

第三次大作业
作业①
-
要求
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后4位)
-
输出
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
-
思路
检查网页发现图片都在"img"标签下,抽取出src属性即可获得图片的链接,网站翻页我选择一种暴力的手段,预先把网页url存进web_url_list这个列表,后续直接遍历访问
-
过程
码云地址:https://gitee.com/eat-watermelon-bu/crawl_project/tree/master/%E7%AC%AC%E4%B8%89%E6%AC%A1%E5%A4%A7%E4%BD%9C%E4%B8%9A/%E4%BD%9C%E4%B8%9A%E4%B8%80
获取html中所有图片链接的函数
def getImages(html):
soup = BeautifulSoup(html, 'lxml')
pic_list = soup.find_all('img')
pic_url_list = []
for i in pic_list:
pic_url_list.append(i['src'])
return pic_url_list为了适应多线程将爬取图片封装在spide(url,file_folder)函数中,实现下载指定url中所有图片到文件夹file_folder
# 全局变量sum_pic用来控制爬取照片的数量
global sum_pic
sum_pic = 108
def spider(url, file_folder):
html = getHtml(url)
# 从网页html中抽取出所有照片的链接
img_url_list = getImages(html)
# 定义全局遍历sum_pic来控制爬取数量
global sum_pic
for url in img_url_list:
if sum_pic == 0:
break
else:
print('Downloading image No.', str(109 - sum_pic), ' now')
print(url)
img_name = file_folder + str(109 - sum_pic) + '.jpg'
urllib.request.urlretrieve(url, filename=img_name)
sum_pic = sum_pic - 1
sum_pic = sum_pic单线程main()函数
def main():
# 学号108,爬8页108张
# 不同网页的图片放在不同的文件夹之中
for i in range(len(web_url_list)):
file = 't'+ str(i+1)
if not os.path.exists(file):
os.mkdir(file)
file_folder = './t' + str(i+1) + '/'
spider(web_url_list[i],file_folder)多线程和单线程只是主函数不同,多线程中,主函数启动不同参数的spider线程实现对不同网页同时爬取
多线程main()函数
def main():
# 学号108,爬8页108张
# 创建线程列表,列表中每个线程负责一个网页的爬取
threads = []
for i in range(len(web_url_list)):
file = 'mt' + str(i + 1)
if not os.path.exists(file):
os.mkdir(file)
# 不同线程爬取的图片放在不同文件夹中
file_folder = './mt' + str(i + 1) + '/'
T = threading.Thread(target=spider,args=(web_url_list[i],file_folder))
T.setDaemon(False)
threads.append(T)
for T in threads:
T.start() -
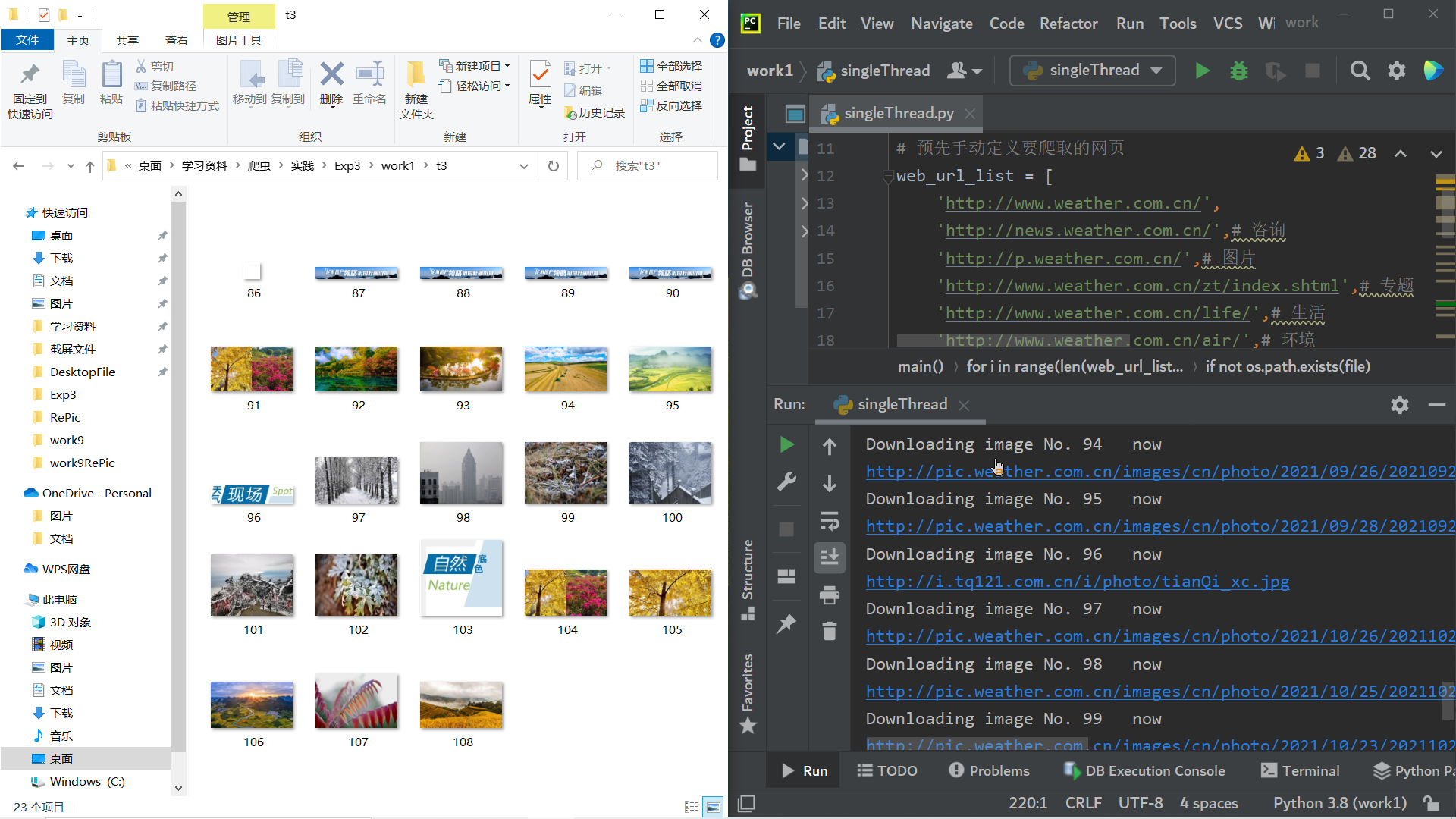
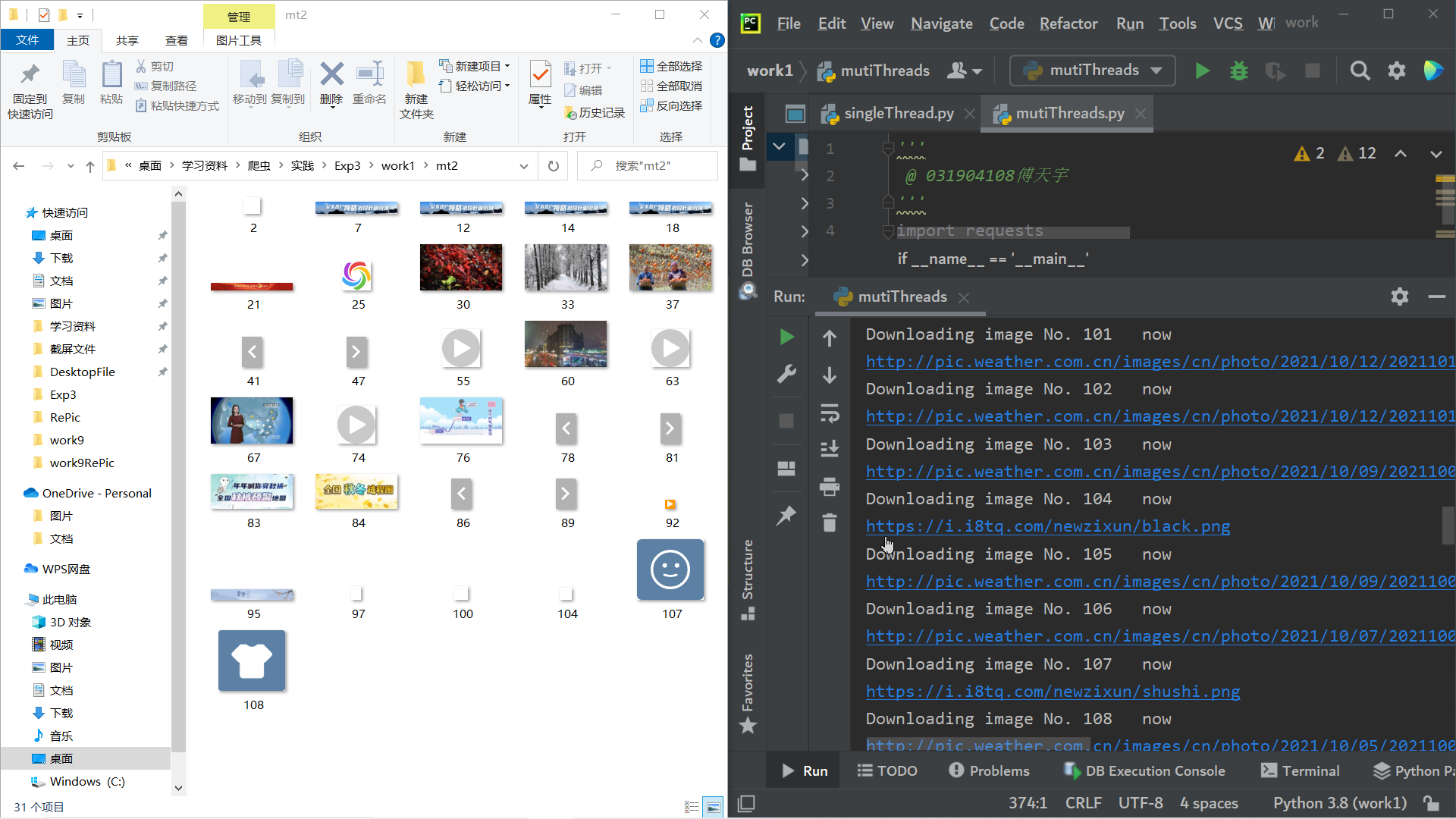
结果截图
单线程
多线程
-
心得
爬取照片难度不大,关键是如何用最少的工作量实现单线程向多线程的转化,本着OCP与LSP原则,将代码模块化,这样单线程便可以直接复用多线程的代码,毕竟单线程是多线程的特殊情况。
作业②
-
要求
使用scrapy框架复现作业①。
-
输出
同作业①
-
思路
用scrapy复现难度主要是翻页的处理。
在spider类中定义一个web_url_list用来存放所有网页url,再通过下标索引访问网页web_url_list[page]为当前爬取页面的url,page记录当下页数,每爬完一页page就自加1,以此方式迭代
-
过程
码云地址 :https://gitee.com/eat-watermelon-bu/crawl_project/upload/master/%E7%AC%AC%E4%B8%89%E6%AC%A1%E5%A4%A7%E4%BD%9C%E4%B8%9A/%E4%BD%9C%E4%B8%9A%E4%BA%8C
items文件
import scrapy
class WtItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#img_url用以存放图片url
img_url = scrapy.Field()
spiders文件
class WeatherSpider(scrapy.Spider):
web_url_list = [
'http://www.weather.com.cn/',
'http://news.weather.com.cn/', # 咨询
'http://p.weather.com.cn/', # 图片
'http://www.weather.com.cn/zt/index.shtml', # 专题
'http://www.weather.com.cn/life/', # 生活
'http://www.weather.com.cn/air/', # 环境
'http://www.weather.com.cn/trip/', # 旅游
'http://www.weather.com.cn/climate/', # 生态
]
name = 'weather'
allowed_domains = ['weather.com.cn']
page = 1
url = web_url_list[page]
def start_requests(self):
yield scrapy.Request(self.url)
def parse(self, response):
img_url_list = response.xpath('//img/@src').extract()
for img_url in img_url_list:
item = WtItem()
item['img_url'] = img_url
yield item
# 翻页处理
if self.page < len(self.web_url_list)-1:
self.page += 1
# 通过page索引web_url_list来获取要爬取网页的url
yield scrapy.Request(url=self.web_url_list[self.page])
pipelines文件
class WtPipeline:
num = 1
if_end = 0 # 用来判断是否下载完毕,0代表没有下载完
def process_item(self, item, spider):
if self.num <= 108:# 控制下载的图片数量
url = item['img_url']
print('Downloading img No.'+str(self.num))
print(url)
# 没有就创建文件夹
if not os.path.exists('imgs'):
os.mkdir('imgs')
# 照片按照编号保存到文件夹imgs内
img_name = './imgs/' + str(self.num) + '.jpg'
urllib.request.urlretrieve(url, filename=img_name)
self.num += 1
else:
if self.if_end == 0:
print('108 images have been downloaded')
self.if_end = 1settings文件
BOT_NAME = 'wt'
SPIDER_MODULES = ['wt.spiders']
NEWSPIDER_MODULE = 'wt.spiders'
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
ITEM_PIPELINES = {
'wt.pipelines.WtPipeline': 300,
}
-
结果截图
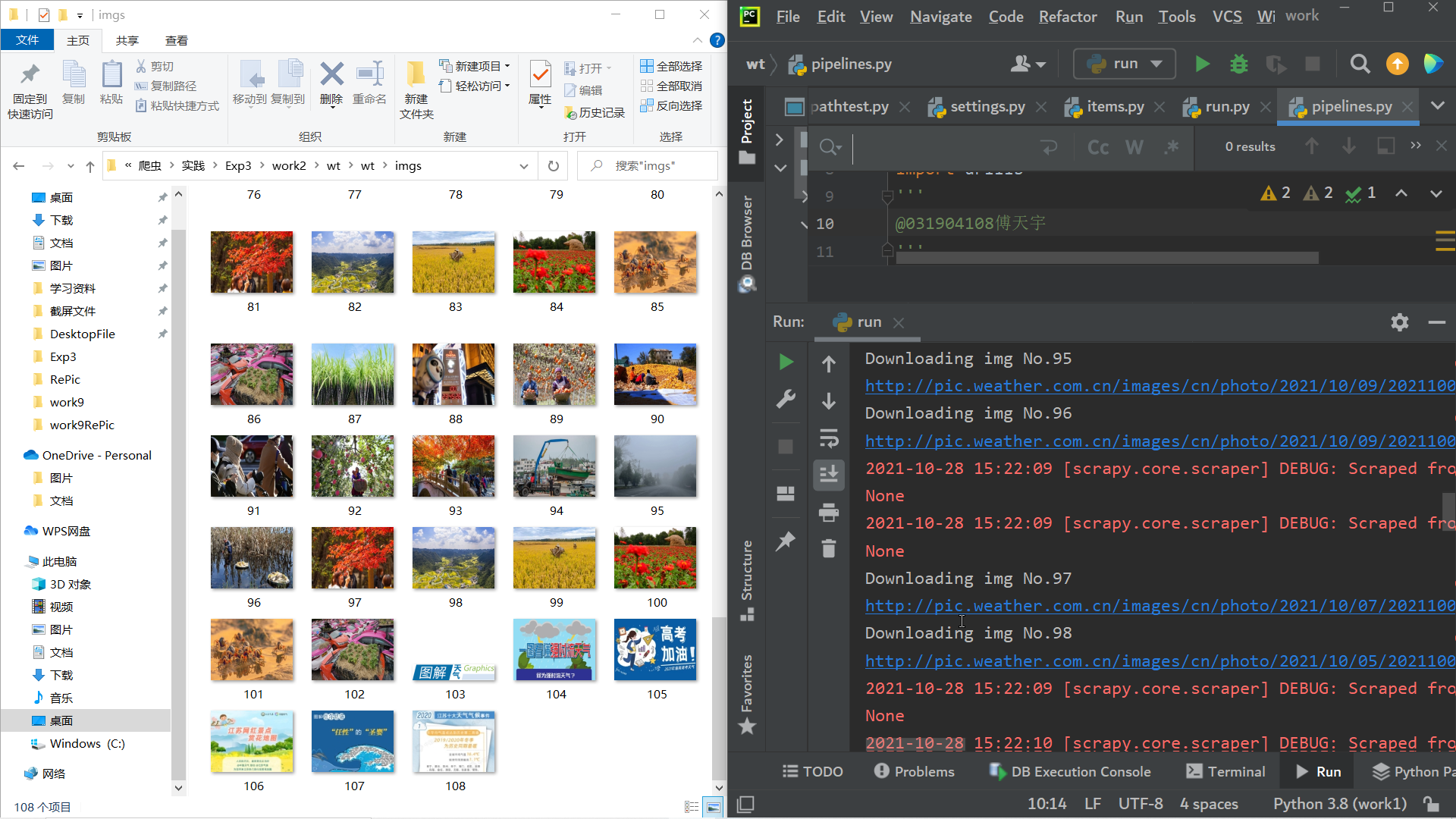
-
心得
用scrapy复现需要对框架有一定的了解,尤其是翻页处理,一开始会感觉很抽象。
在代码运行的时候会一直scrapy.core错误,虽然访问网页返回状态为200,值却是none,通过互联网查阅资料也没有解决问题,不过并不影响程序预期目标的达成
作业③
-
要求
爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在 imgs路径下。
候选网站: https://movie.douban.com/top250
-
思路
没有什么理解上的难度,直接爬取就行
-
过程
码云地址:https://gitee.com/eat-watermelon-bu/crawl_project/upload/master/%E7%AC%AC%E4%B8%89%E6%AC%A1%E5%A4%A7%E4%BD%9C%E4%B8%9A/%E4%BD%9C%E4%B8%9A%E4%B8%89
items文件
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
rank = scrapy.Field()
name = scrapy.Field()
director = scrapy.Field()
actor = scrapy.Field()
abstruct = scrapy.Field()
star = scrapy.Field()
img = scrapy.Field()spiders文件
class FilmSpider(scrapy.Spider):
name = 'film'
allowed_domains = ['douban.com']
start_urls = ['http://douban.com/']
url = 'https://movie.douban.com/top250?start=0'
def start_requests(self):
yield scrapy.Request(self.url)
def parse(self, response):
film = response.xpath('//li')
img_list = film.xpath('//img/@src').extract()
name_list = response.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[1]/a/img/@alt').extract()
abrtruct_list = response.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[2]/span/text()').extract()
star_list = response.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()').extract()
directors_actors = response.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[1]').extract()
#对导演和演员姓名提取
#导演和演员姓名处于同一个字符串中,可以用冒号‘:’分割
director_list = []
actor_list = []
for i in range(len(directors_actors)):
t = directors_actors[i] # .replace('bg','')
t = "".join(t.split())
t = t.replace(u'\xa0', '')
d_a = t.split(':')#存有导演和演员姓名的列表,2列
director = d_a[1][0:len(d_a[1]) - 2]# 提取导演姓名
actor = d_a[-1]# 提取演员姓名
director_list.append(director)
actor_list.append(actor)
for i in range(len(name_list)):
item = DoubanItem()
item['rank'] = i+1
item['name'] = name_list[i]
item['abstruct'] = abrtruct_list[i]
item['star'] = star_list[i]
item['director'] = director_list[i]
item['actor'] = actor_list[i]
item['img'] = img_list[i]
yield itempiplines文件
class filmDB:
def openDB(self):
self.con = sqlite3.connect("film.db") # 连接数据库,没有的话会注定创建一个
self.cursor = self.con.cursor() # 设置一个游标
def createTB(self):
try:
self.cursor.execute("create table films(rank varchar(10),name varchar(20),director varchar(20),actor varchar(20),abstruct varchar(50),star varchar(10),img varchar(50))")
# 创建电影表
except:
self.cursor.execute("delete from films")
def closeDB(self):
self.con.commit() # 提交
self.con.close() # 关闭数据库
def insert(self,Rank,Name,Director,Actor,Abstruct,Star,img):
try:
self.cursor.execute("insert into films(rank,name,director,actor,abstruct,star,img) values (?,?,?,?,?,?,?)", (Rank, Name, Director, Actor, Abstruct, Star, img))
# 插入数据
except Exception as err:
print(err)
class DoubanPipeline:
# 我对pipelines运行时隙不太了解,为了控制创建表格的时间
# 设立if_start来记录是否可以创建数据库表格,if_start==0表示可以创建表格
if_start = 0
def process_item(self, item, spider):
rank = item['rank']
name = item['name']
abstruct = item['abstruct']
director = item['director']
actor = item['actor']
star = item['star']
url = item['img']
film_db = filmDB()
film_db.openDB()
if self.if_start == 0:
self.if_start = 1
film_db.createTB()
print("序号\t\t电影名称\t\t导演\t\t演员\t\t简介\t\t评分\t\t电影封面")
print(rank,'\t\t',name,'\t\t',director,'\t\t',actor,'\t\t',abstruct,'\t\t',star,'./covers/'+name+'.jpg')
# fmt = "{0:^3}\t{1:^15}\t{2:^20}"
# print(fmt.format(item['rank'],item['name'],item['director']))
file = 'covers'
if not os.path.exists(file):
os.mkdir(file)
file_folder = './covers/'
img_name = file_folder + name + '.jpg'
# 下载
urllib.request.urlretrieve(url, filename=img_name)
film_db.insert(rank, name, director, actor, abstruct, star,img_name )