
Oracle PL/SQL异常、存储过程和触发器
一、异常
1、处理异常
(1)除数不为0
1 declare 2 b number; 3 begin 4 b:=1/0; 5 exception 6 when zero_divide then 7 dbms_output.put_line('除数不能为0'); 8 end;
DBMS输出:除数不能为0。
(2)找不到参数
1 declare 2 vename varchar2(20); 3 begin 4 select ename into vename from emp where deptno=200; --此处会报no date found异常 5 exception 6 when no_date_found then 7 dbms_output.put_line('未找到任何数据'); 8 end;
DBMS输出:未找到任何数据。
2、自定义异常
1 declare 2 --声明变量 3 vreturn varchar2(20); 4 vename emp.ename%type; 5 vsal emp.sal%type; 6 7 --声明异常 8 sal_isnull exception; 9 sal_iszero exception; 10 sal_islow exception; 11 12 begin 13 vename:=&ename; 14 select sal into vsal from emp where vename=&ename; 15 16 --定义抛出异常条件 17 if vsal is null then 18 vreturn:=vename; 19 raise sal_isnull; 20 21 elsif vsal is null 22 vreturn:=vename; 23 raise sal_iszero; 24 25 elsif vsal<1850 then 26 vreturn:=vename; 27 raise sal_islow; 28 end if; 29 30 --自己处理异常 31 exception 32 when sal_isnull then 33 dbms_output.put_line(vreturn||'工资为空异常'); 34 35 when sal_iszero then 36 dbms_output.put_line(vreturn||'工资为0'); 37 38 when sal_islow then 39 dbms_output.put_line(vreturn||'工资低于标准工资'); 40 end;
控制台输入:'MARTIN' DBMS输出:工资低于标准工资
二、存储过程
迄今为止,所创建的PL/SQL程序都是匿名的,其缺点是在每次执行的时候都要被重新编译,并且没有存储在数据库中,因此不能被其他PL/SQL块使用。Oracle允许在数据库的内部创建并存储编译过的PL/SQL程序,以便随时调用。该类程序包括过程、函数、包和触发器。我们可以将商业逻辑、企业规划等写成过程或函数保存到数据库中、通过名称进行调用,以便更好地共享和使用。
存储过程(Stored Procedure )是一组为了完成特定功能的SQL 语句集,经编译后存储在数据库中。用户通过指定存储过程的名字并给出参数(该存储过程亦可带有参数)来执行它。存储过程是由流控制和SQL 语句书写的过程,这个过程经编译和优化后存储在数据库服务器中,应用程序使用时只要调用即可。
适用一下情况:
-
-
- 需要长期保存在数据库中
- 需要被多个用户重复调用
- 业务逻辑相同,参数不同
- 大批量的数据插入、修改和删除等操作
-
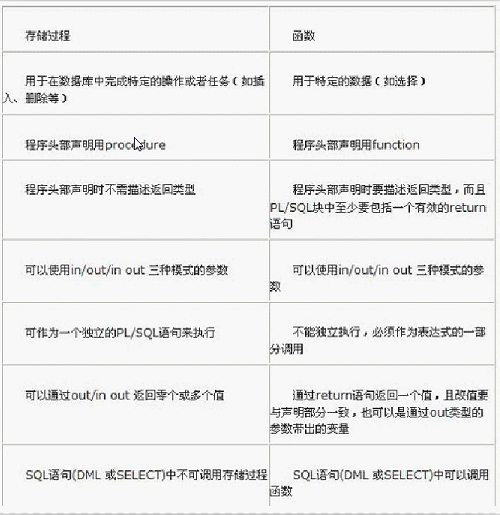
与函数的区别:
1、函数只能返回一个值,且必须设置返回值,在存储过程可以返回多个值。
2、最大的区别:函数要放入sql语句或者某个表达式进行调用,而存储过程可以独立执行且不能被sql语句调用,直接通过call或者declare直接执行。
3、函数限制比较多,比如不能用临时表,只能用表变量.还有一些函数都不可用等等.而存储过程的限制相对就比较少。
4、一般来说,存储过程实现的功能要复杂一点,而函数的实现的功能针对性比较强。
5、对于存储过程来说可以返回参数,而函数只能返回值或者表对象。
6、存储过程一般是作为一个独立的部分来执行(EXEC执行),而函数可以作为查询语句的一个部分来调用(SELECT调用),由于函数可以返回一个表对象,因此它可以在查询语句中位于FROM关键字的后面。
7、当存储过程和函数被执行的时候,SQL Manager会到procedure cache中去取相应的查询语句,如果在procedure cache里没有相应的查询语句,SQL Manager就会对存储过程和函数进行编译。
Procedure cache中保存的是执行计划 (execution plan) ,当编译好之后就执行procedure cache中的execution plan,之后SQL SERVER会根据每个execution plan的实际情况来考虑是否要在cache中保存这个plan,评判的标准一个是这个execution plan可能被使用的频率;其次是生成这个plan的代价,也就是编译的耗时。保存在cache中的plan在下次执行时就不用再编译了。
如下图所示:
优点:
1、存储过程只在创造事进行编译,以后每次执行存储过程都不需要重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可以提高数据库的执行速度。
2、当对数据库进行附在小左时(如对锁哥表进行update,insert,query,delete),可以将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。
3、存储过程可以重复使用,可减少数据库开发人员的工作量。
4、安全性高,可设定只要某用户才具有对制定存储过程的使用权。
5、减少网络交互的成本。
缺点:
1、不可移植性,每种数据库的内部变成语法都不大相同,当系统需要兼容多种数据库时,最好不要用存储过程。
2、学习成本高,DBA一般都擅长写存储过程,但不是每个程序员都能写好存储过程,否则后期系统维护会产生问题。
3、业务逻辑多出存在,采用存储过程后意味着你的系统有一些业务逻辑不是应用程序里处理,这种架构会增加一些系统位数和调试成本。
4、存储过程和常用应用程序语言不一样,它支持的函数及语法有可能不满足需求,有些逻辑只能通过应用程序处理。
5、如果存储过程中有复杂运算的话,会增加依稀额数据库服务端的处理成本,对于集中式数据库可能会导致可扩展性问题。
6、为了提高性能,数据库会把存储过程代码编译成中间运行代码(类似于java的class文件),当存储过程引用的对象(表、视图等等)结构改变后,存储过程需要重新编译才能生效,在24*7高并发应用场景,一般都在线变更结构,所以在变更的瞬间要同时编译存储过程,这可能导致数据库瞬间压力上升引起故障。
1、创建过程
格式:
--创建过程
create or replace procedure 过程名
(可含参数(in 输入参数,out输出参数),可无参) as
begin
语句块;
end;
1 --创建过程 2 create or replace procedure pd_deptnocount 3 (vdeptno in number,vcount out number) as --返回值是vcount 4 begin 5 select count(empno) into vcount from emp 6 where deptno vdeptno 7 group by deptno; 8 end;
2、调用过程(匿名语句块)
1 declare 2 vdeptno number; 3 vcount number; 4 begin 5 vdeptno:=&deptno; 6 pd_deptnocount(vdeptno,vcount); 7 dbms_output.put_line(vdeptno||'部门共有员工'||vcount); 8 end;
执行:在控制台输入20,DBMS输出:20部门共有员工5
3、游标的存储过程
a、在一个包内定义一个游标类型。
b、创建存储过程,打开游标抓取的对象。
c、调用时,先创建包类游标,执行存储对象把游标设置好,通过loop执行游标,关闭游标。
1 --1、在包体声明游标类型 2 create or replace package mypackage 3 as 4 type mycustype is ref cursor; --声明游标的类型 ref:符复合类型 5 end; 6 7 --2、编写存储过程 8 --打开游标,将select查询的内容封装到游标里面 9 create or replace procedure pd_selectename 10 (mycus out mypackage.mycustype) as 11 begin 12 open mycus for select * from emp; 13 end; 14 15 --3、调用过程 16 declare 17 --定义游标 游标名 游标类型 18 mycus mypackage.mycustype; 19 vrow emp%rowtype; 20 begin 21 pd_selectename(mycus); 22 --不需要打开游标,上面已经打开了 23 loop 24 fetch mycus into vrow; --抓取一整行 25 exit when mycus%notfound; 26 dbms_output.put_line(vrow.ename); 27 end loop; 28 close mycus; 29 end; 30
分步执行1、2和3,最终执行结果:

例:输入表名,返回最大行数(多少条数据)。
1 create or replace procedure pd_countTable --创建 2 (tablename in varchar2,tablerow out number) 3 as 4 mysql varchar2(500); 5 begin 6 mysal:='select count(*) from '||tablename; 7 execute immediate mysql into tablerow; 8 end; 9 10 --调用 11 declare 12 countAll number; 13 tablename varchar2(20); 14 begin 15 tablename:=&tablename; 16 pd_countTable(tablename,countrow); 17 dbms_output.put_line(countrow); 18 end;
执行:在控制台输入‘emp’,DBMS输出:15(有15行数据)
三、触发器
触发器的定义就是说某个条件成立的时候,触发器里面所定义的语句就会被自动的执行。
它的执行由事件触发。触发器经常用于加强数据的完整性约束金额业务规则等。
触发器与存储过程唯一的区别是触发器不能执行execute语句调用,而是在用户执行Transact-SQL语句时自动触发执行。
语法:
create [or replace] trigger 触发器名 触发时间(after/before) 触发事件(update、delete、select)
on 表名
[for each row]
begin
pl/sql语句
end;
1 create or replace trigger trtest 2 after update of 3 sal on emp 4 for each row 5 begin 6 insert into t_logs(txt) values 7 (:old.ename||'原工资'||:old.sal||',修改后的工资为'||:new.sal); 8 end;
该在数据栏改动任意一个员工的工资3000->4000,会自动执行触发器,执行结果:

触发器类型:
a、语句级触发器
在指定的操作语句执行之前或之后执行一次,不管这条语句影响了多少行
b、行级触发器(有FOR EACH ROW的)
触发语句作用的每一条记录都被触发。在行级触发器中使用:old和:new伪记录变量,识别值的状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号