kafka监控之topic的lag情况监控
需求描述:lag(滞后)是kafka消费队列性能监控的重要指标,lag的值越大,表示kafka的堆积越严重。本篇文章将使用python脚本+influxdb+grafana的方式对kafka的offset、logsiz和lag这三个参数进行监控,并以图形化的方式进行展现。
架构描述:使用python收集kafka的相关信息并存储到influxdb里;配置grafana,将influxdb里的数据以图形化的方式展现出来。
一,准备工作
1,kafka,influxdb,grafana的安装(在此不详细描述,默认为阅读文章的各位对这三样工具的使用是熟悉的)
2,查询kafka消费状态的命令/kafka_2.11-0.10.1.0/bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group group1 --topic topicname1 --zookeeper zoo1:2181,zoo2:2181,zoo3:2181,zoo4:2181,zoo5:2181。本篇文章也将以此条命令输出的信息作为基础编写脚本。
#/kafka_2.11-0.10.1.0/bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group group1 --topic topicname1 --zookeeper zoo1:2181,zoo2:2181,zoo3:2181,zoo4:2181,zoo5:2181 Group Topic Pid Offset logSize Lag Owner group1 topicname1 0 978337806 978390228 52422 none group1 topicname1 1 978337840 978390295 52455 none group1 topicname1 2 978263557 978316052 52495 none group1 topicname1 3 978307075 978359597 52522 none group1 topicname1 4 978337803 978390358 52555 none group1 topicname1 5 978337812 978390394 52582 none
说明:
group1 组名
topicname1 topic名
我们要用脚本取的,就是输出的这段内容的Offset logSize Lag这三个值,并将所有分片的这些值相加,从而获取单个topic的Offset logSize Lag的值,并将值输出到一个txt文件暂存。我这里使用一个shell脚本来取数据和一个python脚本来讲数据存储到influxdb中的方式来实现。
二,编写脚本提取Offset logSize Lag这三个值
1,给脚本创建一个独立的目录,里面会存放脚本和临时文件。
mkdir /usr/monitor
cd /usr/monitor
mkdir tmp
2,vim topic-collect.sh
#!/bin/bash #txt文件命名规则:组-topic名字-检查项名字 source /etc/profile /kafka_2.11-0.10.1.0/bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group group1 --topic topicname1 --zookeeper zoo1:2181,zoo2:2181,zoo3:2181,zoo4:2181,zoo5:2181 | awk '{print $4}' | grep -v Offset | awk '{sum+=$1}END{print sum}' > /usr/monitor/tmp/topic-group1-topicname1-Offset.txt /kafka_2.11-0.10.1.0/bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group group1 --topic topicname1 --zookeeper zoo1:2181,zoo2:2181,zoo3:2181,zoo4:2181,zoo5:2181 | awk '{print $5}' | grep -v logSize | awk '{sum+=$1}END{print sum}' > /usr/monitor/tmp/topic-group1-topicname1-logSize.txt /kafka_2.11-0.10.1.0/bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group group1 --topic topicname1 --zookeeper zoo1:2181,zoo2:2181,zoo3:2181,zoo4:2181,zoo5:2181 | awk '{print $6}' | grep -v Lag | awk '{sum+=$1}END{print sum}' > /usr/monitor/tmp/topic-group1-topicname1-Lag.txt
其中txt是用来存储计算各分片之和的值的文件。对TXT文件名进行规范化管理会让后期增加监控十分方便清晰。
3,vim kafka-lag-collect.py #这是一个python写的脚本,用来将数据存储到influxdb中,在此之前在influxdb中建立对应的库,在这里用到的库的名称是elkDB
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import time
import urllib2
import urllib
import json
#Read the file
f = open('/usr/monitor/tmp/topic-group1-topicname1-Offset.txt')
Offset_sum = f.read()
f.close()
f = open('/usr/monitor/tmp/topic-group1-topicname1-logSize.txt')
logSize_sum = f.read()
f.close()
f = open('/usr/monitor/tmp/topic-group1-topicname1-Lag.txt')
Lag_sum = f.read()
f.close()
dbreqdata = "group1,topic=topicname1,type=Offset value="+str(Offset_sum)+\
"\ngroup1,topic=topicname1,type=logSize value="+str(logSize_sum)+\
"\ngroup1,topic=topicname1,type=Lag value="+str(Lag_sum)
print dbreqdata
dbrequrl = "http://127.0.0.1:8086/write?db=elkDB"
dbreq= urllib2.Request(url = dbrequrl,data =dbreqdata)
print dbreq
urllib2.urlopen(dbreq)
4,脚本写完后给脚本增加一下可执行权限
chmod +x kafka-lag-collect.py
chmod +x topic-collect.sh
5,试着执行一下topic-collect.sh看能否执行成功
./topic-collect.sh
如果能执行成功的话,可以看到/usr/monitor/tmp/topic-group1-topicname1-Offset.txt里面已经有计算出来的offset总和了
6,试着执行一下kafka-lag-collect.py看能否执行成功
./kafka-lag-collect.py
如果能执行成功的话,就可以在influxdb里看到新建的表和相关数据了。
7,让topic-collect.sh脚本调用kafka-lag-collect.py脚本,这样可以避免添加两条crontab定时任务
echo "/usr/monitor/kafka-lag-collect.py" >> topic-collect.sh
8,添加定时任务,让脚本可以每分钟收集一次信息到influxdb
crontab -e
* * * * * /usr/monitor/topic-collect.sh
三,配置grafana展现数据
1,配置grafana数据源

2,新建图表
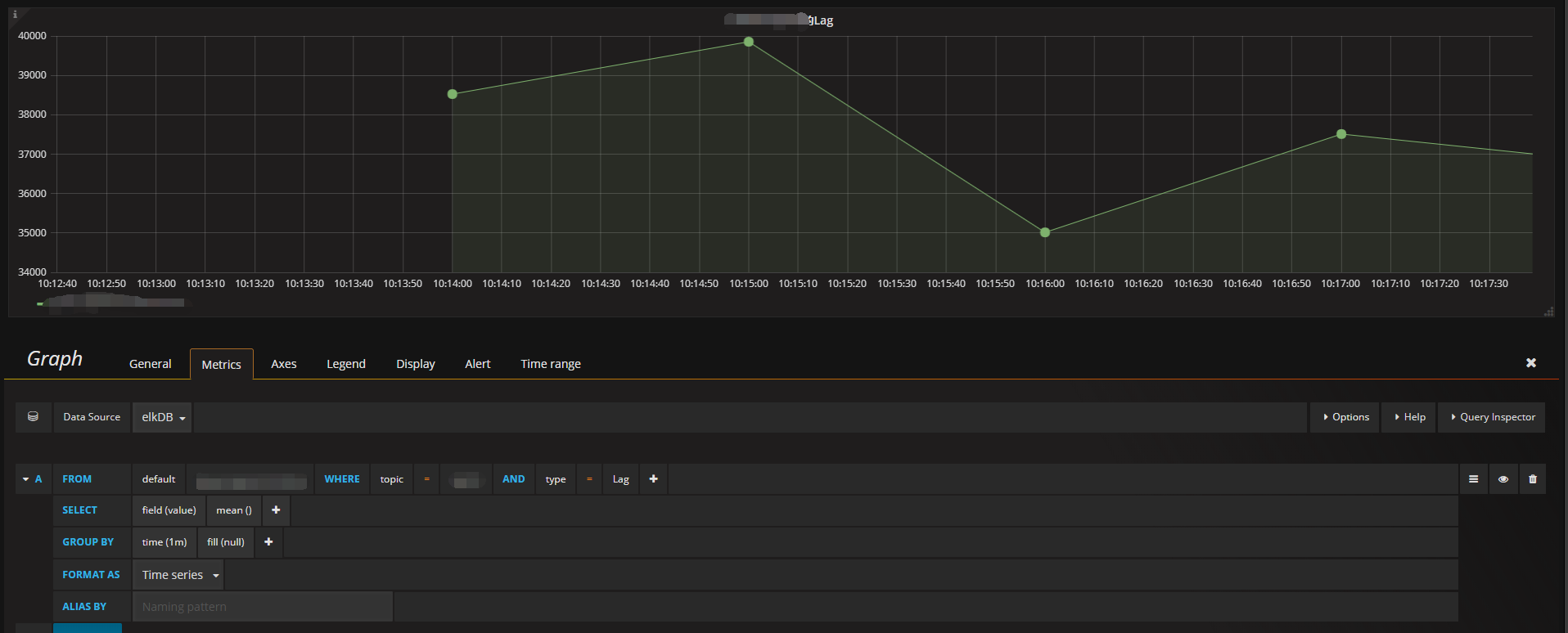
至此,就可以在grafana上看到监控的lag状态了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号