际开发中如何区分 model 会显得非常麻烦;
还有一种情况,比如我现在的项目中使用了 dbt-ga4 的三方包,这是一个专门用来处理 ga 事件的 dbt 项目,我希望所有 ga model 都被归纳到一个单独的数据集,而不是跟我自身项目的 model 混合在一起,于是我对于我自己的项目预计 ga4 这个项目单独做了数据集的配置,如下:
models:
dbt_models:
details:
+materialized: table
+schema: "{{ 'mc_data_statistics' if target.name == 'dev' else 'details' }}"
summary:
+materialized: table
+schema: "{{ 'mc_data_statistics' if target.name == 'dev' else 'summary' }}"
ga4:
+schema: "{{ 'mc_data_statistics' if target.name == 'dev' else 'ga4' }}"
在 dev 模式下,所有的模型都会被写入到 dev_mc_data_statistics 数据集,而在 prod 模式下,details 目录下的模型会被写入到 dbt_models_details,summary 的所有 model 会被写入到 dbt_models_summary,而 ga4 这个项目的所有 model 都会被写入到 dbt_models_ga4,这样不同项目以及不同目录都拥有自己独立的数据集,在开发中我们也能非常清晰方便的去区分以及测试它们。
同理,我们有时候也需要为 seeds 区分不同的数据集,这里提供一个示例代码:
seeds:
ga4:
+schema: "{{ 'mc_data_statistics' if target.name == 'dev' else 'ga4' }}"
四、model 的禁用与命令传参
为了方便理解,我们假定现在有一个需求,我们需要在项目中统计产品的日活跃用户的 dau 以及月活跃用户的 mau,很显然, dau应该每天更新,而 mau 应该是在每个月的1号去更新上个月的数据,所以如果我们每天更新 dau 时就不应该一并更新 mau,不然 mau 每天需要查询的数据库额度就非常大了,应该怎么做呢?
其实有两种办法,第一种就是我们对日活与月活两个模型都不做禁用,只是在执行命令上做排除区分,比如我们定义两条命令:
-- Update all models except mau, including dau
dbt run --exclude mau
-- Update mau separately
dbt run --select mau
如上,我们就分别定义了两条命令,第一条更新除了 mau 之外的所有模型,当然会更新 dau;而第二条命令用于单独更新 mau。
当然,我们还可以通过配置 model 的禁用来解决这个问题,比如我在 dbt_project 中定义了如下配置:
models:
dbt_models:
summary:
dau:
+enabled: true
mau:
+enabled: "{{ var('run_mau', false) }}"
我们默认 dau 的 enabled 为 true,也就是说只要我们运行 dbt run dau 就能得到更新,而对于 mau 的禁用我们配置了 {{ var('run_mau', false) }},什么意思呢?这里我们其实为命令提前设置了一个动态参数,同样还是两条命令用于区分更新日活与月活:
-- Update all models
dbt run
-- Update mau
dbt run --models mau --vars 'run_mau: true'
由于我们配置了 mau 的 enabled,在执行 dnt run 时因为没传递参数,因此 var('run_mau', false) 是 false,mau 因此并不会被更新。而当我们运行 dbt run --models mau --vars 'run_mau: true' 时指定了 run_mau 为 true,从而让 mau 的 enabled 变成了 true, mau 解禁顺利被更新。
需要注意的是 enabled 一旦被设置为 false,那么表示这个 model 一定不会被更新,我们经常会有一些暂时用不上但是又不适合被删除的 model,那么通过禁用能很好的屏蔽这些 model,而且你也不需要重复的去修改你应该运行的命令,毕竟一旦需要排除的 model 比较多,通过 --exclude 也会非常麻烦,而 enabled 此时就非常有用了,而关于如何动态禁用模型,我们在上面也给出了示例。
五、引用数据表的三种方式
dbt 项目中本质所做的事就是数据加工,那么数据来源自然需要先引用才能做进一步的查询,如何引用数据表呢?其实有三种方式。
5.1 数据库名称固定引用
由于我们在 profile 配置中已经对目标数据库做了访问授权,所以正常来说所有表我们都能通过 数据库名 + 数据集名 + 表名 来访问某张表,比如:
SELECT
user_id AS uid
FROM
'notta-data-analytics.dbt_models_ga4.base_ga4__events'
5.2 source 引用
上述引用非常简单,但暴露了一个问题,前文我们提到 model 执行可以通过配置区分写入到数据集,而对于同一个 model 的数据原来引用,我也希望 dev 和 prod 引用不同数据集的表,毕竟在开发时我们一般都会准备测试的数据,而不用影响生产的数据,这很常见,这时候我们就可以通过定义 source 来解决这个问题,比如我先定义了如下 source 配置:
version: 2
sources:
- name: Summary
database: "{{ target.project }}"
schema: "{{ 'dev_mc_data_statistics' if target.name == 'dev' else 'dbt_models_summary' }}"
loader: Manual
tables:
- name: exchange_rates
description: Each record represents an exchange_rates to USD
columns:
- name: currency
- name: rate
- name: base_ga4__events
以上是一个 source 的配置示例,我们来快速了解定义的含义
name:source 的名称,在后续引用表时需要用到。
database:数据库的名称,这里我们定义的 target.project 实际取的是 profile 配置中的 project 字段,关于这里的配置我上面有提供代码,所以它最终取的是 notta-data-analytics。
schema:数据集名称,需要注意的是与 dbt_project 中的环境区分不同,source 中不支持 profile 中的 dataset 的拼接,所以这里我们得提供完整的数据集名称,再通过 target.name 做环境区分。
tables:这里就是我们为 source 提前定义的 table 名称,比如这个配置中我们就为此配置定义了 exchange_rates 与 base_ga4__events两张数据表,当我们需要使用这两张表时可以这样引用:
SELECT
uid,
FROM {{ source('Summary', 'exchange_rates') }}
可以看到这里的 Summary 就是我们在 source 配置中所定义的名称,而后面的 exchange_rates 就是实际的表名。
5.3 通过 ref 引用
我在上篇文章提到,实际的 model 执行一定有先后顺序,假设 model a 依赖了 model b,而 model b 又依赖了 model c,那么如果 model a 能顺利执行的前提,一定是 model b 与 c 都按顺序提前更新好,怎么做呢?这里直接告诉大家,如果我们需要让 model 维护正确的更新顺序,那么就一定得通过 ref 来引用,如下:
-- model a
SELECT * FROM {{ ref('model_b') }}
-- model b
SELECT * FROM {{ ref('model_c') }}
在这种情况下,只要我们执行 dbt run,那么 dbt 一定会先更新 model c ,其次更新 b 以及 a,dbt 会根据 ref 关系自动帮助我们维护好这个关系,是不是非常棒!
当然,如果有一些数据表是静态表,比如我们通过 dbt seed 添加的静态数据表,由于这些表至始至终一直存在,且不存在更新的关系,那么我们完全可以用任意的引用方式来引用它们,毕竟它们不需要更新且一直存在。
总结来说,source 或者数据库名称引用的形式适合引用数据库中的已经存在的源表,而 ref 适合引用由 dbt 项目自身产生的动态表,毕竟后者有依赖关系在,通过 ref 能很好解决这个问题。
你可能会好奇,为什么 dbt 会知道 model 的依赖顺序,我们简单来理解,当我们在一个模型中使用 ref 引用另一个模型时,dbt 会在这两个模型之间创建一个依赖关系,dbt 在运行时,会按照 ref 和 source 方法,构造出所有模型的 DAG(有向无环图),再按照 DAG 的顺序执行,因此放心大胆的去引用,顺序关系我们无需主动去关心。
六、定义和使用宏,如何在 sql 中使用 for 循环
在 dbt 中我们可能会有这样的场景,我希望像写 js 或者 java 那样封装部分可复用的方法,供我在多个 sql 文件中使用,那么宏就能派上用场,打个比方,我在需要定义一个 dau 用于统计日活跃用户,那么我更新的时间应该是在今天去更新昨天的数据,这样昨天的数据才是精准且有效的,那么我需要在当天知道所谓的昨天是什么时候,于是我在 macros 目录下定义了一个名为 get_yesterday的文件,其中代码如下:
-- Get yesterday's date For example, if today is 2023-12-03, then we get '20231202'.
{% macro get_yesterday() %}
{% set yesterday = run_started_at - modules.datetime.timedelta(days=1) %}
{% set formatted_date = yesterday.strftime('%Y%m%d') %}
{{ return(formatted_date) }}
{% endmacro %}
然后我在 dau 文件中引用这个宏,代码如下:
SELECT *
FROM your_table
WHERE date = '{{ get_yesterday() }}'
-- or
{% set yesterday = get_past_three_days() %}
SELECT *
FROM your_table
WHERE date = yesterday
宏的作用比你想的要强大,比如我现在 dau 希望更新过去三天的数据而不是仅昨天一天,那么我就需要通过 for 循环来遍历日历,在这里我同样通过宏来给一个示例,我先定义了一个获取今天之前三天的宏,它会返回一个包含三个日历的数组:
-- Get yesterday's date For example, if today is 2023-12-18, then we get ['20231215', '20231216', '20231217'].
{% macro get_past_three_days() %}
{% set three_days_ago = run_started_at - modules.datetime.timedelta(days=3) %}
{% set two_days_ago = run_started_at - modules.datetime.timedelta(days=2) %}
{% set yesterday = run_started_at - modules.datetime.timedelta(days=1) %}
{% set formatted_dates = [three_days_ago.strftime('%Y%m%d'), two_days_ago.strftime('%Y%m%d'), yesterday.strftime('%Y%m%d')] %}
{{ return(formatted_dates) }}
{% endmacro %}
然后我在 dau 中引用这个这个宏,并通过 for 循环做遍历查询以及结果的最终拼接:
{% set past_three_days = get_past_three_days() %}
WITH all_days AS (
{% for date in past_three_days %}
SELECT
*
FROM
(SELECT
parse_date('%Y%m%d',event_date) as event_date_dt,
COUNT(DISTINCT user_pseudo_id) as dau_web
FROM
`notta-data-analytics.analytics_345009513.events_{{ date }}`,
UNNEST(event_params) as params
GROUP BY event_date_dt) web,
-- ...
{% if not loop.last %} UNION ALL {% endif %}
{% endfor %}
)
SELECT * FROM all_days
在上述代码中,我们就通过宏对查询做了遍历,而遍历的对象就是过去三天的宏所返回的日期数组,在遍历过程中只要遍历没结束,我们通过 UNION ALL 进行拼接,最终得到三个日期所对应的日活数,最终我们将这三个日期维度的数更新到 dau 表中,达到过去三天 dau 数据更新的目的。
需要注意的是,一般宏的封装不建议跟 sql 定义在一起,比如上面 get_yesterday 的宏如果跟 sql 语句写在一个文件,在运行时可能会造成一些错误。
七、使用增量表
其实在上面展示宏的代码中,本质上 dau 和 mau 都应该是增量表,只是我不想代码量太多,让大家对于宏的理解过于困难,我删除了增量表配置的部分,首先,我们应该如何理解 dbt 中的增量表。
普通的 table:由 dbt 生产的数据表,它在数据库中有实体,会占用内存,每次更新都会完整的销毁以及重新创建。
增量表:也是 table,但是每次更新只更新指定日历的数据,比如 dau 只更新昨天的数据,那么再往之前的数据在更新时后不会被刷新,增量表也不会在每次更新时都重新销毁和新建,毕竟过往的日活数据是恒定的,由此可见增量表的查询额度会更小,性能也会更高。
但事实上并不是所有的数据源查询都适合做增量表,为了方便大家理解,这里我直接以 GA 作为例子,GA 是 Google 做用户埋点行为分析的工具,如果我们提前添加了埋点,那么比如用户的点击行为,停留时间等等都能通过埋点事件上报到 GA 平台,而 GA 数据又能直接同步到 bigquery 作为数据源,这里给大家展示下 GA 的源数据,可以很清晰的看到它们都是时间分片表:

简单理解,GA 的数据是以天为维度,一天一张表,那么对于我而言,我永远只用查昨天这一天的数据就好了,比如今天是20240215,那么当我的 dau 执行时,我需要查询的表的日历维度是 20240214 这一天,这也是为什么我在上面定义获取昨天日历宏的原因,因为数据源只是昨天一天,那么数据源就非常小,我在查询完后再通过增量表把昨天的数据写入进去,从而达到了从查询到更新最小查询量的目的。
为了假设大家理解,我假定现在有一个需求是统计每天的注册用户,其实这个需求与 dau 类似,我们真正应该做的是在今天更新 model,去查询过去几天的数据,并完成注册用户数量的更新,这里我直接提供完整的增量表的代码:
{% set partitions_to_replace = [] %}
{% for i in range(3) %}
{% set partitions_to_replace = partitions_to_replace.append('date_sub(current_date, interval ' + (i+1)|string + ' day)') %}
{% endfor %}
{{
config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by={
"field": "event_date_dt",
"data_type": "date",
},
partitions = partitions_to_replace,
)
}}
{% set past_three_days = get_past_three_days() %}
with combined_data as (
{% for date in past_three_days %}
SELECT
user_id AS uid,
COALESCE(NULLIF(geo.country, ''), 'unknown') AS country,
COALESCE(NULLIF(geo.city, ''), 'unknown') AS city,
CASE
WHEN device.operating_system = 'Android' THEN 1
WHEN device.operating_system = 'iOS' THEN 2
ELSE 99
END AS device,
parse_date('%Y%m%d',event_date) as event_date_dt
FROM
`notta-data-analytics.analytics_234597866.events_{{ date }}`
WHERE
event_name = 'sign_up_flutter_success_new' AND
REGEXP_CONTAINS(user_id, r'^[0-9]+$') AND
user_id IS NOT NULL
{% if not loop.last %} UNION ALL {% endif %}
{% endfor %}
),
numbered_data as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY uid ORDER BY event_date_dt) AS row_num
FROM combined_data
)
SELECT
uid,
country,
city,
device,
event_date_dt
FROM numbered_data
WHERE row_num = 1
我们先将目光集中在下面你的代码:
{% set partitions_to_replace = [] %}
{% for i in range(3) %}
{% set partitions_to_replace = partitions_to_replace.append('date_sub(current_date, interval ' + (i+1)|string + ' day)') %}
{% endfor %}
在上述代码中,我们定义了一个名为 partitions_to_replace 的数组,这是一个包含了过去三天日期的数组,例如:
['20240214', '20240213', '20240212']
这个数组的目的其实就是在告知增量表希望更新的日期维度,毕竟你要做增量,总得告诉 dbt 你希望更新过去哪些日期的数据。
让我们再解释下如下配置,这一段也是增量表最为关键的配置:
{{
config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by={
"field": "event_date_dt",
"data_type": "date",
},
partitions = partitions_to_replace,
)
}}
materialized :告诉 dbt 当前的表是一个增量表。
partition_by:此字段用于告诉 dbt 我们增量表按什么字段进行分区,比如我们做注册用户统计一定是按日期来分区,所以这里我提供的 field 是 event_date_dt,而event_date_dt是我们下方 sql 查询中的一个字段,记住,此字段一定得是 date 类型,如果你类型给的是数字或者字符串,都会导致增量表更新失败。
partitions:增量表更新的目标分区,比如我们希望更新过去三天的注册用户数量,这里我们直接提供了上面通过宏得到的日期数组,这样在下方 sql 查询过去三天的数据后,它会按照 partitions 作为目标,对过去三天的数据一一做更新。
OK,现在来到具体的 sql 查询部分:
{% set past_three_days = get_past_three_days() %}
with combined_data as (
{% for date in past_three_days %}
SELECT
user_id AS uid,
COALESCE(NULLIF(geo.country, ''), 'unknown') AS country,
COALESCE(NULLIF(geo.city, ''), 'unknown') AS city,
parse_date('%Y%m%d',event_date) as event_date_dt
FROM
`notta-data-analytics.analytics_234597866.events_{{ date }}`
WHERE
event_name = 'sign_up_flutter_success_new' AND
REGEXP_CONTAINS(user_id, r'^[0-9]+$') AND
user_id IS NOT NULL
{% if not loop.last %} UNION ALL {% endif %}
{% endfor %}
),
numbered_data as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY uid ORDER BY event_date_dt) AS row_num
FROM combined_data
)
SELECT
uid,
country,
city,
event_date_dt
FROM numbered_data
WHERE row_num = 1
这代码代码里,我们遍历了 past_three_days,并通过 notta-data-analytics.analytics_234597866.events_{{ date }} 动态查询过去三天的时间分片表,它实际上等于:
notta-data-analytics.analytics_234597866.events_20240214
然后我们做了部分的条件判断以及脏数据清晰,并在循环中对过去三天的数据进行拼接组合,最终通过 partitions 的映射关系,完成了过去三天的注册用户数据的更新。
而关于上文提到的 event_date_dt,可以看到我使用了 parse_date('%Y%m%d',event_date) 提前将 event_date 字段转成了日期类型,并提供给增量表做分区。
那么到这里我们展示了增量表的使用,我知道你可能还有些疑惑,但没关系,无论是宏还是增量表,前提是你得知道有它们,至于具体的业务你完全可以站在宏的角度来使用 GPT 满足你具体的场景,不然你可能怎么去提问都不清楚。
那么到这里,我们介绍完了本篇所有的知识点,本篇的内容其实没有非常强的关联性,它们都是我在日常工作遇到的一些困惑,以及我个人觉得非常有用的知识点,我希望对你也能有所帮助。
当然,我相信你可能也会产生新的疑问,比如为什么文章中做 sign_up 统计一定是更新了过去三天的数据而不是只更新昨天,这其实跟 GA 的行为有关,由于篇幅问题我打算在 GA 数据处理篇章单独解释。
其次,对于 dbt core 的基础介绍到这里已经基本结束了,下篇文章我打算围绕 dbt cloud 展开,来教会大家如果通过云平台做到 dbt 模型的自动化更新,从而完全解决双手,敬请期待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号