
从 DMAIC 方法论说起,记一个长链接 bug 的排查全过程

引
本文是我在前端团队的第四次分享,在过去我曾做过一次关于 bug 排查的全流程的排查分析,文档:客户线上反馈:从信息搜集到疑难 bug 排查全流程经验分享,但这个文章更侧重我过去几年的排查经验,而非方法论,刚好最近一直在做项目质量改进的事,过程依赖了 DMAIC 方法论,后续我也总结了自己的排查方法,其实与这个方法论高度相似。恰好前段时间帮忙解决了一个长链接(websocket)的疑难问题,正好拿这个例子来证明方法论,所以原来的两个分享,最终合并成了这篇文章,接下来就是分享原文了。
壹 ❀ 为什么做这次分享?
大家都知道我们从六月开始就一直在做项目质量改进的事情,其实到现在,无论是迭代延期情况还是整体项目缺陷统计情况,我相信大家都多少能感受到我们的质量确实提升了,而且不是错觉。不知道大家是否好奇质量改进我们到底是怎么做的,迭代质量同步给大家时我们总是会附带一些改进点以及在流程中去落实一些东西,这些结论是如何得到?总不能是拍脑袋想到的,其实这个过程就依赖了 DMAIC 方法论。
那么为什么要做这次分享?两个原因:
- 第一是质量改进并不是这一个季度或者这半年的事情,而是未来我们一直要去做的一件事,即便迭代质量在未来得到了很好的改善,我们依旧需要去关注迭代以及工作流中的问题,发现缺陷并改进问题,所以让大家都知晓方法论以及如何实操就非常重要(而不是面对盲目猜测没任何依据)
- 第二点是 DMAIC 方法论其实不仅仅适用于流程改进这一个方向,我在之前做过 bug 分享心得的分享,后来我仔细思考了自己排查问题的方法,其实总结下来我的做法也是 DMAIC 的精简版,这个我在本次分享的后续会顺带一起讲。
所以说了这么多,DMAIC 方法论在系统化解决问题上非常有效,它更像一种抽象经验的总结,在一些问题解决上让我们有套路可循,那么什么是 DMAIC 方法论呢?我们接着说。
另外,方法论听起来可能确实是很虚的东西,就跟读书时代我们背毛概一样,总有种雾里看花的感觉,但本次分析我会结合非常多的实际的例子来带大家理解方法,雾可能还在但不会那么浓,之后就需要大家去实践去总结,毕竟我只能带大家看花,触碰到花还是得靠各位自己。
贰 ❀ DMAIC 与迭代质量改进
贰 ❀ 壹 关于 DMAIC 方法论
DMAIC是六西格玛管理中的五个关键步骤,它取自五个单词的首字母,分别是定义(Define)、测量(Measure)、分析(Analyze)、改进(Improve)和控制(Control)这五个阶段,我们分别解释下五个步骤:
1. D(Define 阶段)
Define 阶段作为五个步骤的开始其实是非常重要的一步,旨在清晰明确的定义问题和目标。
需要前置让大家知晓的是,DMAIC 能数据化可测量的帮助我们解决一些长期问题,但它同时需要团队多方协助才能最终目的。设想下假设我们一开始的定义的目标就模棱两可并难以衡量,那么后续的步骤的展开你都会觉得困难,比如同一个目标定义模糊,达到目标的关键步骤,设置在团队协作上不同人的理解可能都难达成一致。
除了清晰的问题以及目标定义上,我们还需要定义团队分工以及不同职责的责任范围,比如迭代质量宏观来看好像就是项目质量不好,但问题可能出在研发代码质量,可能出在项目上线过于繁琐,也可能出现在测试流程不完善上,包括现在我们现在所做的迭代数据分析,其中 bug 分布以及用例通过率的数据统计分析其实都是不同团队在分工合作。
而对于很多问题,如果我直接告诉你问题本质是什么,大多数情况下你都知道这个问题怎么解决,互联网这么发达,什么问题都有解决方案。所以很多事难就难在问题是什么都不知道,万事开头难不是吗?像我们去排查一些疑难 bug 也是如此,这个后续我会专门讲。
(题外话,DMAIC 很依赖团队配合,包括 bug 问题记得提醒大家去选择等等,这些都不是我一个人能推动的,都需要借助大家的力量)
2. M(Measure 阶段)
在定义问题或者目标后,我们就需要来到衡量(测量)问题,Measure 阶段讲究用数据说话,常见的有数据分析,问卷调查等等,依靠数据统计来证实问题,而不是凭空猜测。当然,数据搜集需要保证数据的真实性以及完整性,所以在目前 bug 类型统计以及分析上,我们才多次要求大家理解不同类型的含义,对应的补全 bug 类型填写等等。
3. A(Analyze 阶段)
Analyze 表示分析阶段。数据搜集后其实大多数情况下我们也只能看到问题的表现而不是本质。比如我们在之前某个迭代发现 web 端很多接口失败业务提示文案错误,展示不对的 bug,这些问题照理说研发在自测阶段问题就应该能直接发现,通过数据分析以及对应的沟通获取信息,然后我们就得知研发在根据用例自测时,本能的只考虑了逻辑最正确的样子,而没有主动去留意功能失败,接口失败这些异常情况的表现,这其实是研发思维的通病,所以我们才需要以数据支撑去做分析,找出问题并想办法解决问题。
4. I(Improve 阶段)
承接分析阶段,如果我们找出了问题,就应该对应的得出改进建议了,需要注意的是,我们的改进理论上应该是可衡量,可观测,可验收的。
还是拿 bug 举例,比如我们之前发现参数效验的问题非常多,服务端也经常出现接口情况参数不匹配出现的报错,在分析后我们在web 端统一做了接口效验的封装,那么这个改进在后续我们能直接通过接下来迭代参数效验问题占比的情况来衡量此问题是否被有效解决。
5. C(Control 阶段)
简单理解,其实大多数问题并不能短期内直接看到效果以及得到改善,大多数情况下,我们可能需要打持久战在保证改进落实的同时,持续跟进问题的改善情况,甚至对于方案也要进行持续改进,而我们现在做的项目质量改进本质上也是一个长期任务,它并能通过一个迭代的分析来彻底解决,而是需要不断迭代不断优化不断改善以达到最终提升整体项目质量的目的。
贰 ❀ 贰 质量改进如何融入 DAMIC
聊了 DMAIC ,我们来说说目前项目质量改进是如何落实 DMAIC 的。
前提是,我们都知道目前项目质量有一些问题,但是如果让大家定义项目质量差的问题是什么,我相信大家其实都很难答出来。因为坏的结果只是结果,而造成如此的原因可能是整个工作流中的任意一环,因为缺乏数据支撑,我们很难精准定义问题,更别说提出改进建议来落实了。
DMAIC 讲的就是数据支撑,既然如此,我们就先不定义问题,而是将质量改进分散到半年或者一年的迭代中。我们会分别统计每个迭代的数据,包括测试通过率,bug 类型分布等等数据,再分析数据定义问题,再根据问题讨论出可观测的解决策略,再为大家做同步。
这会是一个非常长期的过程,很多东西都需要反复提醒去强化大家的记忆,做流程其实是个非常的痛苦的事,但目前我们正在号召大家一起去落实,而且已经很明显的看到改善了。
关于目前我们的 DAMIC ,流程基本如下:
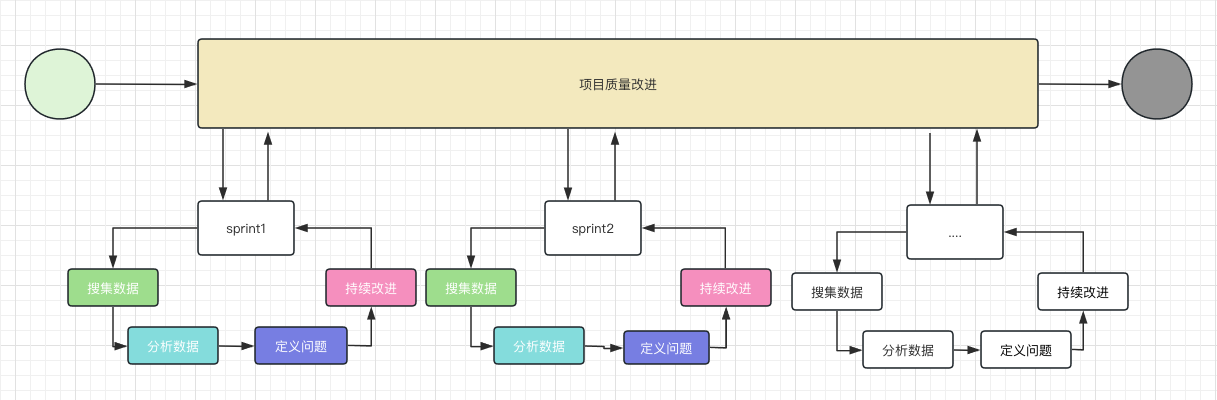
叁 ❀ 现象、原因与问题的定义
我在几个月前曾分享过我解决问题以及排查问题的思路,与其说是思路,不如说是直接总结了排查问题的一些固有套路,算经验而非方法论。方法论其实是较为抽象的东西,它有点像概念,目的相同,但不同人落实下去可能做法均有差异。
我在了解完 DAMIC 方法后也仔细思考过自己解决 bug 的思维方式,仔细总结下来,我发现我的思维其实就是 DAMIC 的精简版(所以我说这个方法不仅能用于解决流程之类的罐体),大致做法是 分析现象 --- 定义问题 --- 提出猜想 --- 验证,如果一个思路错误,那就继续从分析现象开始不断循环直到找到最终真相。
这听起来很简单,但事实上大多数研发在看待问题时都会停留在现象这一层,而没办法走到问题是什么这一步,就更别提如何解决了。你可能不知道我在说什么,我来举几个例子。
以项目质量差为例,即便我们将项目问题拆解到一个一个迭代来看,我想问的是,迭代 bug 多以及迭代延期导致项目质量差,这里的迭代延期以及 bug 多是造成项目质量差的原因吗?这两个问题是造成项目质量差的问题所在吗?
其实不是,准确来说,这两个问题只是项目质量差的现象,如果我立刻提出改进建议,其实你会有种隔雾看花的感觉,你知道这两个问题,但真要去做会有点无力。
因此我们统计数据,通过数据支撑来拨开迷雾,与对应的研发沟通,找到延期或者 某种 bug 类型多的原因,从而定义问题。准确来说现象只是发现问题引子,你不能以现象作为依据来定义以及解决问题。
再比如某次上线发版出现事故,当有人问为什么出现此问题,可能有同学就说这个问题是因为服务部署遗漏了一个服务所导致,我想说的是,遗漏了一个服务是问题所在吗?它只能代表这一次事故的原因而已,核心问题也许是我们部署流程文档不完善,缺少了部署检查的核心信息,多思考一层也许离问题就更进一步了。
同样,举一个研发都非常熟悉的例子,测试给我提的 bug 单描述其实都是现象,原因是什么,问题是什么其实很多我们也不清楚,需要去复现去读代码,这些都是为了去定位原因找出问题,知晓了问题所在才知道解决问题的办法。
那么现象是毫无用处的吗?其实并不是,现象是找出问题的触发器,我就经常通过现象来作为定位问题的灵感,比如一些非常疑刁钻的问题,我都会习惯去对应技术的 GitHub 仓库 issues 列表或者 Google 问题列表来搜有没有人遇到我们类似的问题,我这么做其实就是在通过现象来找现象,如果运气好你就是能通过现象匹配知道别人对于问题的描述,通过这种办法我们再来根据自己的现象场景来清晰自己的问题。
再举个例子,前端时间测试跟我提到音频播放 option + space 快捷键暂停失效了,但是我怎么都复现不了。测试甚至跟我说音频分享出去作为分享链接打开就能快捷键暂停,自己不分享暂停就是不行,听起来扑朔迷离。有同学肯定就已经在思考分享和不分享的区别,这个思路是对的,找差异是解决 bug 非常重要的手段,但问题是这就是完全相同的逻辑,快捷键怎么可能受这个影响,测试给提供的线索可能是他在多种浏览器多套环境下混乱记忆的线索。
于是我去 Safari 论坛看了下,根据快捷键大致搜了下 issues 清单,发现一年前有人提到过可能跟输入法可能有关系,我用的是搜过,那么测试复现问题时用的是什么浏览器以及什么输入法呢?于是抱着这个疑问我找到了测试,简单的对比发现,原来问题只有是在 Safari 浏览器以及 mac 自带输入法的日语模式下才会有这个问题,如果切到英语就正常,以及如果换浏览器或者输入法也都正常,那这就证明这就是 Safari 加 mac 自带输入法日语模式下的快捷键 bug,而整个问题下来,我其实用的就是现象去提出猜想,问题是什么?其实我至今都不知道,也许只有 Safari 自己的开发才知道。
聊了这么多,我知道这些都显得很抽象,但我还是在很多问题上不要把现象当成是问题本身,但我也希望你能善于利用现象。所以总结来讲,不要把现象当问题,但是要善于利用现象找问题。
关于现象的利用,正好我在之前帮忙排查了一个比较疑难的长链接连接失败的问题,接下来借助方法论,我想通过此问题的排查思路来做个分享。
肆 ❀ 长链接链接失败排查思路分享
在分享之前,先给大家说下这个 bug 是什么。我们在长链接推送上依赖了一个 socket.io 的库(做 websocket 通信),但从做了日志监控以来,我们发现一直都有客户偶现长链接连接失败的问题,导致功能使用异常,此问题偶现,而且我们自己完全无法复现。
我前面说了,我对于很多问题的排查思路都是 分析现象 --- 定义问题 --- 提出猜想 --- 验证,使用现象来驱动排查能帮我更快的找到关键问题点,现在我有两个问题问大家的是:
- 第一个问题是,如果让大家来排查这个问题,大家是否会觉得自己需要非常了解 websocket 底层协议,以及了解 socket 库的底层原理呢?事实上我在后续确实浅读了 socket 的源码,但我非常清楚自己需要看什么,以及关注点在哪,我看源码仅仅是验证自己的猜想以及定义下一步行动,直到最后问题解决,我其实都不知道什么 websocket 底层原理到底干了啥。而我在整个排查中,其实就是不断发现现象,提出问题以及验证猜想。
- 第二个问题是,如果现在要让你读 socket 源码,你怎么读?从哪里开始读?难道从初始化开始一点点跟?那效率就太低了,而且中间一定会被各种不重要的逻辑影响自己的判断。
肆 ❀ 壹 分析日志现象,找到源码阅读切入点
我在接手问题的时候,前端已经开启了 socket.io 的日志,我们在 logRocket(一个记录和replay用户操作的平台)上能看到部分失败用户的录屏,以及录屏控制台 socket.io 的输出日志,虽然都是链接失败的日志提示。我们在自己的环境控制台也能看到 socket.io 的日志,只是我们无法复现问题,所以看到的控制台日志都是成功的。
在看源码前,我的第一个关注点是 socket.io 链接成功和链接失败的日志区别在哪里,日志有没有共同点,比如日志是否相同,是否初始化就出了问题,还是初始化完全相同,是在后续执行产生了差异。差异是在哪一步产生的,那么这个点就是我源码阅读的切入点,只要从这里开始去读一读源码上下文,理解起来就非常高了(关注完全相同的日志没意义,它又没出问题),这就是对于问题现象的利用。
除此对比日志之外,我还去查阅了socket.io-client 与 engine.io-client 两个 GitHub 仓库的 issue 列表,看看有没有类似历史 issue 可以参考,目的前面说过了,看看是否有跟我们现象匹配的问题,以及从别人的提问中去拓展自己对于问题的看法和思路。
在看完 GitHub 仓库的 issue 后,看下来只有两条与无限重试但一直链接失败的问题有关,这个用户的 issue 的 socket.io 版本是 4.X,问题描述跟我们不太相同,不过 issue 中表示有 ping 超时的情况导致无法连接,我查看了我们这边关于 ping 的时间设置,分别为 "pingTimeout":60000,"pingInterval":25000 ,所以后续我找服务端确认了我们超时的时间情况,后续证明跟这块肯定没关系,所以这个点直接排除了。
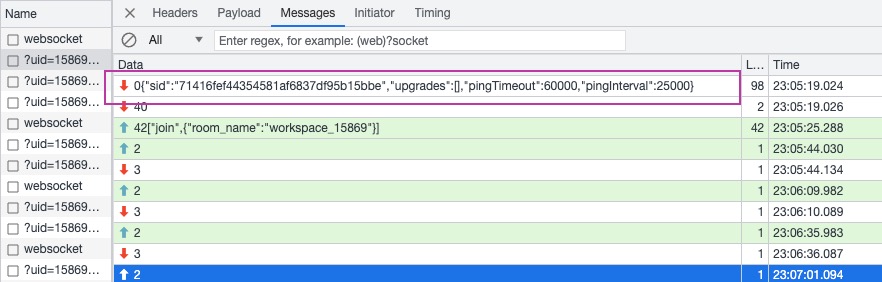
而关于成功和失败的日志对比我们可以看看下图

右边是成功的日志信息,左边是 logRocket 某个用户失败的信息,我们可以关注这几点:
-
两边都是以绿色框作为整个 socket 日志记录的开始,比较奇怪的是左边绿框相对于右边绿框,它缺少了
socket.io-client:url parse https://xxx.notta.io与socket.io-client new io instance for ``https://xxx.notta.io这两步,我问了相关同学,他说 logRocket 记录的可能不全,后面补全了日志,但是控制台输出的还是不全,那么这里到底是 logRocket 日志缺失?还是前端少了几个步骤导致连接失败?(后续确认就是 logRocket 日志自己丢了) -
两边日志的共同点在蓝色框区域,可以发现都存在
readyState的关闭,打开一个链接,创建和设置transport "websocket",然后在五步后差异来了(红色打勾处),左边通知多少毫秒后即将超时,但是右边通知多少毫秒后即将链接,这里的差异是什么,为什么一个即将成功,另一个即将失败,源码层我会跟一下这两处的代码执行。 -
如果链接成功,服务端一定会推送一条
{"sid":"71416fef44354581af6837df95b15bbe","upgrades":[],"pingTimeout":60000,"pingInterval":25000}的数据过来,这里可以看上图右边紫色方框区域,以及 websocket 通信本地的截图,那么我对于服务端就有几个问题 :
-
服务端真的有收到客户端的通知吗?(因为 logRocket 失败日志开头有几条缺失,服务端能否确认有没有接收到)
-
服务端能对比成功和失败情况下服务端接收的步骤差异吗,知晓了步骤差异,可能才好决定接下来的动作。
-
服务端真的有返回上面这条数据回来吗?或者说服务端有走到返回数据
"sid":"61ebe1686a194b16a893dcd939e17264","upgrades...这一步吗?
-
-
关于其它的验证,我在 logRocket 日志中看到了一条
ResizeObserver loop limit exceeded的报错,处于好奇我去搜了下,在一些问题记录中我发现了 loom 插件的字眼,而 loom 业务也是做音视频录制,所以突发奇想,会不会我们的客户也安装了其它类似竞品的插件,偶现导致我们部分业务崩溃,然后我尝试安装了 loom 插件,不过验证失败了,连接还是能成功,此问题在后续确认是其它的报错,可以排除。
除此之外,有几点我之前的排查会议没参加,有其它的几点我也比较关注,比如:
-
socket 前后端版本是否完全一致?是否是因为前后端版本不兼容才导致的偶现问题?(次猜测后续确认版本匹配)
-
链接失败的问题是一直存在的吗?还是在某个时期或者某个迭代突然出现的?如果能找到这个时间节点,我们就能通过需求改动来缩小范围,逐步确定可能造成的影响的功能。(此猜测后续确认问题一直存在,可以说是一个历史问题)
-
如果是前者,那可能跟我们前后端实现有关系,或者是版本的特定 bug。
-
如果是后者,这个时期我们有什么变量?改了什么业务没?
-
肆 ❀ 贰 根据切入点梳理源码,寻找问题点
因为上次已经对比了两份日志的差异,还是看下图。
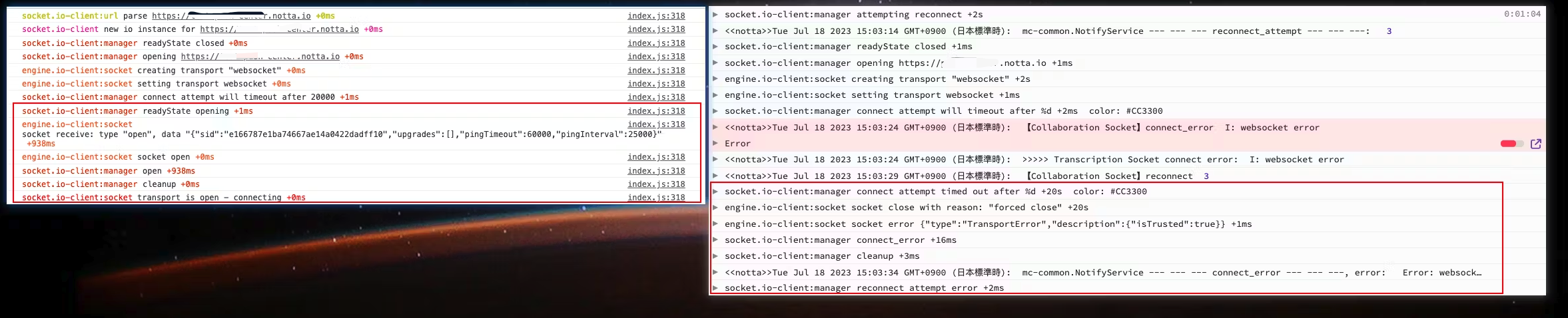
左边是直接一次连接成功,右边是经历失败后的重新连接,在红框之前其实两边的行为完全一致,直到来到 socket.io-client:manager connect attempt will timeout after 这一句之后,两边产生了差异,成功的一边提示
readyState opening,而失败日志提示 20S 都未连接成功因此超时,差异点在这里,所以源码切入点也就从这里开始,socket.io-client 与 engine.io-client 的源码逻辑相关代码如下:
// 日志输出 debug 前缀定义
var debug = require('debug')('socket.io-client:manager');
// 初次连接或者失败后重连走的都是同一个方法,方便梳理,删除了部分不影响理解的代码
Manager.prototype.open =
Manager.prototype.connect = function (fn, opts) {
// 这里对应日志 socket.io-client:manager readyState closed,this.readyState 默认值就是 false
debug('readyState %s', this.readyState);
// 这里对应日志 socket.io-client:manager opening https://test-push-center.notta.io
debug('opening %s', this.uri);
// 开始连接,因此 readyState 设置为 opening
this.readyState = 'opening';
// socket 连接成功的监听
var openSub = on(socket, 'open', function () {
// 执行具体的 open 方法
self.onopen();
fn && fn();
});
// socket 连接失败的监听
var errorSub = on(socket, 'error', function (data) {
// 这里对应日志 socket.io-client:manager connect_error
debug('connect_error');
//
self.cleanup();
// 重置 readyState 状态
self.readyState = 'closed';
self.emitAll('connect_error', data);
});
// 定时器核心逻辑
if (false !== this._timeout) {
var timeout = this._timeout;
// 这里对应日志 socket.io-client:manager connect attempt will timeout after %d +2ms
debug('connect attempt will timeout after %d', timeout);
// 定义定时器
var timer = setTimeout(function () {
// 这里对应日志 socket.io-client:manager connect attempt timed out after %d +20s
debug('connect attempt timed out after %d', timeout);
// 派发事件,socket 连接失败的监听被触发
socket.emit('error', 'timeout');
}, timeout);
this.subs.push({
// 为定时器添加销毁方法
destroy: function () {
clearTimeout(timer);
}
});
}
上述代码我按照 debug 日志补充了注释,我们关注的超时的日志输出其实就在 var timer = setTimeout 这个定时器里,且在this.subs.push中还提前定义了一个定时器销毁方法,定时器时间默认 20s 。
也就是说,一旦我们调用 connect 或者重连的 open 方法,这个方法内部都会内置一个超时报错定时器,只要等待 timeout 定时器没被主动销毁那就会报错,而现在生产环境的情况其实就是不断尝试 connect,不断等待 20S 超时然后报错。
在定时器上方,同时定义了一个 connect 连接成功的监听 var openSub = on 与连接失败的监听var errorSub = on,这两个方法内部都有调用一个cleanup方法,其实在这里里面就包含了清除定时器的逻辑,简而言之,只要成功了,socket 会主动清除报错定时器,这也是两边差异的原因。
关于cleanup的定义:
Manager.prototype.cleanup = function () {
// 这里对应日志 socket.io-client:manager cleanup
debug('cleanup');
var subsLength = this.subs.length;
for (var i = 0; i < subsLength; i++) {
// 取出之前定义的定时器销毁方法
var sub = this.subs.shift();
// 销毁定时器
sub.destroy();
}
};
那么现在问题就聚焦到了,什么情况下由哪里派发成功的监听,来清除定时器以及处理接下来的连接逻辑呢?我们再聚焦到如下代码:
// 响应服务端推送的数据包所执行的方法
Socket.prototype.onPacket = function (packet) {
if ('opening' === this.readyState || 'open' === this.readyState ||
'closing' === this.readyState) {
// 这里对应关键日志 engine.io-client:socket socket receive: type "open", data "{"sid":"e166787e1ba74667ae14a0422dadff10","upgrades":[],"pingTimeout":60000,"pingInterval":25000}"
debug('socket receive: type "%s", data "%s"', packet.type, packet.data);
this.emit('packet', packet);
// 心跳监听的派发
this.emit('heartbeat');
// 昨天我说了,客户端需要响应一条数据,其中就包含了一个 type 字段,这个字段直接决定是创建连接,还是保持心跳,或者报错
switch (packet.type) {
// 开始连接的派发
case 'open':
this.onHandshake(JSON.parse(packet.data));
break;
// 心跳的派发
case 'pong':
this.setPing();
this.emit('pong');
break;
// 报错的处理
case 'error':
var err = new Error('server error');
err.code = packet.data;
this.onError(err);
break;
case 'message':
this.emit('data', packet.data);
this.emit('message', packet.data);
break;
}
}
};
上面我说了,如果想连接成功,服务端必须推送一条{"sid":"324690113e864a68b0709bbb06f25d9e","upgrades":[],"pingTimeout":60000,"pingInterval":25000}数据过来,它同时对应了关键日志 engine.io-client:socket socket receive: type "open", data "{"sid":"e166787e1ba74667ae14a0422dadff10","upgrades":[],"pingTimeout":60000,"pingInterval":25000}"
在这条日志中有一个非常重要的字段 type,这将决定此时跟客户端的通信是创建连接还是保持心跳,亦或者报错或者消息通知。
但目前我在 logRocket 的失败日志中,没找到这条信息的推送,因此客户端没办法走到上面代码中的open操作,自然没办法连接成功了,以及 websocket 的["join",{"room_name":"workspace_15869"}]也没办法推送到服务端了。
后续我与服务端确认了当前可观察的日志,由于安全问题,目前生产并未添加 info 日志打印,所以我们也没有这块的日志,并不知道是以下哪种情况下:
{"sid":"324690113e864a68b0709bbb06f25d9e","upgrades这条关键数据服务端是否未推送?- 服务端有推送,但是
type类型并不是open? - 服务端有推送且
type是open,但客户端与服务端协议不一致导致并未成功接收? - 或者其它原因.....
之后为了方便服务端打日志,我查阅了服务端 socket 库的源码,确定了跟客户端 open 通信的代码块。

在此之前,服务端曾说他们看到日志中出现了connect字段,所以觉得是连上了,但是代码看下来,我们真正关心的是上图 connect 上面的 packet.OPEN,这个直接决定了给客户端的包到底有没有发,以及类型发的对不对。
那么到这里排查接力就来到了服务端,之后服务端也针对我的提问提出了猜想以及下一步日志验证计划:
- 关于客户端没有触发发送open包,服务端也可以通过跟踪
"Sending packet OPEN data"日志观察确定,等待info日志上线可以确定。 - 关于服务端发送的open包没有送达客户端,get 请求到达服务端,服务端会先给客户端发送一个open包的推送信息。服务端发送包是通过写到消息队列里面,这里会打印发送信息日志,消息队列的数据通过长轮训的方式给到客户端,查了下长轮训不能完成保证这里的消息包送达客户端。接着服务端会有一个异步等待前端 ping 包的任务,当收到这个包后才会真正切换协议,并打印升级成websocket协议成功日志。
之后服务端在日志补充后也证明了 packet.OPEN 确实没发给客户端。
既然服务端发包失败,那么此刻我们的关注点自然要聚焦到连接更上方的部分,比如 websocket 初始化建立时是否就出现了问题,之后服务端留意到初始化建立连接时,失败的日志中请求nginx返回 400 连接失败,而正常情况下,如果 websocket 建立成功服务端应该返回 101 状态码,那说明可能在最初的握手就出现了问题。
很巧的是我想起来我在 socket.io 的 issues 列表中有看到过因为 nginx 配置问题导致的 websocket 连接 400 的问题,于是服务端同学去确认了配置,最终结论也是确定没问题,毕竟配置同一份代码也基本没人会改动。
大家都知道请求 400 还可能跟请求参数,请求头请求体不匹配有关系,于是服务端同学又仔细对比了成功和失败情况下的请求头,最终发现连接失败下的请求头部分信息丢失了,但需要说明的是这绝对不是我们业务本身的行为,而是跟用户的环境或者防火墙有关系,其实排查到这里原因就定位出来了,但是我们很难干预,最后我们决定考虑降级 http 长轮训来缓解此问题。
肆 ❀ 叁 如何解决?降级策略还是升级策略
我在排查此问题之前,其实就已经知道 socket.io 支持降级策略,比如 websocket 连接失败无法使用,那就降级到 http 长轮训来保证业务,而且这个库本身就支持这一点。有同学可能就会想,排查这么久还是走降级,那为啥不一开始直接上降级呢?其实有几个原因在里面:
- 如果要做长连接且双向通信,websocket 相对长轮训有着极大的优势,我们肯定希望排查出问题并解决问题且继续采用最优解。
- Websocket 的通信压力相对于长轮训要小很多,在用户量较大的情况下冒然降级可能对服务器造成过大压力。
- 在排查问题之前我们并不知道根本原因是什么,也许就是单纯用法的不对呢?这种情况下降级不一定能处理,反而有种无头苍蝇的感觉。(结合上面说的服务器压力)。
所以最终采用长轮训兜底是我们确定了原因之后的一种兜底手段,不然客户防火墙之类的干预 websoket 链接,我们毫无办法。且在之后我们也专门做了长训练的压测,考虑到目前并不是非常大的用户量会遇到此问题,即便他们全部长轮训,目前服务器也顶得住,所以我们决定采用长轮训兜底。
那么问题来了,我们做降级策略怎么做?websocket 连接超时一次默认是20S,我们 retry 几次后降呢?如果设置 5 次,也就是说用户接近要等待 100s 才能触发降级策略,那假设这个过程中用户刷新了页面,那就又要重走 retry,导致用户永远都进入不到降级了。
改连接等待时间?20S 是 socket.io 默认值肯定是有原因的,考虑到用户网络不好的情况,假设你设置的太短,本来能用 websocket 的全因为这个原因走到了 http 长轮训,那服务器不是被迫抗压。
其实考虑下来,我们走的其实不是 socket 的降级,而是默认的升级策略,socket 官网有这样一段描述(官网也提到了 websocket 虽然好用,但是防火墙,杀毒软件都会造成连不上....):

如果采用默认策略(升级策略),socket 会默认先试用http长轮询保证业务,之后就会立刻尝试升级 websocket ,如果升级成功就立马暂停终止长轮训并切换到 websocket,否则继续使用长轮训保证正常连接,这样用户确实无感升级过程,而业务也始终是可用的了。
下图是走升级策略后的日志,可以很清楚的看到从长轮训到 websocket 的升级过程。
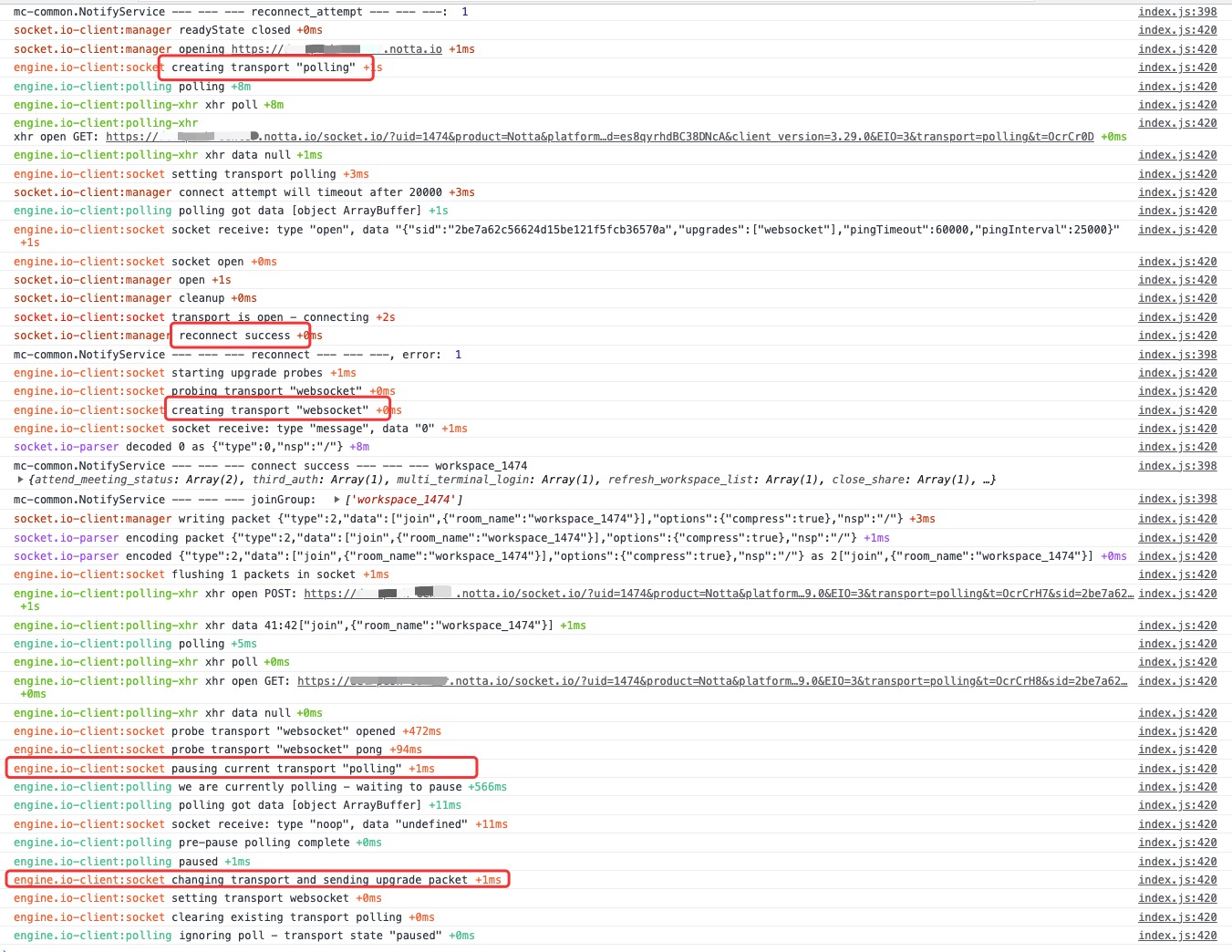
至于为什么业务底层封装写死了 socket 只能用 websocket 模式进行连接,历史原因也没办法追溯了。
在经历了压测以及灰度测试后,我们通过日志观察也证明了之前 sentry 记录无法使用业务的用户现在业务均正常,在之后上生产后,sentry 的上报统计工作日数量对比已经直线下降了,而 sentry 还存在的上报我们也挑了数十位用户去查了对应日志,发现均正常使用,这些上报更多是尝试升级 websocket 失败的上报。(以前用不了 websocket 的现在还是用不了,但起码业务能跑了)
那么到这里,此问题完美解决,其实整个排查下来,我确实依旧不知道 socket 咋用,我也不知道它封装到底做了什么,甚至连官网文档我也只是粗略看了几眼,然后发现了上面升级策略的说明。
但整个排查思路,大家应该能感受到是非常清晰的,不断利用线上来提出猜想,定义下一步计划并验证,非常顺利一步步接近真相,这就是我想表达利用现象来发现问题,如果知道问题是什么,自然知道下一步动作是什么,难的是发现问题,要学会分析现象。
伍 ❀ 总
简单做个总结吧,其实本次分享的前半部分我一直在说 DMAIC,它更倾向于在定义问题之后,如何一步步系统化的解决长期问题。但是我说了,大多数情况下难在问题是什么,问题如何定义。所以分享后半段我提到的利用现象找问题,以及举的各种例子,都是在阐述区分现象和问题的同时,利用现象来驱动自己跟踪问题,而不是看着“问题”非常迷茫,不知道下一步是什么,所以到这里不知道大家心里有没有一点对于方法论的感悟了呢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号