
前端开发面试快速复盘,不标准的面试经验分享(三),逃离湖泊投身大海的鱼

壹 ❀ 引
大致上来说,这是我认真找工作的第二周了,比较遗憾,到目前为止我仍为找到满意的工作。倘若你问我找工作难不难,单站在找到工作的角度其实并不难,但如果在找到的基础上增加一些条件就比较难了。就像两个年轻人准备谈恋爱,首先得互相看对眼才有初步机会,若一方要求较高那么在一起的概率就会降低。在本周我从面试邀请中挑了三家看似不错公司并参加了面试,大致都是有成熟上线项目的技术自研型公司。本篇文章中的问题可能与之前的面试复盘存在一定差异,文章较长但我还是希望你能耐心读完,并假想当时被问到的是自己又该如何作答,这对于日后大家挑战高级开发岗位多多少少会有帮助(虽然我自己都还没成功),那么本文开始。
贰 ❀ 阿里某合作商
这是一家为阿里巴巴提供云计算服务的公司,技术算很硬了,要求也很高。我在周二晚上接的电话一面,后来才知道电话对面是他们公司的技术总监,谈话内容主要围绕JS基础问题,大致如下(注意,下文中面试自我介绍我都省略了):
面:你在上家公司扮演了什么角色?主要负责了哪些工作?
角色方面如实作答就好了,负责工作可围绕在职期间自己工作出色点,或者其它能体现自己能力的方面作答,不要仅限于写代码。比如我在项目重构方面出力较多,也负责了项目组件库的开发,因为个人JS基础知识储备还行,所以也有带见习开发的工作,所以我就围绕这三个方面说了,大家可以构思总结下自己的工作出色点。
面:能说下深拷贝吗?
深拷贝是针对引用数据出现的问题,引用我们将一个对象A赋予对象B时,对象B保存的其实是A对象值存放地址的引用,所以如论修改A还是B,都会影响另一方。而深拷贝就是要达到复制对象后,修改任意一方都不会影响另一方。
面:那你能不能实现一个深拷贝?说下实现时需要考虑的边界问题
单说实现,乞丐版可以依赖JSON的parse与stringify做到,当然面试官肯定不会满足于此,一定会追问你如果自己实现怎么办,所以后面我就聊了下自己如何实现一个简单的深拷贝(只针对对象{}和数组),以及实现需要考虑的边界问题。
先说边界问题,假设我们要实现一个深拷贝函数deepCopy,因为前面说了深拷贝是针对引用数据来说的,第一点,传进来的参数一定是得检验数据数据类型,若是基础类型就没拷贝的必要了。第二点,对象的属性值也可能是一个对象,因此在复制时还得对值进行判断,若仍然是对象,我们得递归。第三点,我们拷贝对象自然是希望拷贝对象自身属性,而对于非自身的继承属性我们得过滤掉,那么我们来实现一个简单的深拷贝:
// 只针对{}与数组的简单实现
function deepCopy(source) {
function isObject(o) {
// 此实现只针对数组与{},由于null的typeof类型也是object,特做过滤
return typeof o === 'object' && o !== null;
};
// 如果参数不是对象{}或数组直接返回
if (!isObject(source)) {
return source;
};
// 创建一个新对象,是数组就创建空数组,反之空对象
let target = Array.isArray(source) ? [] : {};
// 遍历源对象,进行拷贝
for (key in source) {
// 判断当前属性是否是自身属性
if (source.hasOwnProperty(key)) {
// 判断当前属性的值是否仍然是对象
if (isObject(source[key])) {
target[key] = deepCopy(source[key])
} else {
target[key] = source[key];
};
};
};
return target;
};
面:ES6了解吗?说下你熟悉的特性,说三条就好。
这个比较简单,我首先说了下let const,关联性的介绍了块级作用域,暂时性死域,const值是引用对象时不能修改的是引用地址,之后聊了下箭头函数与this,之后说了promise,三个状态,all与race的区别之类的,大家挑自己熟悉的去说,能扯的详细更好。
面:做过哪些优化工作?
这个说起来的方面就多了,比如文件下载方法的优化,对于每个页面尽可能做到按需加载,减少非必要文件的下载,还可以使用http缓存,文件MD5戳减少文件下载频率,结合发布工具压缩合并文件等;代码层面的优化,比如组件封装,常用API封装,减少代码量提升代码复用性;使用友好方面优化,比如图片懒加载,onloading管理,节流防抖等等。
一面大致问了这些问题,面试官对于我的回答还算满意,初面给我的评价是知识体系很系统化,思考问题也很全面,所以周四下午约了现场复试,复试两个面试官排队问,那么下面是复试相关问题:
面:看你项目重构做的比较多,说下重构做了哪些工作
对于这个问题我开始详细说了下项目结构调整,因为我当时重构并不是在原有基础上改写代码,而是对整个项目进行了从零开始的重写,包括项目结构调整,由最初一个总应用APP文件管理了所有页面的service,组件相关注册,改为APP文件只负责注册,单页面分别管理自身所需依赖文件。

这么做的的目的主要还是按需加载,A页面用到什么便注册什么,页面渲染时可以减少不必要的文件下载。其余文件更便于管理,哪个service为谁服务一路了然。
之后介绍了组件封装之类的相关重构工作,以及发布工具配置等相关的。
面:能说下你组件封装的思路吗?
第一步确认需求,在了解需求的情况下绘制流程图,再以流程图与上级确认需求是否符合,可行的话之后就是看着图写代码的事情了。
面:那你怎么保证组件重构封装后还能满足之前的业务需求,举个例子,假设之前组件是满足ABC三种情况的,但因为需求文档疏忽,或者你自己流程图的疏忽忽略了B,你该怎么弥补这个问题?
老实说,我一是没遇到过这种问题,二是实在没get到他具体想问的点在哪....后面回答也不是很好,所以直接征求面试官合理的做法了。面试官说这个问题解决方案很多,比如可以在组件实现后可进行单元测试,这样就能提前知道B不符合情况了,之后修改组件逻辑的同时完善需求文档。我听完人都傻了...我一直以为他想问的是组件设计方面的问题,比如如何保证组件拓展性,所以当时回答的很失败了。
面:你在组件里有提到loading的实现,如果一个请求很快就结束了,你怎么处理的?
因为我的loading在请求拦截处统一管理,request阶段启动,response阶段关闭,由于请求都是同步,异步是响应阶段,一个页面总是会存在多个请求的情况,所以开启loading只会有一次,且开启loading是由定时器管理,比如2S后才会启用loading,如果一个网络请求非常快,则会将启动loading的定时器清除。而针对多个请求,会用数组装在每个请求信息,完成一个请求对应清除数组中该请求信息,数组被清空时自然说明请求全部完成,则关闭loading。
面:你说在请求拦截中做了部分网络错误处理,那如果一个请求超时了怎么办?
针对于请求超时,可以通过retry来实现自动发起再次请求。随后面试官又问retry需要注意什么,这里我就说了retry需要设置最大retry次数,避免无限请求,其次retry之间也需要设置间隔时间。
面:那你是对整个项目所有请求都retry了吗,如果有些请求我不想retry怎么办?
这里我实际的做法是在项目配置文件中,专门有一个数组装了需要retry的接口信息,如果一个接口没被包含,就不会执行retry,类似于多了一次条件判断。
面:你前面说retry是根据code 504来做的,如果有些请求,后台没返回,也就是没有respone,你怎么做后续处理?
这个我当时答的也不是很好,其实不管后台有没有返回,前端都是可以拿到反馈信息的,哪怕我们请求一个不存在的接口,也会得到接口404的错误反馈,所以针对反馈的错误信息去做处理,给出提示或者其它。
面:能说下你做的多货币功能吗?
这个我就大致介绍了多货币指令的实现,当货币在美元与人民币之间切换时,会触发指令逻辑,根据后台提前返回的汇率进行计算,其实我说到这我就猜到会问精度问题了,但是这块我之前没详细了解过。
面:那你前端是如何保证计算后的精度的?比如我们都知道0.1+0.2!=0.3,你说下为什么,如何在计算中解决。
这个我回答的也不是很好,关于0.1+0.2这个问题之前有看,但是时间太久记忆模糊了,只记得是精度丢失,所以没能很系统的去解释。
准确来说js中的数字都采用了IEEE 754标准的64位双精度浮点数,而对于64位的浮点数在内存中表示时分为了三部分,第0位符号位(占1位,用s表示),表示这个数字是正数还是负数,0为正,1表示负数。第1到11位为指数部分(占11位,用e表示),表示这个数值的大小,第12到63位为尾数部分(占52位,用m表示),决定数值的精度,大致如图:
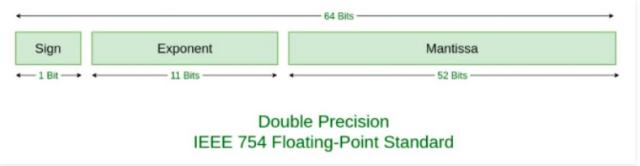
我们知道计算机中数字都是按二进制进行存储的,所以第一步得将十进制数值转为二进制,需要说明的是十进制整数转二进制方法为除2取余,按倒序排列,而十进制小数转二进制方法为乘2取整,按顺序排列啥意思?我们现在就以0.1为例,0.1整数部分为0,0/2余0,所以先得到一个0.。我们再看小数部分,如下:
0.1 * 2 = 0.2 //取整数0,第一位,0.2参与下次计算
0.2 * 2 = 0.4 //取整数0,第二位,0.4参与下次计算,
0.4 * 2 = 0.8 //取整数0,第三位,0.8参与下次计算
0.8 * 2 = 1.6 //取整数1,第四位,0.6参与下次计算 标记1
0.6 * 2 = 1.2 //取整数1,第五位,0.2参与下次计算
0.2 * 2 = 0.4 //取整数0,第六位,0.4参与下次计算
0.4 * 2 = 0.8 //取整数0,第七位,0.8参与下次计算
0.8 * 2 = 1.6 //取整数1,第八位,0.6参与下次计算 标记2
0.6 * 2 = 1.2 //取整数1,第九位,0.2参与下次计算
请观察上述计算,在标记1到标记2的位置,再往后其实已经进入了一个循环了,由于计算永远得不到小数部分为0的情况,所以其实进入了一个无限的计算循环,结合前面得到0.,组合而成就是0.0 0011 0011 0011...(0011循环)。
计算机中内存是有限的,所以并不可能去存储一个无限长的数值,因此计算机在某个精度点自然就舍弃了后面的数字,这个精度点自然就是我们前面说的52位尾数了。所以二进制转换完成,是还会再按IEEE 754标准再转一次,转换公式就不说了,直接给结果:
// 0.1
e = -4;
m = 1.1001100110011001100110011001100110011001100110011010 (52位)
而0.2转换同样会存在这样的问题,所以两个都丢失了精度的数值计算后还原成十进制,自然得到的不是0.3。具体推算可以阅读这篇文章详解js中0.1+0.2!=0.3。
当然不是所有浮点数都有误差,二进制其实能精确地表示位数有限且分母是2的倍数的小数,比如0.5在计算机内部就没有舍入误差,所以0.5 + 0.5 === 1。
那么我们怎么比较0.1+0.2===0.3呢?这里其实可以借用ES6中Number的新属性EPSILON,它表示 1 与Number可表示的大于 1 的最小的浮点数之间的差值,所以正确的比较方式为:
Math.abs(0.1 + 0.2 - 0.3) <= Number.EPSILON;// true
当然,关于金额数值的计算,一般都是交给后端计算,如果前端算了其实后端也要算一次做核对,所以总体来说后端一定要算。主要原因是一方面是前端计算存在浮点数问题,处理起来存在一定成本,二是前端可能存在改单情况,存在一定金额计算风险。
当然前端如果说真要算怎么办,这里可以借用成熟的类库来解决,比如math.js。
面:能说下多语言怎么做的吗?
多语言用了angularjs的ng-translate指令,考虑大家都没用过,这里就不细说了。
面:能说下你这个sentry是做什么的吗?
sentry是一个前端错误监控系统,这里我主要是基于sentry搭建了一个前端异常监控服务,用于抓取前端http请求异常,目的是在用户使用过程中出现请求错误时,通过对原错误信息进行加工,提取用户信息,出错页面,请求地址,参数,响应数据等相关信息并上传日志,开发者可通过邮件快速定位错误,达到远程排错的目的。
面:你觉得你工作中遇到最有难度或者最有挑战性的事情是什么?比如花了很久时间解决的事。
其实我在面试前就想到如果被人问到这个问题怎么办,但是我觉得自己项目真的亮点不足,涉及技术点不深,结果这次真遇到了,然后我直说了没有- -,因为项目太简单了(在后续聊天中我找到了下次可以回答的答案)。
面:XMLHttpRequest对象了解吗?
我们熟知的ajax在不刷新页面情况下,异步更新页面部分数据,其实底层依赖的就是XMLHttpRequest对象,所以我围绕ajax使用,大致说了创建xml对象=>利用open设置请求方式与请求地址以及是否异步=>利用send发送请求=>设置监听函数onreadystatechange函数=>处理响应数据五个过程,介绍了readyState不同状态的具体含义。
面:fetch了解吗?跟ajax有什么区别?
说来惭愧,这真是我第一次听到fetch,所以面试官也很诧异,说这么常用的东西你都不知道....仔细回想这三年,第一年用JQ,后两年用angularjs内置的http请求,周围也没有一个人给我提起过这个词,那么这里简单整理下。
首先fetch是原生js的实现方案,与ajax并无关系,你可以把它当成XMLHttpRequest的一种更理想的替代方案,fetch语法如下:
fetch(input[, init])
其中input可以是获取资源的地址,或者是一个request对象。而init则是一个包含所有请求设置的对象,比如请求方法,headers请求头信息以及可以使用mode:cors达到跨域效果等等,来看个简单的例子:
fetch('http://example.com/movies.json')
.then(function (response) {
return response.json();
})
.then(function (myJson) {
console.log(myJson);
});
fetch不管请求成功失败,都会返回一个promise,我们可以使用then方法处理回调。
与ajax对比,fetch主要有三点不同:
- 当接收一个表示错误的
http状态码时,fetch的promise不会被标记为rejecte,反而是resolve(但是会将resolve的ok属性设为false),只有网络故障,请求被阻止这种情况才会被标记reject。 fetch可以接受跨域cookies,你也可以使用fetch创建跨域请求。fetch默认不会发送cookies,除非我们通过前面的init对象修改了初始化配置。
更多fetch还是推荐大家阅读MDN使用 Fetch词条。
面:如果让你对比angularjs和vue,你觉得angularjs优势在哪?
这个问题就挺头大了,人人都知道angularjs由于脏检测机制等历史遗留问题,官方都放弃了此版本的更新而新开了angular版本,而vue在设计初期借鉴了angularjs一些思想,整体上来说vue是更具优势的,所以想来想去我回答的是angularjs优势体现在组件化,mvc思想先驱的角色扮演。
面:那vue相对angularjs你觉得有哪些优势呢?
这个就好解释一点了,其实对于我的开发体验来说,最大的感触还是angularjs的脏检测性能问题,angularjs脏检测原理其实是由digest方法触发,默认从顶层作用域开始深度遍历,依次访问每个作用域中的watcher数组中的每个数据,一一对比是否发生变化,所以如果作用域嵌套多,监听数据多,每次更新开销都是巨大的,但相对这一点,vue使用基于依赖追踪的观察系统,若一条数据变化只会更新本数据,成本会小很多。其次针对组件通信,angularjs官方并未友好提供兄弟通信的方式,但是在vue中借用vuex等会便捷很多。
面:有了解过设计模式吗?
面:有推进公司项目,或者技术研究吗?
面:最近做过哪些技术分享?
这几个问题就统一说下了,设计模式我之前有读过JavaScript设计模式相关数据,不过实践能力较弱,并没到融会贯通的地步,推进项目我说的是没有,小喽喽一个,技术分享自然是博客了,说了最近就是写一些面试复盘总结。
大致到这里就算面试结束了,两个面试官说要讨论下结果,顺便看下我的博客。大约等了10来分钟,得到的反馈是项目无亮点,软件思维薄弱,目前公司只有三个岗位,1个高级2个初级,并没有适合我的位置。
其实我面完感受也不是很好,我深知自己项目难度不高,没太多亮点,面对深挖项目的面试我真的毫无优势,所以结果也算预料之内了,所以我急忙就问了面试官前面我回答的不是很好的问题,面试官笑着说还想着讨点面经啊,然后就又跟我闲聊了十来分钟。
我:我深知自己项目无亮点,难度并不高,所以被问到你觉得工作你做过觉得最有难度的事情时我怎么回答?
面试官说,这个问题其实并不局限于代码层面,当然如果你确实有花了很大的功夫解决了一个非常困难的问题,自然印象分会更高,如果确实没有,就可以拓展到工作其它方面,比如你推进了项目进程,在期间付出了很多,扮演了一个核心角色,这样也能体现出你的沟通,协同,领导能力等等。我听到这才恍然大悟,之前确实有项目从UI设计初期参与讨论,跟后台讨论定义定义等等,是有过推进项目的经历。
我:对于我之后的面试,或者职业发展能不能给我一些建议?
面试官说看过了我的博客,面试总结写的非常到位,之前初面就是觉得我基础回答非常出色,所以虽然我不会react但也很感兴趣,对我的额外评价是,基础扎实,学习能力很强,自律,让我一定要把写博客的习惯坚持下去,对于后期发展,让我一定要在某个领域专精,这是到高级必经之路,之后转架构或者全栈那就是横向拓展知识面的事情了。
在后面的闲聊中,我才知道他们公司招聘确实算很严格了,面试了200多人,只发了2个offer,其中一个去了大厂没来,最后面试官直言确实很欣赏我,只是公司职位卡的太死,也算是我最后的一点安慰了。
叁 ❀ 某不错的公司
下午面完了上家复试,晚上六点等来了第二家公司的视频初面,大家印象里的初面可能都在半小时之内,结果我这个初面面了一个半小时....也算是让我印象深刻了,那么直接开始。
面:说下你哪个项目最有亮点?
哪个项目最有亮点,做过哪些优化,这些真的是高频问题了,所以大家一定要总结自己项目的出色点,这个真的是必问,我的回答自然是自己负责的重构项目,说了下优化方面的事情。
面:说下你通用服务,比如指令怎么划分?
我前面说过了我的注册由早期统一注册改为了按需加载,所以在重构初期,是对于service,指令做了对应页面、功能的一个初步划分,比如购物车相关的接口API会统一放在购物车的service中,而关于注册方面,如果一个指令,服务是整个项目全局使用的,那就全局注册,如果一个服务是单个页面使用,那就按需加载去注册。
面:我看到你项目中有个错误code的功能,能说下吗?
内部的一个小功能了,之前的复盘也总结过,大家看了也没啥帮助,就不细说了。
面:了解http缓存吗,能不能说下?
首先http1时期,http缓存靠的是绝对过期时间Expires,也就是第一次请求后,服务端给你一个绝对时间,时间没到你就不能请求直接用缓存,这样肯定就很不人性化了。之后http1.1就可以使用Last-Modified来比较文件的修改时间,这也其实也会存在修改时间变了,文件内容没变的情况,所以还是存在一定问题。而最后就是文件内容唯一标识Etag,只要这个对不上,说明文件变化就可以重新下载更新了。除此之外我也简单说了下协商性缓存与强缓存的概念。
面:不知道你有没有了解过,同样都是缓存,但有时候状态码不是304,比如缓存有额外说明
from memory cache,有时候是from disk cache,你知道它们区别吗?
我知道面试官是想问内存缓存与磁盘缓存,真没想到会问这么深...浏览器缓存其实满足三级缓存原理,即走缓存的情况,先看内存中有没有缓存,有就取内存;如果内存中没有,就看磁盘中有没有,有就取磁盘,如果磁盘都没有,那就只有再次发起网络请求,将加载的资源再次缓存到内存和磁盘中。
其次,memory与disk存储方式以及文件类型也不同,具体如下:
- 200 form memory cache:不发起请求,从内存中读取缓存文件,但如果关闭浏览器数据将会被释放,下次再打开页面就得重新请求了,一般脚本,字体,图片都存在内存中。
- 200 form disk cache:不发起请求,从磁盘中读取缓存,关闭浏览器后数据还会存在,所以下次再打开相同页面还是走缓存,磁盘中一般缓存类似css非脚本文件。
面:http2了解吗?
这个因为我也未真正用过,其实都是站在理论层面,所以说了下http2的新增特性:
- http2支持新的二进制格式传输文件
- http2支持通信双方缓存header表信息,这样在下次请求能避免重复数据的传输
- http2支持服务端主动推送数据给客户端。
面:跨域了解吗?说三种常见的解决方案
这个也是常考题,不过方案除了nginx反向代理,JSONP,window.name结合iframe外,前面我们提到的fetch也是一种不错的方案。
面:Virtual DOM了解吗?
因为我并未真正实战过vue和react,这块的理解是很薄弱的,所以就直说不是很了解了,关于虚拟DOM可以深入阅读你不知道的Virtual DOM系列文章。
在面试官确信我不知道虚拟dom之后,后面的问题就开始来考我了。
面:假设现在有1000条数据的长列表,说下不用分页你怎么优化加载?
不使用分页,我能想到的自然就是下拉预加载了,比如首先加载10条数据,用户下拉滚动条快到地步时预加载后10条。
面:你这样做的话,就是一边下拉一边加载,也行,那如果我要一开始拉到滚动条中间位置,直接看到500左右的数据你怎么办?
我大致想了想,前面的方案其实是没有一开始展示总高度的,现在要一开始拉到中间位置,自然要把总高度一开始就计算出来。我就说假设每条数据渲染出来都有固定高度,我先计算出1000条数据需要的总高度,然后根据你拉到中间位置,我是可以获取滚动条距离顶端的高度的,这样我就能计算出需要展示到第几百条数据了。
面:这样做是可以,但是你现在还是渲染出了500条数据,dom也还是很多,有没有办法再优化,给你点提示,回收dom。
问到这我就懵逼了,如果我把前面的数据,也就是超出视窗的数据回收,是可以保证视窗内只展示20条数据,那如果我回滚怎么办,我还得把现在的dom回收掉,不断去取之前的数据再渲染,这操作dom也太复杂了。然后面试官又对我说,回收dom也是我给你留的坑,你前面说了得计算总高度,一旦dom回收,页面高度也会坍塌,所以想来想去没有很好的思路。
面试官笑了笑,说这个其实可以用虚拟dom来做,所以到这我算明白面试官用意,给一个虚拟dom实际场景,在我未掌握该知识的情况下,考我如何用已知知识解决这个问题,第二给我引出虚拟dom的实用性,所以整体我觉得这样问真的是非常有价值的。
在后面的讲解中,我大致理解的做法是这样,当然不一定准确:

面试官的意思是,将我们的浏览器视窗理解成一个画板,随着下拉,从虚拟dom中取到一幅幅画,贴在我们的画板上,由于是绝对定位贴上去的,脱离了文档流,所以不存在高度坍塌的问题;总之到这我就是惊了!
面:你怎么学习一个新知识?
我的学习习惯是先通读文档,比如vue,我先把整体知识框架搭建起来,这样好处是能在深入学习之前就知道部分知识的关联性,整体架构建好了,自然可以根据前辈的经验,对于重点难点进行深入学习。学习对我而言,最重要的是避免只见树木不见森林。
面:你怎么平衡知识的新与旧?
我觉得新与旧是一个相对的概念,无法轻易下结论谁好谁坏。旧的东西自然更稳定性,风险性要小,但是思想上可能不如新知识更具便捷性与创新,但也不提倡死板守旧,新的思想总是可以接纳的。所以以项目重构而言,还是得考虑成本,风险等多方面因素。
面:一个树形结构数据,不用递归,如何用遍历去访问它?
因为说到树本能会想到递归吧,大致给个类似的题目大家看看,求如下数据value的和(题目来源在Javascript中,如何才能不使用递归来遍历一个树状结构?):
var nodes = {
value: 1,
children: [{
value: 2,
children: [{
value: 4,
children: []
},
{
value: 3,
children: []
},
]
},
{
value: 5,
children: []
},
]
};
如果用递归,就是判断nodes的children还有没有子元素,有就继续递归调用自身方法
function sum(nodes) {
if (nodes.children.length === 0) {
return nodes.value;
}
return nodes.children.reduce((pre, cur) => {
return pre + sum(cur);
}, nodes.value)
};
如果不准用递归,就得借用其它数据结构,比如队列(先进先出):
function bfs(nodes) {
const queue = []
let sum = 0
queue.push(nodes)
while (queue.length) {
const curNode = queue.pop();
sum += curNode.value;
curNode.children.forEach(ele => queue.push(ele));
};
return sum;
};
当然这不是我答得,只是给出了一个类似的题目,我算法还是小弱鸡。
大致到这,面试就结束了,因为跟面试官聊得还可以,果不其然,第二天收到了复试邀请,在下周二,说实话吧....初面就这么深入,复试是技术总监面,我感觉有点悬,具体面了再说。
肆 ❀ 逃离湖泊投身大海的鱼
说下这周面试的感受,我大概就是逃离湖泊投身大海的鱼,以前在上家公司,同事觉得我见多识广,博客园朋友觉得我多厉害,其实几番面试下来,我自己深知自己与大佬之间的差距,虽然一开始我就不觉得自己有啥厉害的。技术深度,解决问题的能力,软件设计等等,但这些都不是一时半会能培养起来的,仍需要工作的积累,这也是我为何对于下家公司技术团队比较看重的原因。
每天压力还是很大,面试就像一场考试,不管考得好不好,考完了总是觉得松了口气,像是可以逃避了一样,可是终究逃不掉,我还是得继续安排之后的面试,以及不断的面试。而回想当初离职的决定,我现在反而觉得更正确了,一开始就知道这次会很难,再难这次也要挺过去。
这篇文章花了我一个周末的时间(昨天写到了凌晨2点...),写到这居然已经有九千字了,大概是我所有博客里最长的一篇了。我也希望能尽快找到满意的工作,结束这个系列的更新,毕竟谁又愿意顶着压力天天写面试分享呢,真正的难受也只有自己心里清楚。
但不管怎么说,我还是会坚持,有面试就一定会总结,只要自己不认输,那我永远就没有输,请继续加油!本文结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号