
for循环中let与var的区别,块级作用域如何产生与迭代中变量i如何记忆上一步的猜想

我在前一篇讨论let与var区别的博客中,顺带一笔带过了let与var在for循环中的不同表现,虽然解释了是块级作用域的影响,但具体是怎么去影响的呢,我尝试的去理解了下,这篇博客主要从for循环步骤拆分的角度去理解两者的区别。
一、一个简单的for循环问题与我思考后产生的问题
还是这段代码,分别用var与let去声明变量,得到的却是完全不同的结果,为什么?如果让你把这个东西清晰的讲给别人听,怎么去描述呢?
//使用var声明,得到3个3 var a = []; for (var i = 0; i < 3; i++) { a[i] = function () { console.log(i); }; } a[0](); //3 a[1](); //3 a[2](); //3 //使用let声明,得到0,1,2 var a = []; for (let i = 0; i < 3; i++) { a[i] = function () { console.log(i); }; } a[0](); //0 a[1](); //1 a[2](); //2
在弄懂这个问题前,我们得知道for循环是怎么执行的。首先,对于一个for循环,设置循环变量的地方是一个父作用域,而循环体代码在一个子作用域内;别忘了for循环还有条件判断,与循环变量的自增。
for循序的执行顺序是这样的:设置循环变量(var i = 0) ==》循环判断(i<3) ==》满足执行循环体 ==》循环变量自增(i++)
我们按照这个逻辑改写上面的for循环,以第一个var声明为例,结合父子作用域的特点,上面的代码可以理解为:
{ //我是父作用域 var i = 0; if (0 < 3) { a[0] = function () { //我是子作用域 console.log(i); }; }; i++; //为1 if (1 < 3) { a[1] = function () { console.log(i); }; }; i++; //为2 if (2 < 3) { a[2] = function () { console.log(i); }; }; i++; //为3 // 跳出循环 } //调用N次指向都是最终的3 a[0](); //3 a[1](); //3 a[2](); //3
而当我们将模拟步骤代码中的声明方式由var修改为let后执行代码,结果发现输出的还是3个3!WTF???

按照模糊的理解,当for循环使用let时产生了块级作用域,每次循环块级作用域中的 i 都相互独立,并不像var那样全程共用了一个。
但是有个问题,子作用域中并没有let,何来的块级作用域,整个循环也就父作用域中使用了一次let i = 0;子作用域哪里来的块级作用域?
请教了下百度的同学,谈到了会不会是循环变量不止声明了一次,其实自己也考虑到了这个问题,for循环会不会因为使用let而改变了我们常规理解的执行顺序,自己又在子作用域用了let从而创造了块级作用域?抱着侥幸的心理还是打断点测试了一下:
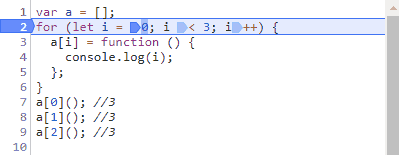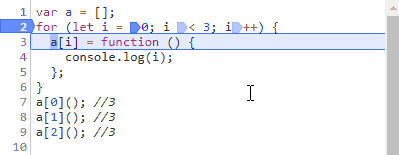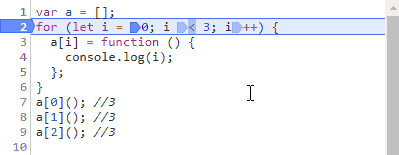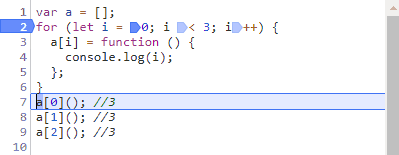
可以看到,使用let还是一样,声明只有一次,之后就在后三个步骤中来回跳动了。
二、一个额外问题的暗示
如果说,在使用let的情况下产生了块级作用域,每次循环的i都是独立的一份,并不共用,那有个问题,第二次循环 i++ 自增时又是怎么知道上一个块级作用域中的 i 是多少的。这里得到的解释是从阮一峰ES6入门获取的。
JavaScript 引擎内部会记住上一轮循环的值,初始化本轮的变量
i时,就在上一轮循环的基础上进行计算。
那这就是JS引擎底层实现的问题了,我还真没法用自己的代码去模拟去实现,我们分别截图var与let断点情况下作用域的分布。
首先是var声明时,当函数执行时,只能在全局作用域中找到已被修改的变量i,此时已被修改为3
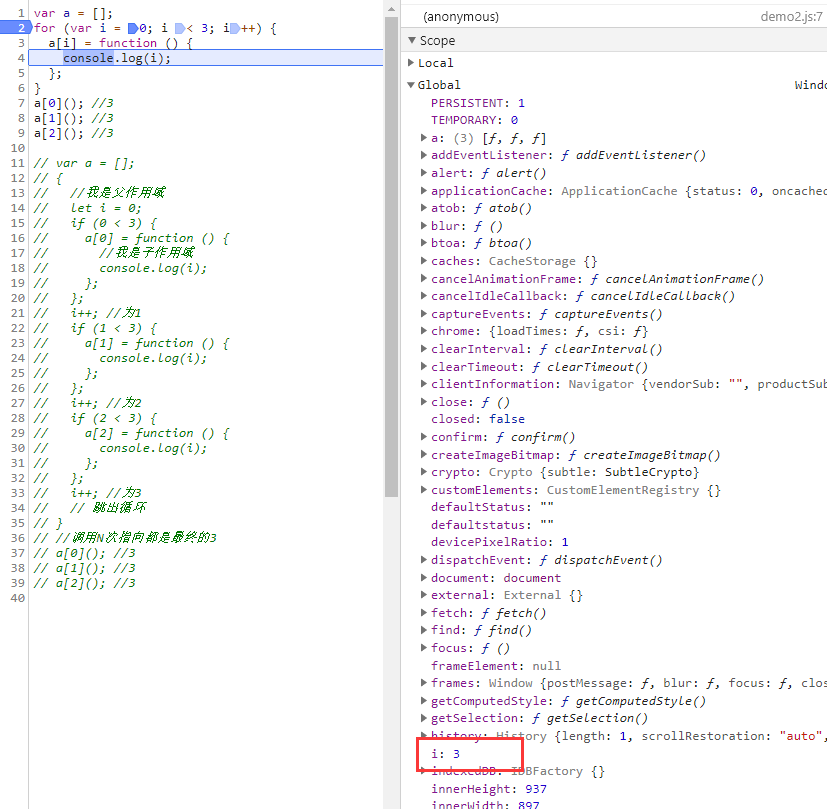
而当我们使用let声明时,子作用域本没有使用let,不应该是是块级作用域,但断点显示却是一个block作用域,而且可以确定的是整个for循环let i只声明了一次,但产生了三个块级作用域,每个作用域中的 i 均不相同。
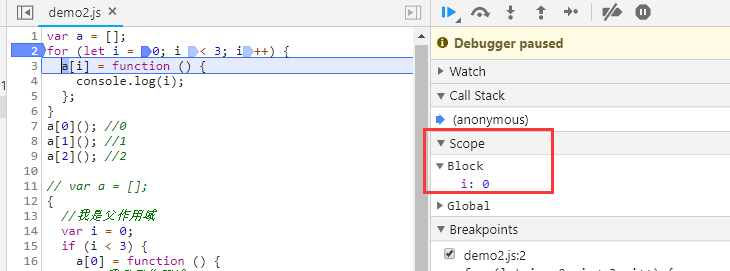
那在子作用域中,我并没有使用let,这个块级作用域哪里开的,从JS引擎记录 i 的变换进行循环自增而我们却无法感知一样,我猜测,JS引擎在let的情况下,每次循环自己都创建了一个块级作用域并塞到了for循环里(毕竟子作用域里没用let),所以才有了三次循环三个独立的块级作用域以及三个独立的 i。
这也只是我的猜测了,可能不对,如果有人能从JS底层实现给我解释就更好了。
PS:2019.4.19更新
之前对于for循环中使用let的步骤拆分推断,我们得到了两个结论以及一个猜想:
结论1:在for循环中使用let的情况下,由于块级作用域的影响,导致每次迭代过程中的 i 都是独立的存在。
结论2:既然说每次迭代的i都是独立的存在,那i自增又是怎么知道上次迭代的i是多少?这里通过ES6提到的,我们知道是js引擎底层进行了记忆。
猜测1:由于整个for循环的执行体中并没有使用let,但是执行中每次都产生了块级作用域,我猜想是由底层代码创建并塞给for执行体中。
由于写这篇博客的时候顺便给同事讲了let相关知识,同事今天也正好看了模拟底层实现的代码,这个做个补充:
还是上面的例子,我们在let情况下对for循环步骤拆分,代码如下:
var a = []; { //我是父作用域 let i = 0; if (i < 3) { //这一步模拟底层实现 let k = i; a[k] = function () { //我是子作用域 console.log(k); }; }; i++; //为1 if (i < 3) { let k = i; a[k] = function () { console.log(k); }; }; i++; //为2 if (i < 3) { let k = i; a[k] = function () { console.log(k); }; }; i++; //为3 // 跳出循环 } a[0](); //0 a[1](); //1 a[2](); //2
上述代码中,每次迭代新增了let k = i这一步,且这一步由底层代码实现,我们看不到;
这一行代码起到两个作用,第一是产生了块级作用域,解释了这个块级作用域是怎么来的,由于块级的作用,导致3个k互不影响。
第二是通过赋值的行为让3个k都访问外部作用域的i,让三个k建立了联系,这也解释了自增时怎么知道上一步是多少。
这篇文章有点钻牛角尖了,不过有个问题在心头不解决是真的难受,大概如此了。
PS:2019.11.28更新
谢谢博友 coltfoal 在基本数据类型与引用数据的概念上提供了一个有趣的例子,代码如下,猜猜输出什么:
var a = [] for (let y = {i: 0}; y.i < 3; y.i++) { a[y.i] = function () { console.log(y.i); }; }; a[0](); a[1](); a[2]();
你一定会好奇,为什么输出的是3个3,不是说let会创建一个块级作用域吗,我们还是一样的改成写模拟代码,如下:
var a = []; { //我是父作用域 let y = { i: 0 }; if (y.i < 3) { //这一步模拟底层实现 let k = y; a[k.i] = function () { //我是子作用域 console.log(k.i); }; }; y.i++; //为1 if (y.i < 3) { let k = y; a[k.i] = function () { console.log(k.i); }; }; y.i++; //为2 if (y.i < 3) { let k = y; a[k.i] = function () { console.log(k.i); }; }; y.i++; //为3 // 跳出循环 } a[0](); //3 a[1](); //3 a[2](); //3
注意,在模拟代码中为let k = y而非let k = y.i。我们始终使用let声明一个新变量用于保存for循环中的初始变量y,以达到创建块级作用域的目的,即使y是一个对象。
那为什么有了块级作用域,最终结果还是相同呢,这就涉及了深/浅拷贝的问题。由于y属于引用数据类型,let k = y 本质上是保存了变量 y 指向值的引用地址,当循环完毕时,y中的 i 已自增为3。
变量k因为块级作用域的原因虽然也是三个不同的k,但不巧的是大家保存的是同一个引用地址,所以输出都是3了。
我们再次改写代码,说说会输出什么:
var a = [] var b = {i:0}; for (let y = b.i; y < 3; y++) { a[y] = function () { console.log(y); }; }; a[0](); a[1](); a[2]();
对深/浅拷贝有疑问可以阅读博主这篇博客 深拷贝与浅拷贝的区别,实现深拷贝的几种方法
若对JavaScript中基本数据类型,引用数据类型的存储有兴趣,可以阅读 JS 从内存空间谈到垃圾回收机制 这篇博客。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号