
Stroke filter: 一种用于OCR预处理的文字滤波器
近几个月我在一家公司的研发部做模式识别实习生,学习了很多OCR相关的知识和技术,在此谢谢陆老师,孙老师以及其它各位老师的指导,我很喜欢这里,你们让我收获了很多
OCR(Optical Character Recognition)光学字符识别是一种获取图像中的字符信息的处理技术,用通俗一点的话说,就是把带有文字信息的图像数据变成文本数据的一种技术。在我们的生活中很多地方都有它的身影,如高速路上的电子眼(车牌识别),有道词典(图像单词识别)等等。
OCR的识别过程大致有以下几个步骤:字符检测,去噪,倾斜校正,版面分析,文字切割,字符识别,修正,后处理等。Stroke filter 正是一种用于OCR预处理去噪的滤波器,它能够滤除图像中那些文字特征不明显的部分,而保留那些文字较明显的部分。它是字符检测和背景去噪的一种常用方法。
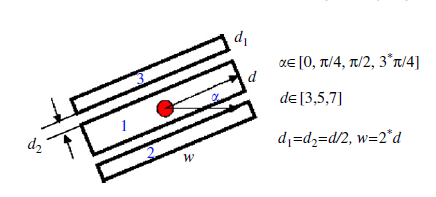
Stroke filter的定义很简单:
首先定义stroke响应,对于一个给定的角度alpha和距离参数d(上图), 一个像素点的响应response(此处用小r表示)为:
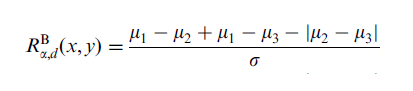
其中u1,u2,u3表示1号2号3号矩形内的像素和, 分母是正比于1号矩形内像素方差分布的一个参数,B表示bright,即白底黑字的情况。从直观上来看,如果当前像素点(x,y)为笔划像素点时,1号矩形的像素和与2号3号矩形的像素和之差会比较大,2号和3号矩形像素和之差会较小,因此response会在笔划像素点的位置达到极大值。但是这个值会因为当前笔划的方向和字体大小有所不同,这时就需要调整alpha和d来寻找这个最大值。
下面的任务就是要找出这个最大值了,如下图第一行所示(后两行不用看,是为了后续svm分类用的,具体内容可以看这篇paper),一个像素点的Response(此处用大R表示)值为:在所有的alpha,d的可能取值所对应的response的集合中,最大的一个r值,即为该像素点的R。可以想像,这种滤波器很符合文字的纹理特点,文字都是由条状的笔划组成,一张图片如果含有文字,则文字笔划处的Response会比较大,其它地方的Response会较小,利用这一特点就可以把文字滤出来了。
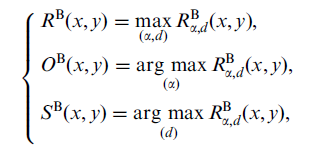
以下是部分实验结果:
首先是输入图像:

Response:

二值化:

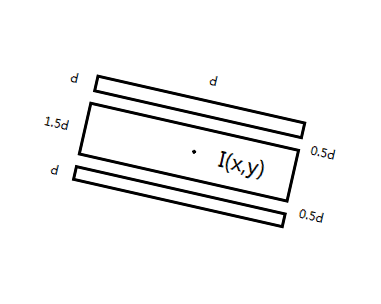
注意到文章中的参数比较死板,效果不是太好,在我的实验中,一组较合理的参数如下图所示
d=1,2,3,4, alpha interval = 45度,其中stroke的长度不要超过两倍的d,不然文字边界的response会出现振铃效应
速度方面,上面的测试图长宽为722 * 535 pixels ,在我的i5小黑上跑,大概1300ms, 环境是windows,x64,opencv, c++。影响速度最重要的参数是alpha的选取,每隔45度计算一个response和每隔10度计算一个response在精度上不会有太大差别,同样地,如果alpha interval设为90也不会损失太多的精度,而速度却可以降到600ms。如果想要做实时视频处理的话,最好先把字幕所在矩形提取出来,然后在处理,这样的话速度可以保证在50ms以内。

