Spring Data JPA之Derived query
一、Derived Query
Derived query的前缀定义可以在PartTree类找到,
package org.springframework.data.repository.query.parser; public class PartTree implements Streamable<OrPart> { // ... private static final String QUERY_PATTERN = "find|read|get|query|stream"; private static final String COUNT_PATTERN = "count"; private static final String EXISTS_PATTERN = "exists"; private static final String DELETE_PATTERN = "delete|remove"; // ... }
1、exists前缀
// exists避免了代码中丑陋的ifn操作 boolean exists = repository.existsById(searchId)
2、count前缀
// 使用JPQL @Query(" select count(t) from FollowerInfo t where investUserId = :invUserId") Integer findFollowerNumberByInvUserId(@Param("invUserId") Long invUserId); // 使用count前缀的命名查询 Long countByInvestUserId(Long investUserId);
注意:根据方法名解析的count查询也存在一些限制,首先是它的支持格式,
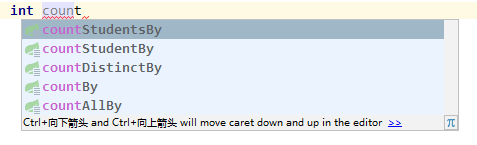
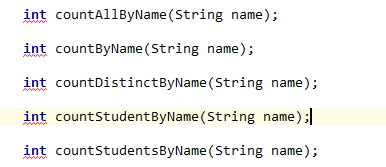
// 除了countDistinctByName其他4个方法对应的sql均为: select count(student0_.id) as col_0_0_ from student student0_ where student0_.name=? // countDistinctByName对应的sql为: select distinct count(distinct student0_.id) as col_0_0_ from student student0_ where student0_.name=? // 也就是无论By后面的是哪个字段,count的对象都是id。所以某些需求就无法通过方法名解析实现,例如,获取唯一的名字个数 select count(distinct name) from student; // 此时,你只能使用JPQL或者原生SQL实现你的查询需求。
2、stream和Pageable可以优化程序的内存占用(类似Python的生成器)
public interface UserRepository extends JpaRepository<User, Integer> { // ... Page<User> findAll(Pageable pageable); // ... } public interface UserRepository extends JpaRepository<User, Integer> { // ... Stream<User> findAllByName(String name); // ... }
3、Optional可以有效解决Null值问题
public interface UserRepository extends JpaRepository<User, Integer> { Optional<User> findOneByName(String name); }
4、相关链接:
https://www.baeldung.com/spring-data-exists-query
https://www.baeldung.com/spring-data-java-8
http://knes1.github.io/blog/2015/2015-10-19-streaming-mysql-results-using-java8-streams-and-spring-data.html
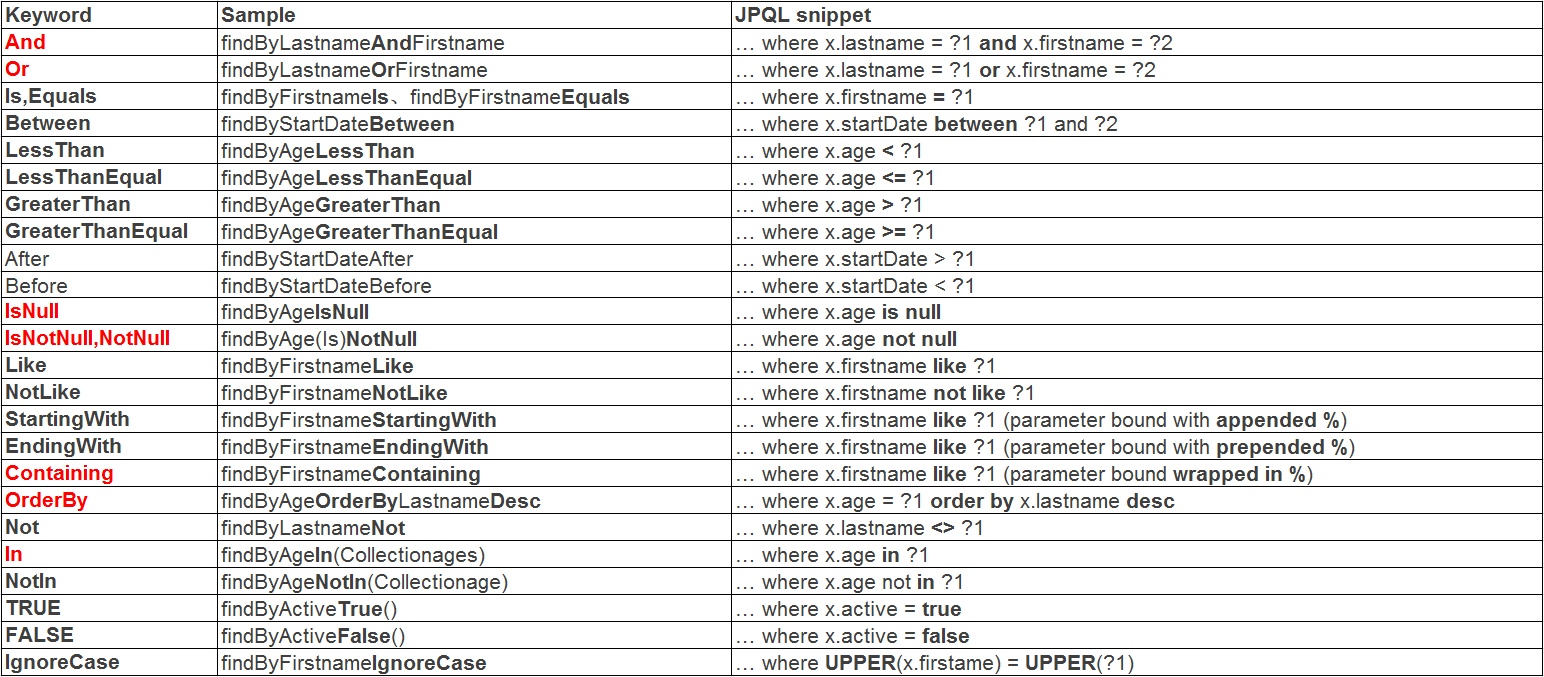
方法名中支持的关键字

 浙公网安备 33010602011771号
浙公网安备 33010602011771号