【算法题】LeetCode刷题(四)
数据结构和算法是编程路上永远无法避开的两个核心知识点,本系列【算法题】旨在记录刷题过程中的一些心得体会,将会挑出LeetCode等最具代表性的题目进行解析,题解基本都来自于LeetCode官网(https://leetcode-cn.com/),本文是第四篇。
1.组合总和(原第39题)
给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
说明:
所有数字(包括 target)都是正整数。
解集不能包含重复的组合。
示例:
输入:candidates = [2,3,5], target = 8,
所求解集为:
[
[2,2,2,2],
[2,3,3],
[3,5]
]
(1)知识点
回溯法
(2)解题方法
方法:回溯+剪枝
回溯法本质就是一棵树,通过列举所有可能的情况,然后排出不符合要求的情况,见下图:
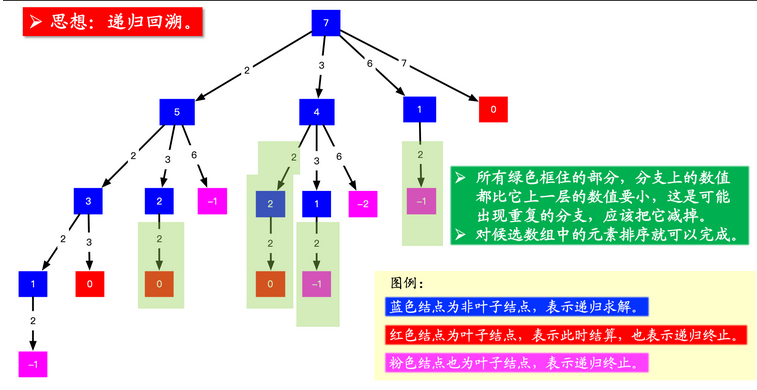
这张图展示了回溯法的解题过程,其中,因为不能出现重复数组,所以所有分支比上一个分支小的分支都得剪掉(这样就达到了去重的目的)。剩下的事情就是遍历这棵树了(深度优先)
(3)伪代码
函数头:List<List
方法:回溯+剪枝
- 对candidates进行排序
- 调用dfs
定义dfs(int[] candidates, int len, int target, int begin, Deque
- 如果target=0,将path(必须new一个)添加到res里面
- 否则,执行下列循环(i:begin->len-1)
- 如果target-candidates[i]<0,直接跳出循环
- 否则将candidates[i]加到path后面
- 继续调用自己将更新后的变量传入dfs
- 递归完后需要将path最后一位去掉(回溯的本质)
(4)代码示例
public List<List<Integer>> combinationSum(int[] candidates, int target) {
Arrays.sort(candidates);
List<List<Integer>> res = new ArrayList<>();
backtrack(candidates, candidates.length, target, 0, new ArrayList(), res);
return res;
}
private void backtrack(int[] candidates, int len, int target, int begin, List path, List<List<Integer>> res){
if(target == 0) {
res.add(new ArrayList(path));
}
int tmp = 0;
for(int i = begin; i < len; ++i){
tmp = candidates[i];
if(target - tmp < 0) break;
path.add(tmp);
backtrack(candidates, len, target - tmp, i, path, res);
path.remove(path.size() - 1);
}
}
2.旋转图像(原第48题)
给定一个 n × n 的二维矩阵表示一个图像。
将图像顺时针旋转 90 度。
说明:
你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要使用另一个矩阵来旋转图像。
示例:
给定 matrix =
[
[1,2,3],
[4,5,6],
[7,8,9]
],
原地旋转输入矩阵,使其变为:
[
[7,4,1],
[8,5,2],
[9,6,3]
]
(1)知识点
矩阵变换
(2)解题方法
方法转自:https://leetcode-cn.com/problems/rotate-image/solution/xuan-zhuan-tu-xiang-by-leetcode/
方法:转置+翻转
最直接的想法是先转置矩阵,然后翻转每一行。这个简单的方法已经能达到最优的时间复杂度O(N^2)。原解答还有另外两种旋转的方法,虽然理解不难,但是容易写错,浪费时间,所以还是这个最厉害了。
- 时间复杂度:O(N^2)。
- 空间复杂度:O(1)O(1) 由于旋转操作是 就地 完成的。
(3)伪代码
函数头:void rotate(int[][] matrix)
方法:转置+翻转
- 第一次第一重循环:转置矩阵(i:0->n-1)
- 第一次第二重循环:(j->n-1)
- 交换第i行j列和j行i列的值
- 第一次第二重循环:(j->n-1)
- 第一次第一重循环:(横向)翻转矩阵(i:0->n-1)
- 第一次第二重循环:(j->n-1)
- 交换j列n-j-1列的值
- 第一次第二重循环:(j->n-1)
(4)代码示例
public void rotate(int[][] matrix) {
int len = matrix.length;
//转置
for(int i = 0; i < len; ++i){
for(int j = i + 1; j < len; ++j){
int temp = matrix[i][j];
matrix[i][j] = matrix[j][i];
matrix[j][i] = temp;
}
}
//翻转
for(int i = 0; i < len / 2; ++i){
for(int j = 0; j < len; ++j){
int temp = matrix[j][i];
matrix[j][i] = matrix[j][len-1-i];
matrix[j][len-1-i] = temp;
}
}
}
3.字母异位词分组(原第49题)
给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
示例:
输入: ["eat", "tea", "tan", "ate", "nat", "bat"]
输出:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]
(1)知识点
哈希表
(2)解题方法
方法转自:https://leetcode-cn.com/problems/group-anagrams/solution/zi-mu-yi-wei-ci-fen-zu-by-leetcode/
方法一:按排序数组分类
当且仅当它们的排序字符串相等时,两个字符串是字母异位词。
- 时间复杂度:O(NKlogK),其中 N 是 strs 的长度,而 K 是 strs 中字符串的最大长度。当我们遍历每个字符串时,外部循环具有的复杂度为 O(N)。然后,我们在 O(KlogK) 的时间内对每个字符串排序。
- 空间复杂度:O(NK),排序存储在 ans 中的全部信息内容。
方法二:按照字母计数分类(非常精妙)
当且仅当它们的字符计数(每个字符的出现次数)相同时,两个字符串是字母异位词。
- 时间复杂度:O(NK),其中 N 是 strs 的长度,而 K 是 strs 中字符串的最大长度。计算每个字符串的字符串大小是线性的,我们统计每个字符串。
- 空间复杂度:O(NK),排序存储在 ans 中的全部信息内容。
(3)伪代码
函数头:List<List
方法一:按排序数组分类
- 定义一个HashMap<String, List
> res,用于存储每个排好序的字符串的所有源字符串 - 第一重循环:i:0->strs.len
- 将strs[i].toArray(),然后sort,然后组合成串s
- map添加这个s(key)和strs[i](value)(如果不存在这个key需要新增一个key和value(ArrayList)
- 注意最后返回的方法:return new ArrayList(res.values())
方法二:按照字母计数分类
- 定义一个HashMap<String, List>res目的和上个方法相同
- 定义一个数组int[] arr = new int[26],用于存放每个字母出现的频率
- 第一重循环:i:0->strs.len
- 数组归零:Arrays.fill(arr, 0)
- 重点步骤:遍历strs[i]的所有字符(char c : strs[i].toCharArray()),arr[c-'a']++,这一步骤就是计算当前的单词每一个字母的数量,堪称神迹
- 将这个strs[i]存到map里面,这个地方需要将arr转化成字符串,这里采用一个方法,由于arr里面存储方式是这样的"abbcc"->[1,2,2,0,...,0],我们将它变成这样->"#1#2#2#0...#0",这样能保证键的唯一性
- 将上一步生成的字符串作为键,同样看它是否存在,接下来的步骤和前一个方法相同
(4)代码示例
//排序数组
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<String, List> map = new HashMap<>();
char [] ch;
String key;
for(String str : strs){
ch = str.toCharArray();
Arrays.sort(ch);
key = String.valueOf(ch);
if(!map.containsKey(key)) map.put(key, new ArrayList());
map.get(key).add(str);
}
return new ArrayList(map.values());
}
//字符计数
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<String, List> map = new HashMap<>();
StringBuilder key = new StringBuilder();
String key1;
for(String str : strs){
int [] arr = new int[26];
key.delete(0, key.length());
for(int i = 0; i < str.length(); ++i){
++arr[str.charAt(i) - 'a'];
}
for(int i = 0; i < 26; ++i){
key.append(arr[i]);
key.append("#");
}
key1 = key.toString();
if(!map.containsKey(key1)) map.put(key1, new ArrayList());
map.get(key1).add(str);
}
return new ArrayList(map.values());
}
4.Pow(x, n)(原第50题)
实现 pow(x, n) ,即计算 x 的 n 次幂函数。
示例:
输入: 2.00000, 10
输出: 1024.00000
说明:
-100.0 < x < 100.0
n 是 32 位有符号整数,其数值范围是 [−2^31, 2^31 − 1] 。
(1)知识点
快速幂
(2)解题方法
方法转自:https://leetcode-cn.com/problems/powx-n/solution/powx-n-by-leetcode-solution/
方法一:快速幂 + 递归
快速幂听起来复杂,其实很常见,在计算x^64时,如果不做任何处理,肯定就是循环将x乘64次,那么快速幂就会这样操作:
x->x2->x4->x8->x16->x32->x64
将每一项平方得到后一项,这样做6次就能得到结果,再来看x^53
x->x3->x6->x13->x26->x^53
这也能快速计算出结果,无非就是平方后再乘个x,或者不乘,那么问题就在于什么是乘呢?其实倒过来看就行了:
53变26只需要除以二再取整就可以,那么以此类推就能最终推到1那个地方,所以这种逆序的计算可以用递归来实现。
- 时间复杂度:O(logn),即为递归的层数。
- 空间复杂度:O(logn),即为递归的层数。这是由于递归的函数调用会使用栈空间。
方法二:快速幂+迭代
有递归的地方一般就可以有迭代,迭代使用循环代替了递归的过程,在本题中,快速幂的理念不变,只是操作的方法变化了一些,原答案讲解的很详细,但是我觉得要写出代码来不需要想那么多

- 时间复杂度:O(logn),即为对 n 进行二进制拆分的时间复杂度。
- 空间复杂度:O(1)。
(3)伪代码
函数头:double myPow(double x, int n)
方法一:快速幂 + 递归
- 如果n>=0,调用quickMul(x, n),否则调用1/quickMul(x,-n)
quickMul(double x, long n):
- 如果n=0,返回1.0——递归终止条件
- 递归y=quickMul(x, n / 2)
- 如果n%2=0,说明不需要额外乘以x,直接返回yy,否则返回yy*x
方法二:快速幂+迭代
- 如果n>=0,调用quickMul(x, n),否则调用1/quickMul(x,-n)
quickMul(double x, long n):
- 定义结果res=1.0
- 定义初始贡献值y=x
- 第一重循环(n>0):
- 如果n%2!=0,res*y
- y*=y
- n/=2
(4)代码示例
public double myPow(double x, int n) {
long ln = n;
if(n < 0){
return 1 / pow(x, -ln);
}
return pow(x, ln);
}
private double pow(double x, long n){
if(n == 0) return 1;
double y = pow(x, n / 2);
return (n % 2 == 0) ? y * y: y * y * x;
}
5.最大子序和(原第53题)
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
输入: [-2,1,-3,4,-1,2,1,-5,4]
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
(1)知识点
动态规划
(2)解题方法
方法转自:https://leetcode-cn.com/problems/maximum-subarray/solution/zui-da-zi-xu-he-by-leetcode-solution/
方法一:动态规划
动态规划在于找出状态转移方程,我们假设f(i)是以i结尾的数组的最大自序和,那么结果显然就是maxf(i),f(n)肯定是有f(n-1)得到的,那么很简单,f(n)=max(f(n-1)+a[n],a[n])
- 时间复杂度:O(n),其中 n 为 nums 数组的长度。我们只需要遍历一遍数组即可求得答案。
- 空间复杂度:O(1)。我们只需要常数空间存放若干变量。
方法二:分治法(暂不考虑,比动态规划复杂)
(3)伪代码
函数头:int maxSubArray(vector
方法一:动态规划
- 定义记录前一个状态的结果pre和最大值maxRes
- 第一重循环:(i:0->len-1)
- pre=max(pre+x,x)
- maxRes=max(maxAns,pre)
方法二:分治法(暂不考虑,比动态规划复杂)
(4)代码示例
public int maxSubArray(int[] nums) {
int len = nums.length;
if(len == 0) return 0;
int tmp = nums[0];
int max = tmp;
for(int i = 1; i < len; ++i){
tmp = Math.max(nums[i], tmp+ nums[i]);
max = Math.max(tmp, max);
}
return max;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号