
从零开始学正则(六),如何提升正则准确性与效率

壹 ❀ 引
我在 从零开始学正则(五)这篇文章中介绍了正则常见结构与操作符,在了解操作符的优先级后,知晓了如何去拆分一个看似复杂的正则表达式。正则除了会看会读,会写一个正则往往更重要。那么要去写一个正则就面临了诸多问题,什么时候该用正则?怎么保证正则的准确性?正则如何提升性能?那么本篇文章将从这三个点出发,让我们在会写正则的前提下写的更好。
说在前面,正则学习系列文章均为我阅读 老姚《JavaScript正则迷你书》的读书笔记,文中所有正则图解均使用regulex制作。那么本文开始!
贰 ❀ 该不该使用正则?
看到这个标题你肯定纳闷,学的就是正则,怎么还该不该用正则?但在实际开发中,一个问题可以用正则解决,其实也可以使用其它方法解决。我们学正则不一定要死板的想要用正则解决所有问题,或许使用其它做法更棒呢?
比如我们现在有字段 2019-12-24 ,我想分别取出年月日,使用正则可以使用match方法配合分组获取实现:
var result = '2019-12-24'.match(/^(\d{4})-(\d{2})-(\d{2})$/); console.log(RegExp.$1, RegExp.$2, RegExp.$3); //2019 12 24
有没有其它做法呢?别忘了字符串的 split 切割方法,比如:
var arr = '2019-12-24'.split('-'); console.log(arr[0], arr[1], arr[2]);//2019 12 24
相比之下你觉得哪种更简单呢?
再如我们想验证字符串中是否包含“:”,我们可以使用正则实现:
var result = /\:/.exec('12:34'); console.log(result); //[":", index: 2, input: "12:34", groups: undefined]
更简单的做法,我们可以直接使用indexOf检查索引,如果没有返回-1,如果有返回第一个匹配的字符下标。
var result = '12:34'.indexOf(":"); console.log(result); //2
最后看个截止字段的例子,相比使用正则,使用字符串方法substr或substring都会简单很多。当然若你对这两个方法有疑惑,可以读读博主这篇文章 substring和substr以及slice和splice的用法和区别。
var string = "hello,听风是风"; var result = /.{6}(.+)/.exec(string)[1]; console.log(result); //听风是风 var result = string.substr(6); console.log(result); //听风是风 var result = string.substring(6); console.log(result); //听风是风
通过以上三个例子可以看出,在一些更偏于字符操作的情况下,该使用字符串方法就得用,学会灵活变通。
叁 ❀ 正则的准确性
何为准确性,一段正则除了能匹配我们所需要的,还得保证不会匹配那些我们不需要的,假设我们现在要匹配如下三种座机(固定电话)号码,该如何写这个正则呢:
var num1 = '055188888888'; var num2 = '0551-88888888'; var num3 = '(0551)88888888';
科普一下,座机号码由 区号+座机号 组成,且区号长度为3-4位数字且首位数字必须为0,而座机号由7-8位数字组成,且首数字不能为0。
尝试分析上面三种座机号码格式,第一种为区号直接拼号码,第二种使用了拼接符 - ,第三种使用了圆括号包裹区号,很明显这是三种分支情况,所以我们可以先写匹配数字的正则,再加分支条件。
只是匹配数字这也太简单了,不假思索的写出 /^\d{3,4}\d{7,8}$/ ,那么这段正则就是不具备准确性的正则,别忘了我们在前面有提到区号与号码首数字的问题,所以改改应该是这样:
var regexp = /^0\d{2,3}[1-9]\d{6,7}$/;
当然这个正则只能匹配区号直接紧接号码的情况,有拼接符的情况就是这样:
var regexp = /^0\d{2,3}-[1-9]\d{6,7}$/;
带圆括号的格式就是这样:
var regexp = /^\(0\d{2,3}\)[1-9]\d{6,7}$/;
我们仔细对比这三段正则,可以发现正则后半段是完全相同的,区别也只是在前半段,所以将前部分以分支表示,改写正则后应该是这样:
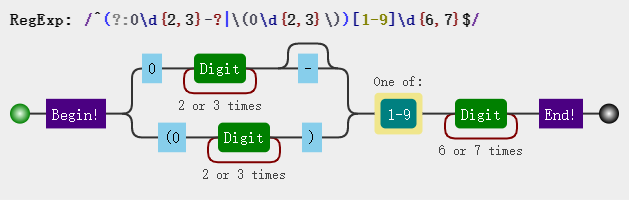
var regexp = /^(?:0\d{2,3}|0\d{2,3}-|\(0\d{2,3}\))[1-9]\d{6,7}$/;
还能不能简写?仔细观察前两种分支情况,一个是无拼接符一个是有拼接符,除此之外其它部分都一样,这不又可以组合成拼接符可有可无的情况了,所以我们再次简化:
var regexp = /^(?:0\d{2,3}-?|\(0\d{2,3}\))[1-9]\d{6,7}$/;
我们简单测试下,发现完全没问题
console.log(regexp.test(num1)); //true console.log(regexp.test(num2)); //true console.log(regexp.test(num3)); //true
说到拼接符可有可无,可能有的同学就想到了,我圆括号也可以写成可有可无,这样正则不是看着更精简了,像这样:
var regexp = /^\(?0\d{2,3}\)?-?[1-9]\d{6,7}$/;
但这样就造成了一个问题,你会发现同时有括号和拼接符,或者说有一半括号的格式都能匹配:
console.log(regexp.test('(0551-88888888')); //true
console.log(regexp.test('(0551)-88888888')); //true
console.log(regexp.test('0551)88888888')); //true
很明显这不是我们想要的情况,这段正则就缺失了很重要的精准性。
我们来看第二个例子,写一个匹配浮点数的正则,要求能匹配如下几种数据类型:
1.23、+1.23、-1.23
10、+10、-10
.2、+.2、-.2
我们结合这三种数据来做个分析,首先关于正负符号很明显是可有可无,毋庸置疑可以写成 [+-]?;然后是整数部分,可能是多位整数也可能没有,所以是 (\d+)?;最后是小数点部分,因为可能不存在小数点,所以可以写成 (\.\d+)?,所以结合起来就是:
var regexp = /^[+-]?(\d+)?(\.\d+)?$/;
这个正则有个最大的弊端,因为三个条件后面都有?表示可有可无,极端一点,三个都为无,所以这个正则可以匹配空白:
/^[+-]?(\d+)?(\.\d+)?$/.test("");//true
可能有同学敏锐的发现了,.2,+.2这种情况都是整数部分为0的情况,那能不能为写成这样 /^[+-]?(0?|[1-9]+)(\.\d+)?$/ ,很明显也不行,比如10,+10这种整数用到了0,所以无法通过分支来控制0的显示隐藏。
那怎么做呢?还是与匹配座机号码一样,我们针对三种情况分开写正则,比如匹配 "1.23"、"+1.23"、"-1.23",正则可以这样写:
var regexp = /^[+-]?\d+\.\d+$/;
匹配 "10"、"+10"、"-10" 的正则可以写成:
var regexp = /^[+-]?\d+$/;
匹配 ".2"、"+.2"、"-.2" 正则可以写成:
var regexp = /^[+-]?\.\d+$/;
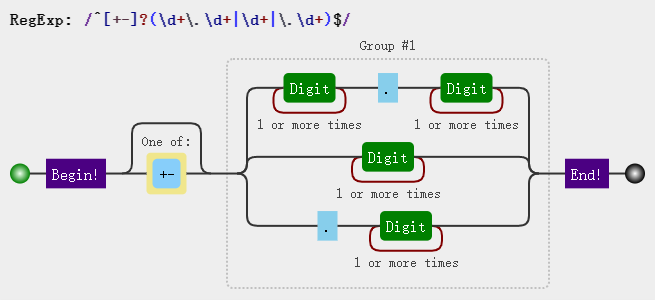
我们提取三个正则的共用部分,很明显就是 [+-]? 这一部分,其它部分采用分支表示,综合起来就是这样:
var regexp = /^[+-]?(\d+\.\d+|\d+|\.\d+)$/;
简单测试,完全没问题:
regexp.test("+.2"); //true
regexp.test("-.2"); //true
regexp.test("10.2"); //true
regexp.test("+10.2"); //true
虽然这种分情况写,再抽出共用部分,将非共用分支表示的做法有点繁琐,但对于正则新手来说确实是最为稳妥保证精准性的做法。
肆 ❀ 正则的效率
在确保正则的精准性之后,剩下的就是如何提升正则的效率性能了(当然对于我这样的新手,能写出来就不错了...)。
如何提升正则性能,我们一般从正则的运行阶段下手,正则完整的运行分为如下几个阶段:编译 --- 设定起始位置 --- 尝试匹配 --- 匹配失败的话,从下一位开始继续第 3 步 --- 最终结果:匹配成功或失败。
我们可以通过下面这个例子模拟这个过程:
var regex = /\d+/g; console.log(regex.lastIndex, regex.exec("123abc34def")); //0 ["123", index: 0, input: "123abc34def", groups: undefined] console.log(regex.lastIndex, regex.exec("123abc34def")); //3 ["34", index: 6, input: "123abc34def", groups: undefined] console.log(regex.lastIndex, regex.exec("123abc34def")); //8 null console.log(regex.lastIndex, regex.exec("123abc34def")); //0 ["123", index: 0, input: "123abc34def", groups: undefined]
是的你没看过,明明都是输出相同的东西,每次输出的内容居然还不一样。这是因为当使用 test 或者 exec 方法且正则尾部有 g 时,比如像上面执行多次,下次执行时匹配的起始位置是从上次失败的位置。说直白点,使用这两个方法就像有记忆功能一样,每次执行都是从上次结束的位置开始,比如我们用match方法就不会有这个问题:
var regex = /\d+/g; console.log(regex.lastIndex, "123abc34def".match(regex));//0 ["123", "34"] console.log(regex.lastIndex, "123abc34def".match(regex));//0 ["123", "34"] console.log(regex.lastIndex, "123abc34def".match(regex));//0 ["123", "34"] console.log(regex.lastIndex, "123abc34def".match(regex));//0 ["123", "34"]
我们就通过上面exec来分析正则执行阶段。第一次执行匹配从字符串索引0开始,因为是全局匹配,所以一直匹配到了3,所以匹配结果为123,匹配到a时因为不满足,所以失败了。
第二次开始就是从上次失败的地方开始,所以是从索引3开始,在经历了abc三次失败后,终于遇到了数字34,匹配成功,再往下走时是d,所以又失败了。
第三次匹配开始的起点就是索引8,但因为def都是字母,全部不符合,匹配结果,最后返回了一个null,此时索引被重置为0。
因为起始位置被重置,所以第四次匹配重复了第一次匹配的操作,又是一轮新的开始。
其实看上面exec的例子就反应出了一个问题,每次执行正则都有记录最后匹配失败的位置供下次匹配使用,回溯也是如此,正则会记录多种可能中未尝试过的状态以便回溯使用,这是非常消耗内存的。我们来综合给出几点优化建议:
1.尽量使用具体的字符来替代通配符,减少回溯
比如我们想匹配 123"abc"456 中的 "abc",使用正则 /"[^"]*"/ 的性能要远高于 /".*"/,使用/"\w{3}"/当然更好。
2.使用非捕获型分组
在介绍分组时我们已经说过,正则会记录每个分组的匹配结果。如果我们的分组只是为了单纯起到匹配的作用,而不喜欢正则默认去帮我们记录分组的匹配结果,可以使用非捕获型分组。
'123abc456'.match(/(\w{3})/);
console.log(RegExp.$1);//134
//使用非捕获型分组
'123abc456'.match(/(?:\w{3})/);
console.log(RegExp.$1);//为空,未记录
3.独立出确定字符
比如我们有正则 /a+/ 可以修改为 /aa*/,因为后者在匹配时能比前者多确定一个字符,不管是失败还是成功,都能更快一部=步确认。
4.提取分支
我们在介绍匹配座机号码与浮点数已经有阐述这一点,将正则共用部分抽离出来,不同部分作为分支,比如将 /this|that/ 修改为 /th(?:is|at)/,这样能减少重复匹配。
5.减少分支数量,缩小匹配范围
虽然推荐抽出共用后使用分支,但有些特殊分支情况能简写复用的还是推荐简写,比如 /red|read/ 可以修改成 /rea?d/。因为分支如果匹配失败,切换到另一条分支时也需要回溯。
伍 ❀ 总
那么到这里,第六章节所有知识全部介绍完毕了。这一章节主要是站在能写正则的基础上,进一步优化正则写法,提升正则匹配的精准性,以及正则运行的性能。共用部分正则,将不同进行分支算是我读下来最大感触的地方,对于优化而言还是需要一定的实战积累,不过先建立优化的观念也不是坏事。那么就说到这里了,今天圣诞节,本来想早点睡觉,结果又写到12点了....晚安,圣诞快乐,本文结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号