Python简易 爬虫+图形化界面(2020/7/5已更新)
一.简单爬取页面内容
所需要库:thinter,python3自带
代码:
from tkinter import * import re import requests def input1(): link = str(inp1.get()) headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'} r = requests.get(link, headers=headers) html = r.text post = re.findall('<span class="post-view-count">(.*?)</span>', html) txt.insert(END, post) # 追加显示运算结果 inp1.delete(0, END) root = Tk() root.geometry('460x240') root.title('爬取阅读数界面') lb1 = Label(root, text='请输入需要爬取的网页') lb1.place(relx=0.1, rely=0.1, relwidth=0.8, relheight=0.1) inp1 = Entry(root) inp1.place(relx=0.1, rely=0.2, relwidth=0.8, relheight=0.1) # 方法 btn1 = Button(root, text='开始爬取', command=input1) btn1.place(relx=0.1, rely=0.3, relwidth=0.8, relheight=0.2) # 在窗体垂直自上而下位置60%处起,布局相对窗体高度40%高的文本框 txt = Text(root) txt.place(rely=0.6, relheight=0.4) root.mainloop()
相关参数,参考:https://www.jianshu.com/p/91844c5bca78
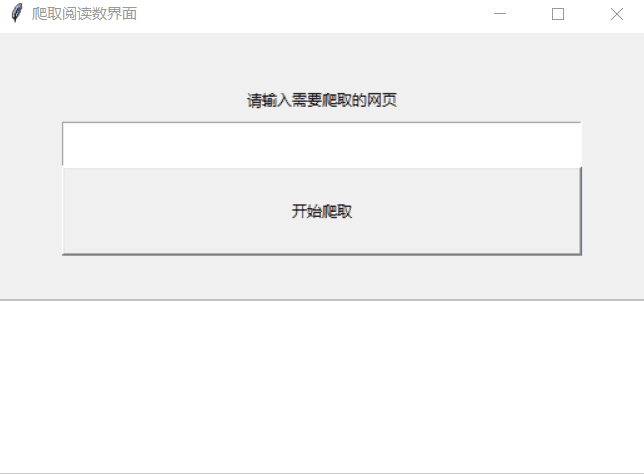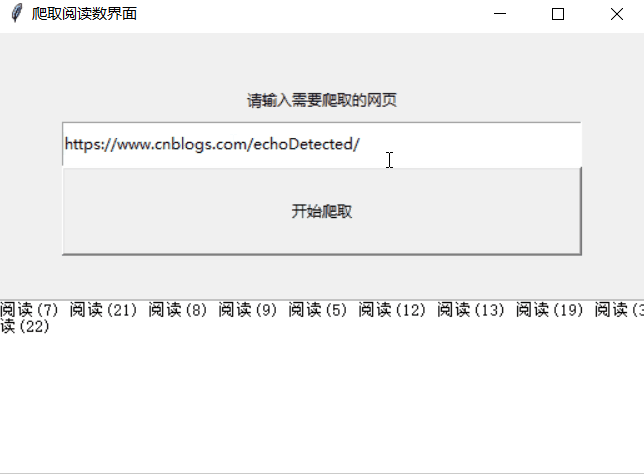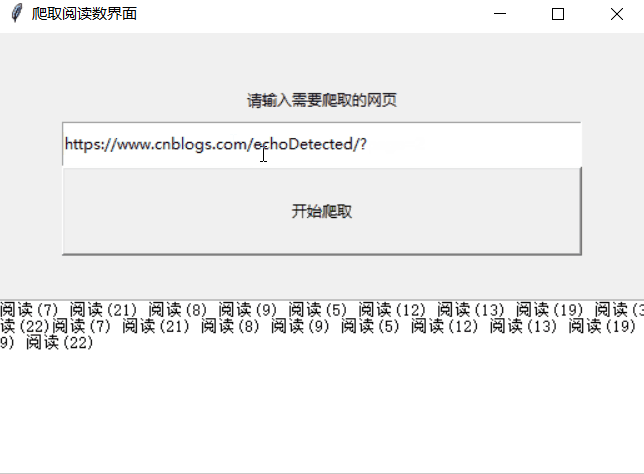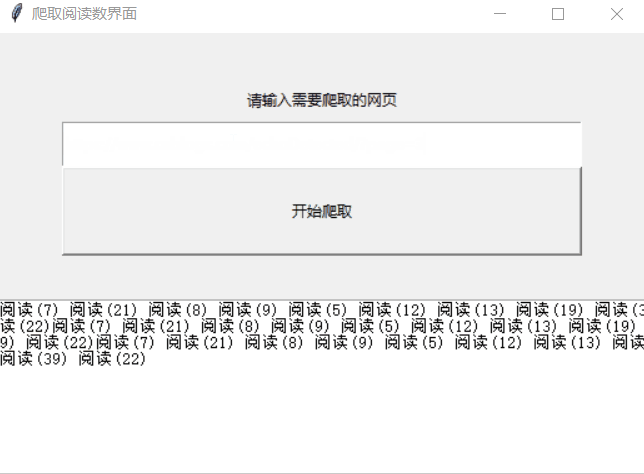
原理:爬取自己博客的阅读数,给爬虫一个交互界面,简单的用tkinter做到接收输入,按钮调用,最后输出的结果
实现结果因网页结构而异
效果:
二.图片的爬取
代码:
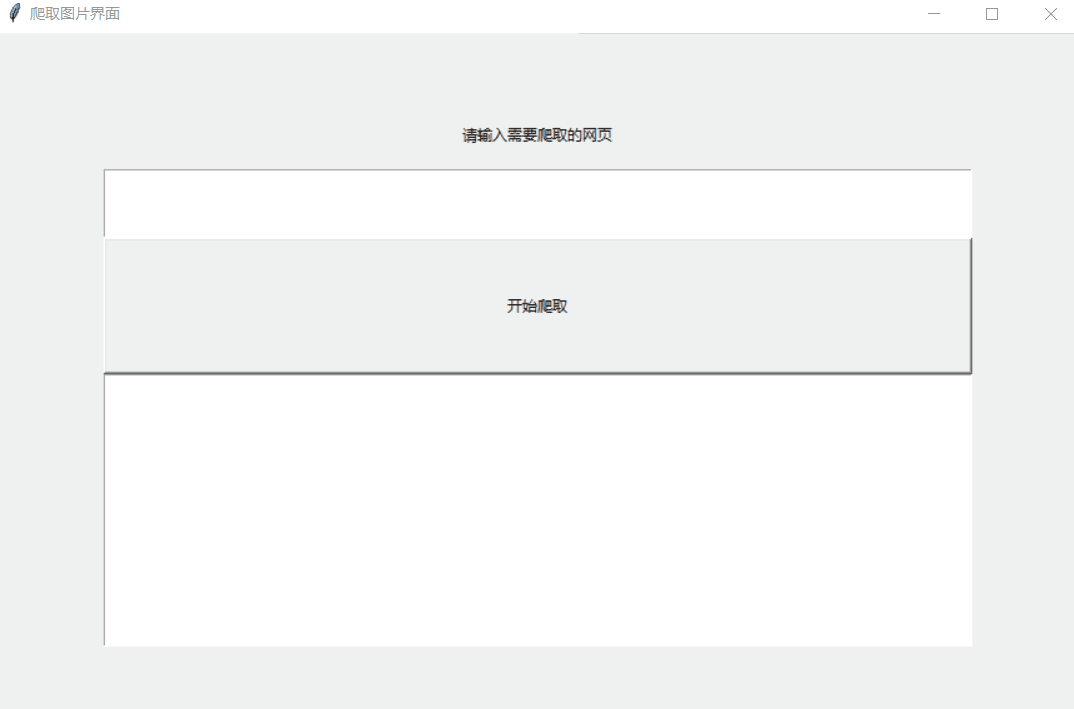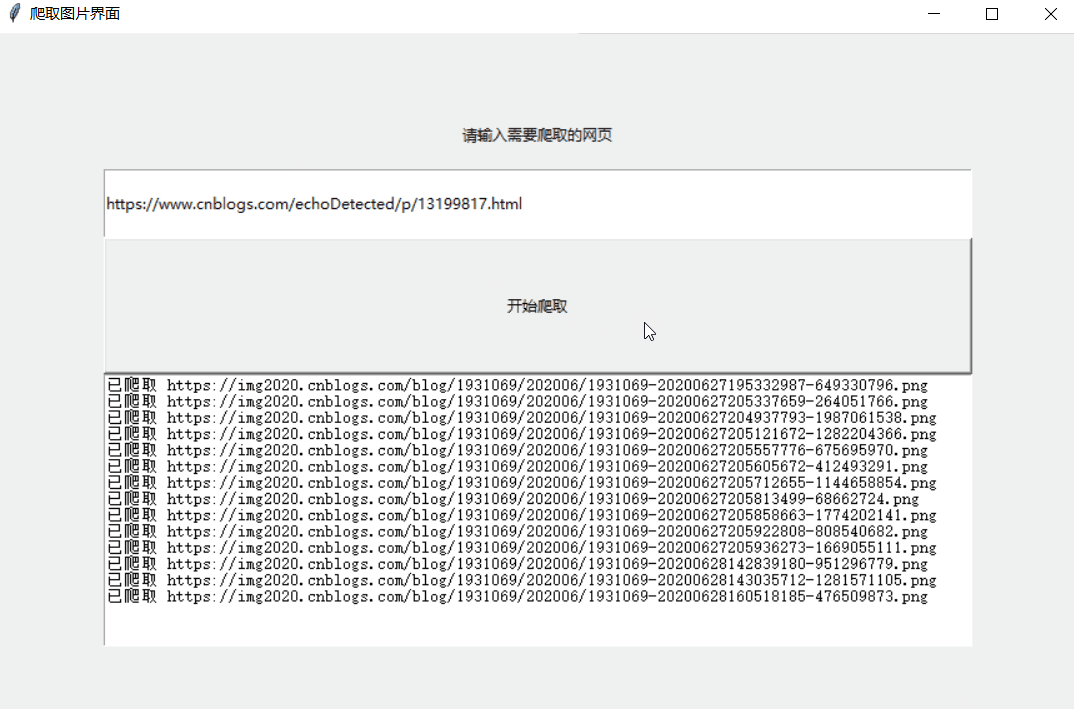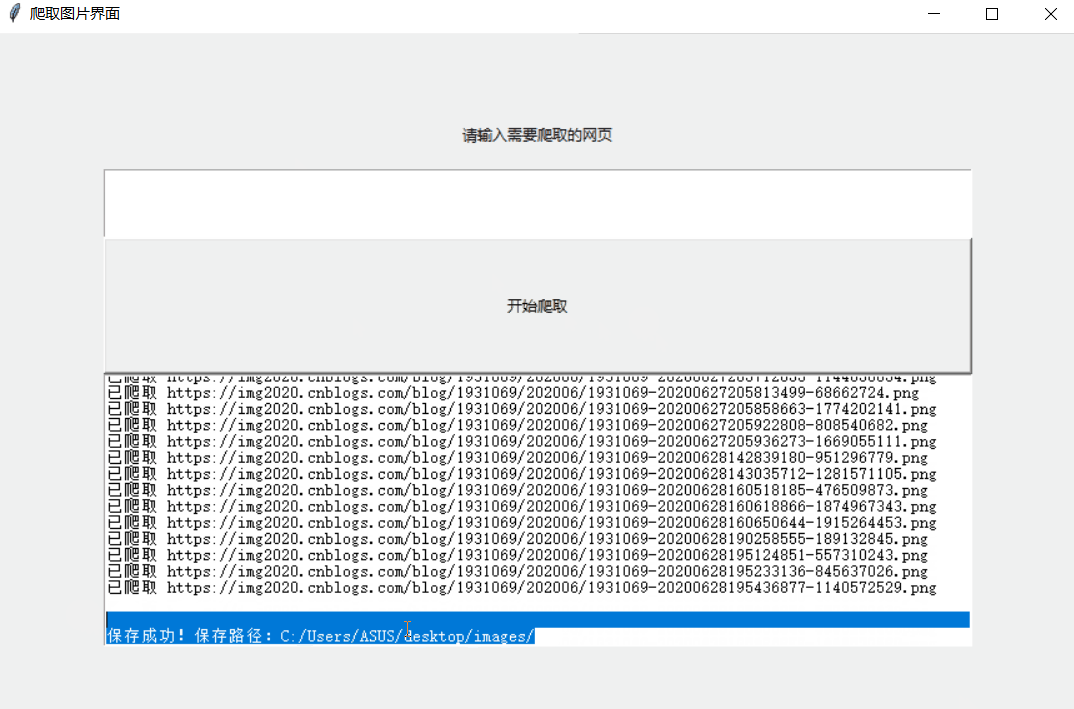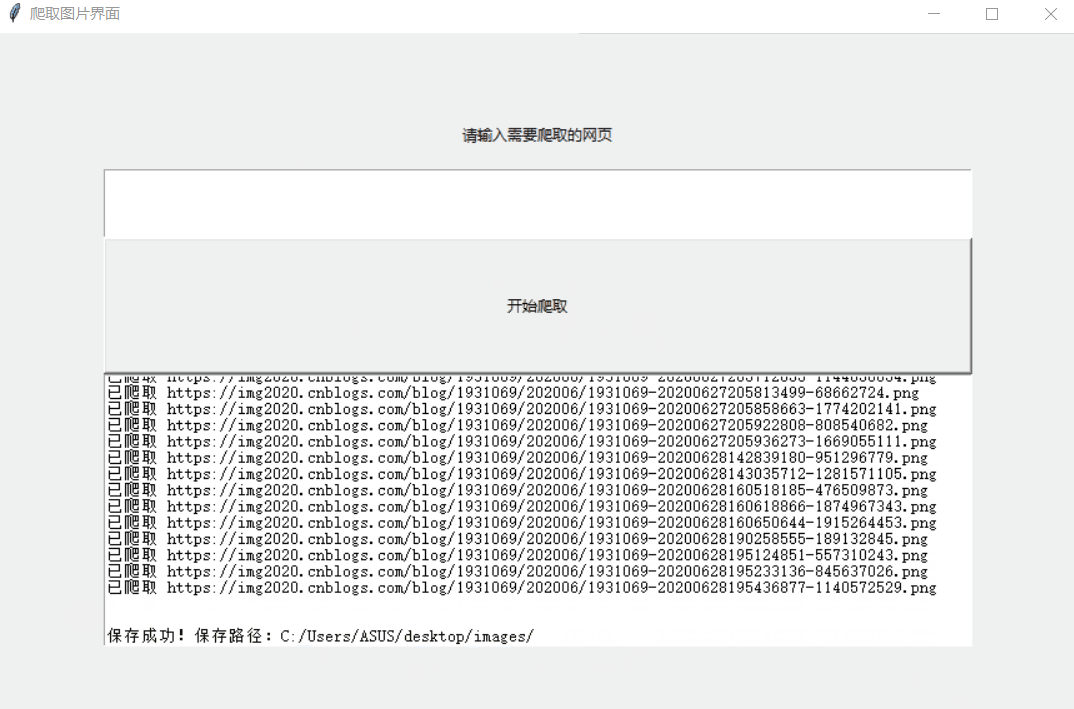
from tkinter import * from urllib.request import urlopen #注意这里的写法urllib不能直接写为import urllib要加上它的对象request from bs4 import BeautifulSoup import re import time import urllib.request def input1(): url = str(inp1.get()) html = urllib.request.urlopen(url).read().decode('utf-8') soup = BeautifulSoup(html, 'html.parser') # 是指定Beautiful的解析器为“html.parser”还有BeautifulSoup(markup,“lxml”)BeautifulSoup(markup, “lxml-xml”) BeautifulSoup(markup,“xml”)等等很多种 # 用Beautiful Soup结合正则表达式来提取包含所有图片链接(img标签中,class=**,以.png结尾的链接)的语句 # find()查找第一个匹配结果出现的地方,find_all()找到所有匹配结果出现的地方 # re模块中包含一个重要函数是compile(pattern [, flags]) ,该函数根据包含的正则表达式的字符串创建模式对象。可以实现更有效率的匹配。 links = soup.find_all('img', "", src=re.compile('.*(.jpg|.png|.jpeg)$')) # 设置保存图片的路径,否则会保存到程序当前路径 path = r'C:/Users/ASUS/desktop/images/' # 路径前的r是保持字符串原始值的意思,就是说不对其中的符号进行转义 for link in links: # 使用attrs 获取标签属性 # 保存链接并命名,time.time()返回当前时间戳防止命名冲突 # urlretrieve()方法直接将远程数据下载到本地 # urlretrieve(url, filename=None, reporthook=None, data=None) urllib.request.urlretrieve(link.attrs['src'],path + '\%s.png' % time.time()) # 使用request.urlretrieve直接将所有远程链接数据下载到本地 txt.insert(END, '已爬取 '+link.attrs['src']+'\n') txt.update() txt.insert(END,'\n'+'\n')# 文本最后插入 txt.insert(END, '保存成功!保存路径:'+path) inp1.delete(0, END) root = Tk() root.geometry('460x240') root.title('爬取图片界面') lb1 = Label(root, text='请输入需要爬取的网页') lb1.place(relx=0.1, rely=0.1, relwidth=0.8, relheight=0.1) inp1 = Entry(root) inp1.place(relx=0.1, rely=0.2, relwidth=0.8, relheight=0.1) # 方法 btn1 = Button(root, text='开始爬取', command=input1) btn1.place(relx=0.1, rely=0.3, relwidth=0.8, relheight=0.2) txt = Text(root) txt.place(relx=0.1, rely=0.5,relwidth=0.8, relheight=0.4) root.mainloop()
追加txt.update(),实时更新输出内容
原理:爬取页面img元素内所有以jpg,png,jpeg结尾的图片,暂时无法爬取gif图片,通过request.urlretrieve将远程链接数据下载到本地
效果:

[Sign]做不出ctf题的时候很痛苦,你只能眼睁睁看着其他人领先你

 浙公网安备 33010602011771号
浙公网安备 33010602011771号