
react 快速接入 sentry,性能监控与错误上报踩坑日记

壹 ❀ 引
本文是我入职第一个月所写,在主导基建组的这段时间也难免会与错误监控和性能监控打交道,因为公司主要考虑接入sentry,所以对于接入sentry的基建任务也提了一些需求,主要分为:
- 支持查看项目
Web Vitals指标 - 支持接口错误自定义上报
- 支持接口耗时信息上报统计
- 支持首屏加载耗时监控
其实这几个小需求接入的过程中又给我衍生了新的问题,比如:
- 接口错误上报存在很多高频且没意义的错误,比如账号密码错误之类的需要过滤
- 首屏加载时间我应该怎么计算?标准怎么定?
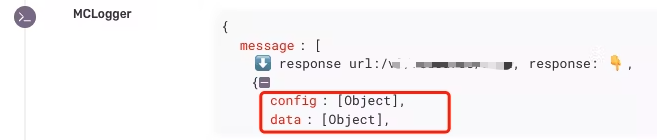
- 面包屑能展示调用栈信息,但很多上报的对象显示为
[Object],无法展开易读性太差需要解决。
但是不得不说,目前网上能搜到关于sentry的文章真的太少,而且大部分文章都只是一个最基本的sentry初始化,看官网10分钟就能搞定的程度,所以遇到很多问题基本找不到答案。过程中也是各种给sentry官方写邮件问问题,时差关系一天只能回复一次....在通过一段时间的研究,也顺利完成了任务卡中所定的几个小目标,因为确实有踩坑,所以很有必要写一篇文章记录。
另外,本文标题虽然带react,但其实本文的思想和框架非强绑定关系,全文非常通用,这点大家不需要担心,让我们直接开始。
贰 ❀ 必须了解的前置概念
如果要用sentry做性能监控,如下几个概念是你必须知道,所以我们先提前说说。
贰 ❀ 壹 sentry中的事务(Transaction)与维度(span)
其实一开始我就想过一个问题,sentry可以做性能监控,那么它监控的维度是怎么样的,性能信息是怎么上报上去的,难道一个接口上报一次?在后续深入了解以及跟官方沟通后可以确定,sentry以每个页面(路由)加载为单位,然后搜集这个页面加载过程中的接口请求,资源下载等等数据,之后统一跟随这个页面一起上报。
简单来理解,每个页面每次加载时sentry都会以这个页面为名创建一个事务Transaction(一个装信息的盒子),在加载过程中,sentry会搜集接口请求、pageload、静态资源下载等等数据,然后装在这个事务一起上报:
关于Transaction事务可以进入sentry点击后台的performance,可以看到下方有一个以路由页为单位统计的Transaction事务表格:

上图我展示了登录和注册两个事务,在最后还能看到被筛选条件下被访问了多少次。
而假设我们点击登录事务进入详情,可以看到有一个叫spans的tab页,点击过去,你就能看到前面被访问几十次的登录页所有spans的信息,比如http.client用于查看所有接口调用的次数,以及耗时情况,resource.img用于看图片资源下载情况等等。
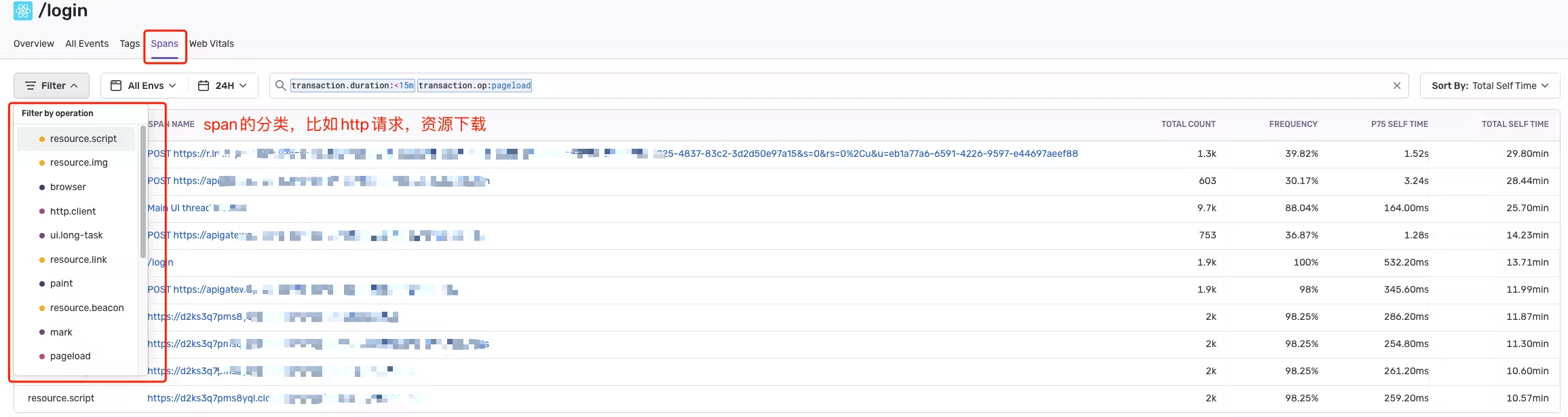
这里我们解释了事务与维度的关系,sentry以页面为单位搜集单个页面的不同维度数据,所以你只能以页面为单位看不同页面的性能情况,假设我现在希望看到整个项目所有页面的某个维度(比如某个接口)信息,这对于sentry来说是办不到的,它并没提供整合整个项目所有页面所有维度的功能,这个要提前先说清楚。
当然sentry提供了自定义事务的能力,就是你可以自己创建属于自己的事务,然后来塞一些你想上报的维度,这个后面我们再说。
贰 ❀ 贰 关于前端性能指标Web Vitals
Web Vitals是google提出的一种用于检测网站使用体验是否良好的指标,主要分为如下三种:
- LCP:Largest Contentful Paint 顾名思义最大内容绘制,这个只算首屏,比如你页面滚动又加载了新的内容不会统计进去。
- FID:First Input Delay 首次输入延迟,比如页面加载完成了用户点击按钮到响应的延迟耗时。
- CLS:Cumulative Layout Shift 累积布局偏移,比如页面加载过程中图片位移被挤到一边,页面布局发生偏移。

关于优秀,良好以及较差的评判标准为:
| 优秀 | 良好 | 差劲 | 百分比 | |
|---|---|---|---|---|
| 最大内容绘制 | <=2500ms | (2500ms~4000ms] | >4000ms | 75 |
| 首次输入延迟 | <=100ms | (100ms~300ms] | >300ms | 75 |
| 累积布局偏移 | <=0.1 | (0.1~0.25] | >0.25 | 75 |
在做性能监控时我们常常会看到P95、P75的数值,上面表格对于性能指标采用的就是P75,啥意思呢?这里的 P 并不是 percent ,而是百分位数;百分位数是统计学术语,若将一组数据从小到大排序,并计算相应的累计百分点,则某百分点所对应数据的值,就称为这百分点的百分位数,所以 P75 可以理解成100份数据我们从小到大排序后,取第75位作为最终值,以此排除极端取值情况且保证值合理的一种做法。有同学就要说呢,那假设是120份数据呢,这种情况下取值就是在排序后取第(120*0.75)位作为有效值。
关于Web Vitals如果大家想了解更多信息,推荐大家看定义核心 Web 指标阈值一文,官方中文,介绍的非常详细。
那么回到sentry当我们点击performance就能看到Web Vitals的tab页面,除此之外还有前后端以及移动端的tab页:
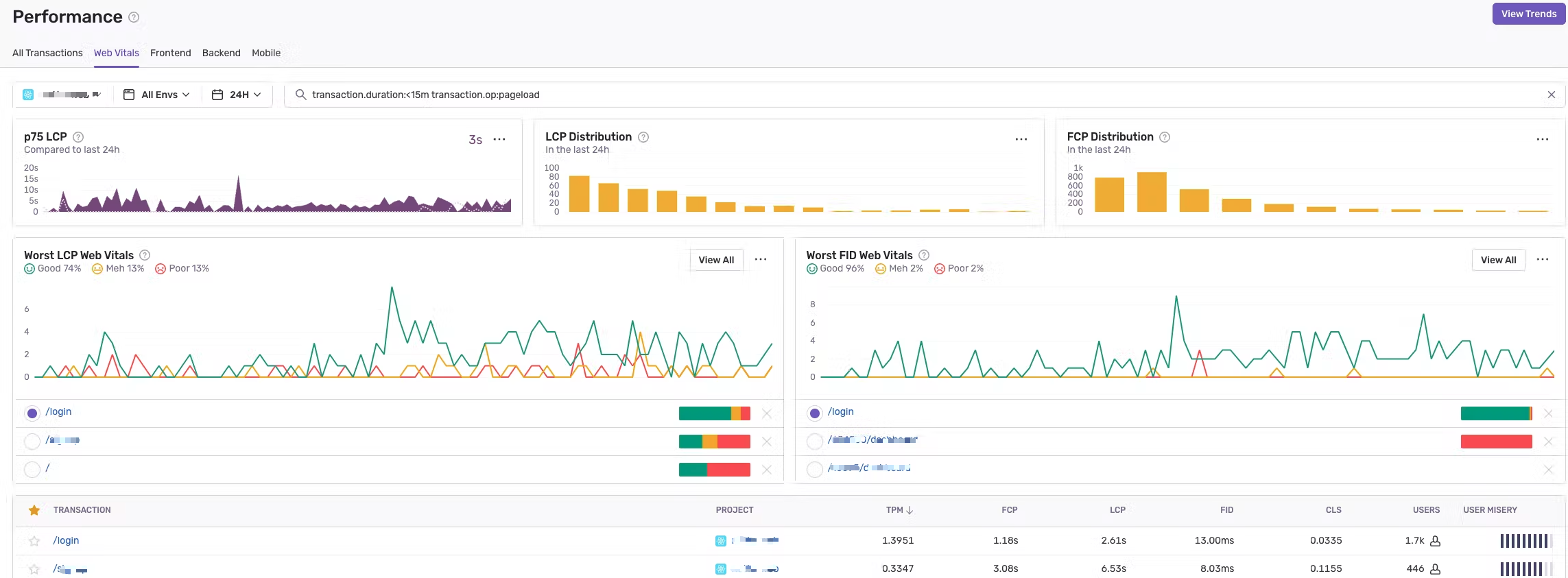
如上图我圈出来的地方,你可以选前后端,在下面圈出来的是我们在前面提到的事务表格,表格后面就有Web Vitals的三个指标。
当然,既然Web Vitals是google提出的,那么chrome肯定自带查看不同页面的指标,我们打开控制台,输入命令ctl/command + shift + p,之后输入show web就能看到这个选项:
之后你刷新当前页面,然后交互,就能看到对应的相关数据了:

这里我展示的是京东首页,可以看到京东的几个指标还是挺不错的,另外,这个指标窗口必须打开控制台才能展示,假设你关闭了控制台就会默认关闭,后面我还对比了一下它和sentry上报所抓的数据,本质上是差不多的,毕竟sentry的数据也是来自浏览器。
叁 ❀ sentry初始化配置说明
关于初始化的npm相关操作这里就不介绍了,这里主要解释几个比较重要的配置含义:
Sentry.init({
enabled: boolean,
dsn: '',
environment: '',
allowUrls: [''],
integrations: [
new SentryTracing.BrowserTracing({
routingInstrumentation: Sentry.reactRouterV5Instrumentation(history),
}),
],
normalizeDepth: 10,
sampleRate: 0~1,
tracesSampleRate: 0~1,
});
-
enabled:决定错误以及性能相关信息是否要上报到
sentry,比如我只希望生产环境上报,这里你就能写一个表达式。 -
dsn:上报到
sentry的关键凭证,比如你在sentry后台创建了多个项目,那么每个项目都会提供给你一个独一无二的dns,有它sentry才知道上报的信息属于哪个项目。 -
environment:上报信息时告诉
sentry这些信息属于哪个环境,测试还是开发或者生产。之后你就能在sentry后台切换环境查看对应环境的数据。 -
allowUrls:一个包含地址字符串的数组,告诉
sentry哪些地址页面能被上报,上面的enabled权限比这个要大,比如你配置了只上报生产环境,那么你在这个数组加入['localhost']也不会对开发环境生效。 -
normalizeDepth:我们在上报错误时,有时候需要查看面包屑中调用栈情况,但是有些对象层级比较深,当层级超过三层
sentry默认展示[Object],这就导致你没法查看完整的对象信息,所以我们通过这个配置sentry能识别对象的深度,非常有用。
-
sampleRate:决定
sentry错误抓取的百分比,范围时0~1,比如今天项目报了100个错误,你配置的0.5,那么sentry随机给你上报50个。 -
tracesSampleRate:决定事务上报的百分比,前文说了
sentry时以页面加载为单位来搜集页面性能数据,那么这个配置决定sentry上报多少。
肆 ❀ 如何查看性能指标
肆 ❀ 壹 通过sentry查看Web Vitals
上文我们提到了通过google查看Web Vitals指标,如果我们想在sentry查看所有页面数据情况,就可以通过前文提供的事务表格直接看到每个页面的相关数据;假设我们想查看某个页面具体的性能指标数据,可以通过事务表格点击某个具体页面,之后就能看到这个详情页面:
在这你甚至能看到FP、FCP相关数据分布,这样你就知道这个页面某条指标优秀,中等的占比情况,你还能通过View All Events看到不同用户访问这个页面的情况,具体大家自己研究。
肆 ❀ 贰 整体感知性能糟糕的页面或接口
当然,假设我想知道最近半个月整个项目哪些页面的性能比较糟糕,你可以进入performance首页,之后点击Web Vitals,之后你就能看到各种图标,比如:
在这你能看到sentry帮你统计的最糟糕FID或者LCP指标的页面,你可以通过...切换其它图标,同时你能点击sentry统计的具体页面,来看看到底是哪些span导致你这个页面这么糟糕。
文章开头说了,需求其实希望能统计所有接口的耗时情况,但是很遗憾sentry只提供了一个Slow HTTP Ops的图表,我在与官方沟通后确认了两件事:
Slow HTTP Ops认为某些页面接口慢的标准并不是一个准确的值,而是统计某段时间接口的响应情况,然后给出它觉得接口慢的页面。sentry只能通过此图表看到它认为慢的接口,你不能看到所有接口耗时情况,如果真的想看,你只能通过事务分别查看每个页面中关于http请求span的数据分部情况。
伍 ❀ 自定义错误上报
其实配置好sentry后,sentry会自动抓取项目使用过程中的所有错误,但有个问题,我们在请求接口时接口虽然200,但是后端会返回我们约定好的一些错误码,这对于sentry是无法感知的,所以需要我们自定义上报。
我先假定大家理解请求拦截的概念,所以不管什么接口,我们都可以在拦截的response做统一处理,只要后端返回的约定状态码不是成功,我们就可以通过如下代码上报错误:
Sentry.captureMessage(title,{
extra:{}// 附带的数据
level:'warning' // 错误等级,警告还是报错由你决定
})
- title:错误上报后展示的标题
- extra:附带数据,比如你想把后端返回的完整数据带上去
- level:错误等级,你可以定义为警告或者错误
但这个上报其实有一些缺陷,比如用户在使用过程中账号密码错误,无权限之类的错误,这对于我们其实是无意义的,因为这就是合理的错误,所以你可能还需要提前去搜集一些你希望过滤的错误码,然后判断是否要上报。
陆 ❀ 自定义事务上报
前文已经说了,sentry以页面加载为一个事务来上报整个页面的性能数据,那么问题来了,我想统计整个项目所有接口的耗时情况,现有sentry体系很明显做不到,因为不同接口都被分散到了不同页面,因此我们想上报接口信息就必须得依赖自定义事务上报,说简单一点,就是我们为所有接口都创建同名的事务,这样就能把它们归纳在一起,而不同接口其实都是不同的span,我们通过描述来区分它们就好了。
同理,还是假定大家有请求拦截的概念,我们可以在请求拦截前添加如下代码:
// 我们可以在请求前创建一个事务,以及一个span
const transaction = Sentry.startTransaction({ name: "httpRequest" });
// 将创建的事务附带到当前 sentry 上下文
Sentry.getCurrentHub().configureScope(scope => scope.setSpan(transaction));
// 创建一个 span 并塞到事务里,这里的 op 和 description 你可以都用接口名来做区分
const span = transaction.startChild({
data: {
// 你想附带的数据
},
op: '', // 操作名
description: '', // 描述
});
之后在请求结束后,添加如下代码:
// 提交 span
span.finish();
// 提交事务
transaction.finish();
就这么简单,可能有同学就要说了,这不对啊,你不是要上报所有接口耗时吗?也没看到你计算时间啊。其实上述代码之所以要分别放在请求前和请求响应之后,是因为这个时间差本身就是接口的请求时间,而当我们调用span.finish()时sentry会自动计算从创建这个span到完成的时间差,所以这个时间并不需要我们手动计算,sentry会帮我们搞定。
之后我们只用来到performance页面,找到事务表格,点击名为httpRequest的事务,就能在里面看到所有span的数据情况了,而这些span其实就是不同的接口。
柒 ❀ 如何计算首屏时间
最后,让我们来讨论如何计算首屏时间,首先说在前面,目前业界就没有首屏时间计算的标准,我查了下常见的几种计算规则:
- 使用
loadEventEnd - fetchStart/startTime粗略计算。 - 自定义打点,业务不同标准不同,比如我觉得首页某个组件加载完成就算加载完了,那你可以认定这个组件渲染完成耗时就是你的首屏时间。
- 计算首屏内所有图片加载耗时,取最大耗时。
- 利用 MutationObserver 接口,监听 document 对象的节点变化。
首先第一种方式肯定不行,因为这个东西本质上计算的就是原生dom渲染的耗时,简单理解就是onload执行时之前的耗时,而像react组件渲染比原生dom要晚,它没办法感知。
第三种方式大致理解为计算视窗内所有图片加载耗时,因为图片地址填充本质上是异步的,它需要先下载资源然后再填充,所以取最大的图片就是最后的渲染时间,但需要考虑用户可能会滚动窗口然后加载了更多的图片,而我们项目首屏并没有什么图片,可实施性不高。
关于最后一种统计方式,目前公司之前使用的监控平台就是这种计算规则,相对有点复杂,但是算出来的时间一般会比我们直观感觉要久。
最终还是决定采用了第二种,这种其实也有缺点,就是埋点会侵入业务,你得加入到组件里,那么具体怎么算呢?这里我详细解释下。
首先,像react组件本质上也是挂载在原生dom上的,所以一定是先渲染原生dom,之后接口请求拿回数据,再回填重新渲染react组件,因此这里一定有两个过程,原生dom渲染过程以及react组件渲染过程。
因此,我们希望的首屏耗时 = 原生dom渲染耗时 + react组件渲染耗时。
那么,我们怎么知道原生dom渲染完成耗时是多少呢?其次,既然要计算react组件渲染耗时,我们肯定得有一个起始时间,然后再用didMout执行时的终点时间减去这个起始时间,才能求出组件渲染要了多久,这个起始时间怎么来?
先说原生dom渲染耗时,也就是所谓的onload执行时之前的耗时,上文已经给出了,其实就是loadEventEnd - fetchStart/startTime,而关于这几个时间指标我们能通过如下代码拿到:
window.performance.getEntriesByType('navigation')[0]

可能你在某些文章看到performance.timing,很遗憾timing字段已经被废弃了,所以不推荐使用。
而前面提到的用于计算组件渲染耗时的起始时间,我们可以在onload事件执行时const T1 = Date.now()得到组件渲染之前的时间。需要注意的是onload放在组件生命周期中不会执行,因为组件渲染时onload早就结束了,你应该把这个监听放到App组件渲染之前,也就是你App文件的最上层。
之后我们在首屏标志性组件的didMout/useEffect中再次const T2 = Date.now(),就能得到组件渲染完成的终点时间了,了解组件生命周期的同学都知道,组件渲染过程是从父到子,而didMout过程是从子到父,一定是这个父组件的所有组件挂载完成父的didMout才能执行,所以这个思路没什么问题。
我们总结一下这个过程:
- 使用
loadEventEnd - fetchStart/startTime计算onload执行之前的耗时T0 - 在
onload中创建起始时间T1。 - 在首屏组件
didMout中创建终点时间T2。 首屏耗时 = (T2 - T1) + T0
用图来理解这个过程就是:

然而当我正准备这么做时,有趣的事情发生了,看下图:
经过多次测试,这种算法得出的首屏耗时和LCP的误差非常非常小,可以毫不夸张的话,如果采用这种方式,我们完全可以使用LCP耗时来代替即可,而LCP耗时sentry默认就帮我们拿了,在与前同事沟通后确认LCP作为首屏耗时并没有太大问题,因此最终我们还是决定使用LCP作为首屏耗时。折腾了半天,用这种方式论证LCP可作为首屏时间也挺有意义。
捌 ❀ 总
那么到这里,我们从sentry作为出发点,介绍了sentry如何查看前端性能指标,而站在使用角度,我们也简单提及了自定义上报错误以及事务,而关于首屏时间计算我也给出了一个参考性建议,大家若有好的看法也欢迎讨论,那么到这里本文结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号