面试题
jvm问题及调优
java跨平台怎么实现的?(一次编写到处运行)
java文件通过javac编译成class文件后,通过在不同平台的jvm(java虚拟机)生成不同平台的机器码,就能在不同平台运行。
jvm虚拟机 类加载过程(加载、验证、准备、解析、初始化、使用和卸载)
类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括:加载、验证、准备、解析、初始化、使用和卸载7个阶段。
其中验证、准备、解析3个部分统称为连接。
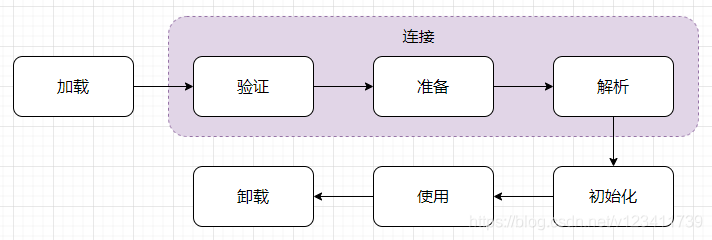
加载:类加载器加载唯一的class文件进入jvm中。
验证:验证class文件中内容是否符合规范,不规范jvm无法正常运行
准备:给类在栈中的局部变量表中的变量 赋予内存空间和初始值(零值)
解析:动态链接,把符号引用替换为直接引用,在方法区找到调用方法的位置
初始化:给栈中的变量赋值 与 给堆中创建实例对象,执行静态代码块
jvm虚拟机 4种类加载器(启动,扩展,应用,自定义)
什么时候加载类:什么时候使用到了这个类,它就去class字节码文件中去加载这个类。
类加载器作用:确定唯一类进行加载,JVM将指定的class文件读取到内存里,并运行该class文件里的Java程序,
启动类加载器:加载jvm核⼼类库,如java.lang.*等,由C++语言编写,无法通过java代码.parent()得到
扩展类加载器:(ext)从jre/lib/ext下加载类库,基本API之外的一些拓展类,包括一些与安全性能相关的类。
应用程序加载器:保存在项目路径下,自己写的java代码中使用的类
自定义类加载器:这是开发人员通过拓展ClassLoader类定义的自定义加载类,加载程序员定义的一些类。
用途:1.用于加载解密(被加密的class文件),2.加载未在项目路径下的class文件,3.将非class文件转为class文件并加载
自定义一个类加载器,需要继承ClassLoader类,并实现findClass方法。在findClass方法中使用defineClass方法可以把二进制流字节组成的文件转换为一个java.lang.Class并返回(只要二进制字节流的内容符合Class文件规范)。
类加载器的双亲委派机制
启动类加载器《——扩展类加载器《——应用程序加载器《——自定义类加载器
例如:创建String类,赋予方法,如果先发现没有自定义类加载器,应用程序类加载器会先收到类加载请求,委托给上层的父加载器扩展类,
扩展类委托给它的上层的父加载器启动类来加载,启动类加载器发现自己有一个java源码其中有String类,直接就会使用java中最原始的String类,而你自己创建的String类并不会加载。
如果启动类加载器检查到无法加载该类,会抛出异常,通知下一层,下一层进行同样的操作,直到有加载器加载类
(1):最下层的(自定义类加载器)(没有自定义加载器就使用应用程序加载器)收到类加载的请求
(2):把这个请求委托给⽗加载器去完成,⼀直向上委托,直到启动类加载器
(3):启动器加载器检查能不能加载,能就加载(结束);否则,抛出异常,通知⼦加载器进⾏加载
(4):保障类的唯⼀性和安全性以及保证JDK核⼼类的优先加载
jvm沙箱安全机制
沙箱机制就是将 Java 代码限定在虚拟机(JVM)特定的运行范围中,并且严格限制代码对本地系统资源访问,通过这样的措施来保证对代码的有效隔离,防止对本地系统造成破坏。
沙箱主要限制系统资源访问,那系统资源包括什么?——CPU、内存、文件系统、网络。不同级别的沙箱对这些资源访问的限制也可以不一样。
组成沙箱的组件:
类装载器:双亲委托机制,从最上层启动类加载器开始类的加载,避免了恶意代码篡改java核心类,由于包的访问权限限制,外部恶意代码没有权限修改内层代码
字节码校验器:在编译过程完成后产生class文件检查class文件是否符合java语言规范,帮助java程序实现内存保护,java核心类(java.lang.*等)不会进行字节码校验,因为核心代码经过验证
存取控制器:存取控制器可以控制核心API对操作系统的存取权限,而这个控制的策略设定,可以由用户指定。
安全管理器:是核心API和操作系统之间的主要接口。实现权限控制,比存取控制器优先级高。
安全软件包:java.security下的类和扩展包下的类,允许用户为自己的应用增加新的安全特性,包括:安全提供者,消息摘要,数字签名(keytools,https),加密,鉴别
jvm虚拟机 栈(一个线程对应一部分栈,一个方法对应栈中一部分栈帧内存区域,栈先进后出特性与调用嵌套方法先后的需求一致)
存放内容
每有一个线程,jvm虚拟机就分配 一部分栈区域 给线程
每有一个方法,当前栈就会分配 一部分栈帧内存区域(存放在各个栈中) 给这个方法 存放方法中的局部变量表,操作数栈,动态链接,方法出口
栈的特性先进后出,调用嵌套方法时,最里层的方法需要先结束,最外层最后结束。
栈满了会报错:StackOverflowError
栈帧中:
局部变量表:存放方法中的局部变量(堆中对象的内存地址,数值)的空间————图片
操作数栈:临时存放需要做操作(加减乘除,赋值)的值(1,2,3。。)的空间,最后会将值 出该栈 放入局部变量表————局部变量与操作数栈图片
动态链接:用于调用方法时,将常量池中该方法的符号引用转换为直接引用,在方法区内部中找到该调用方法的代码位置————图片
方法出口:保存调用方法的返回信息,通过该信息知道外层方法的执行位置,继续执行外层方法。————图片
jvm虚拟机 程序计数器(存放当前线程代码运行位置)
存放内容
和栈一样,每有一个线程,jvm虚拟机就分配 一部分程序计数器区域 给线程(每个线程的程序计数器是独立的)
用于存放代码的执行到哪的位置,当线程挂起时,能知道要从哪继续执行
字节码执行引擎,执行方法区中加载的class文件的同时修改程序计数器,使其线程知道执行到哪了
jvm虚拟机 方法区(jdk6之前使用永久代(虚拟机内存),7-8使用堆的永久代,而8后没有永久代了使用元空间(本地内存)作为具体实现)(存放class,static,final,常量池(常量值,类方法的符号引用))
存放内容
存放class文件的类的相关内容(常量,静态变量,类信息),运行时常量池——运行时常量池图片
静态变量:存储的是堆的对象地址————静态变量图片
由于方法区存放类的相关信息,所以对于动态生成类的情况比较容易出现方法区的内存溢出
jdk7之前使用没在堆的单独永久代,使用jvm内存空间,会导致永久区OOM(OutOfMemoryError: PermGen space)
jdk7-8可能导致堆的OOM(OutOfMemoryError: java heap space)
jdk8之后使用元空间并不在虚拟机中,而是使用本地内存。会导致元空间OOM(OutOfMemoryError: Metaspace)
jvm虚拟机 堆(存放对象,minor gc处理年轻代垃圾对象,
老年代进入方法(生存区未满,满了),full gc处理老年代垃圾对象)
存放内容
堆存放创建的对象, 可供栈中的局部变量表引用,方法区中的静态变量引用,本地方法栈中的变量引用————图片
占堆内存的比例,年轻代:老年代 = 1:2
年轻代各个区的比例,eden:s0:s1 = 8:1:1
老年代进入方式
生存区某个区(s0或s1) 空间未满 每次minor gc 分代年龄+1 分代年龄=15时
生存区某个区(s0或s1) 空间不够存放大的对象 这个对象直接进入老年代
生存区某个区(s0或s1) 相同年龄所有对象的大小总和大于 Survivor 空间(s0或s1)的一半,大于等于该年龄的对象直接进入老年代(容易将对象放入老年代,产生老年代的full gc,解决方法:将老年代内存区域调给生存区,避免幸存对象大于占生存区的一半)
GC Roots根节点:栈中的局部变量表中引用堆的变量,方法区中引用堆的静态变量,本地方法栈的引用的变量————图片
查看对象是否可回收算法
引用计数法(缺点明显:遇到循环引用会内存溢出)
如果该对象被其它对象引用,则它的引用计数加一,如果删除对该对象的引用(P=null),那么它的引用计数就减一,当该对象的引用计数为0时,那么该对象就会被回收。
致命缺点:在遇到循环引用时,删除了最初的引用,其内部的循环引用会导致引用计数一直为1,内存回收不了内存溢出——图片
可达性分析算法(实用)
可达性分析算法:从GC Roots根节点(jvm各个区中引用堆的变量对象节点)出发,搜索向下的节点(对象中的成员变量中的对象),直到没有向下的节点了,
找到的都标记为非垃圾对象,其他的对象就是垃圾对象
GC回收对象算法
复制算法(使用在年轻代)—————图片
minor gc处理年轻代垃圾对象(伊甸园—>s0区—>s1区)
最开始对象进入堆中的年轻代空间(分代年龄<15)中的伊甸园区
当堆中的伊甸园(eden)区满了,存放不了其他的对象了,会启用字节码执行引擎的垃圾收集线程,进行对象垃圾回收堆中垃圾对象所占的内存(minor gc 可达性分析算法),
(每进行一次minor gc,分代年龄+1)
垃圾回收清空伊甸区和(s0区或者s1区)
幸存对象进入生存区(survivor区)中的s0区,之后伊甸区又满了进行minor gc 所有的幸存对象(伊甸区的,s0的)进入生存区中的s1区
之后伊甸园空间满了每进行minor gc,对象会在s0区与s1区之间转移,当分代年龄为15时,会进入堆中的老年代空间
优点:没有内存碎片
缺点:始终有一个生存区的一个区(s0或s1)没有存放数据,浪费了内存
标记清除算法(使用在老年代)(两次扫描,内存碎片问题)————图片
第一次扫描标记非垃圾对象,第二次扫描清除未标记的对象
优点:所有内存空间都能使用
缺点:扫描两次浪费时间,会产生内存碎片
标记压缩算法(使用在老年代)(标记清除的优化版)(三次扫描,无内存碎片问题)————图片
第一次扫描标记非垃圾对象,第二次扫描清除未标记的对象————第三次扫描向一边移动幸存的对象
优点:无内存碎片
缺点:比清除法多了移动的步骤
分代收集算法(根据年轻代和老年代特性使用不同的GC算法)
年轻代使用复制算法,
老年代使用标记清除算法,标记压缩算法,清除几次后再压缩
jvm虚拟机 本地方法栈(存放本地方法)
存放内容
本地方法:用native修饰(图片)的方法,由非java语言实现(c/c++语言)的方法,
常用于java自身实现困难或效率不高,而采用c/c++语言与操作系统或硬件底层的交互方法。
本地方法栈:当线程使用到本地方法时,jvm会分配 一部分本地方法栈内存空间 用于存放本地方法,
之后会调用JNI(java native interface)本地方法接口,JNI作用:加载本地方法库的方法,融合不同的编程语言(c/c++)运行java程序
JMM(java memory model)java 内存模型
作用:缓存一致性协议,用于定义数据读写的规则(遵守,找到这个规则)。
JMM定义了线程工作内存和主内存之间的抽象关系∶
线程之间的共享变量存储在主内存中,每个线程都有一个私有的本地内存,先将共享变量缓存到本地内存中,在本地内存中操作完成后,更新到主内存。
Java内存模型只保证了基本读取和赋值是原子性操作(i = 10 其他的都不是原子性),要保证更大的原子性,必须使用lock和synchronized
jvm调优工具
java自带的 jvisualvm(杰维u ven)
Arthas(阿尔萨斯)
jpfiler
Arthas使用
需要先下载arthas的压缩包,之后解压有个arthas-boot.jar
开启arthas
java -jar arthas-boot.jar
进入监控中心
dashboard
查看所有线程详情
thread
查看线程的错误堆栈(可以直接定位到具体行,cpu占用过高)
thread 线程ID
查看线程死锁
thread -b
反编译(将程序转为代码)程序(可以检查线上是否是正确版本的代码)
jad 类全名(com.demo.projectname)
jpfiler使用
下载jpfiler9.2版本,写入注册码(网上有)
idea下载插件(plugins)jpfiler
更改idea setting ——》 jprofiler 的启动exe

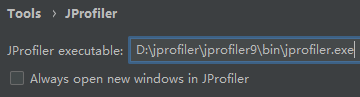
设置jvm参数,产生堆内存OOM错误信息文件(放在项目的最外层)(可以使用jpfiler打开查看报错信息)
-XX:+HeapDumpOnOutOfMemoryError

使用jpfiler 打开文件查看大对象,可以快速定位到


这个地方可以查看到哪里产生堆OOM报错

jvm参数设置

占堆内存的比例,年轻代:老年代 = 1:2
年轻代各个区的比例,eden:s0:s1 = 8:1:1
-Xms8m (设置堆初始分配内存大小 默认物理内存的1/64)
-Xmx8m (设置堆最大分配内存大小 默认1/4)
-Xmn8m (设置堆年轻代分配内存大小 默认1/4)
将堆的最小值-Xms 参数与最大值-Xmx 参数设置为一样即可避免堆自动扩展(堆内存会被垃圾回收器回收)
-XX:NewRatio=4,则表示新生代:老年代=1:4
-XX:SurvivorRatio=6,则表示Survivor区中的一个区:Eden区=1:6
-XX:+HeapDumpOnOutOfMemoryError (存储堆内存OOM错误信息为文件(文件在项目最外层)(可以使用jpfiler软件打开))
-XX:+PrintGCDetails (在idea中打印GC详情信息)
-Xloggc:log/gc.log(参数中gc.log就是外部文件的名称)(记录运行中GC日志到外部文件)
jvm调优
减少堆中老年代的full gc,因为full gc 会导致STW(stop the word),而且full gc 的STW时间较长,将用户线程停止专心进行垃圾回收,用户使用就会卡顿
STW存在的意义:如果用户线程不停止,继续执行代码,在某个方法执行完成前正在执行gc,
但可能在gc过程中该方法执行完成,其方法中的局部变量变成垃圾了,
但是gc处理该方法中的变量标记却为非垃圾,gc处理失败,会再次进行处理,命中非垃圾对象的几率低,垃圾回收效率差。
情况1:并发高的情况下,堆中的线程最后一两秒还幸存的对象大小大于生存区一半,直接进入老年代,容易产生full gc
生存区某个区(s0或s1) 相同年龄所有对象的大小总和大于 Survivor 空间(s0或s1)的一半,大于等于该年龄的对象直接进入老年代(容易将对象放入老年代,产生老年代的full gc)
解决方法:将老年代内存区域调给(伊甸区和生存区,这两个区的大小比例最好不要变),避免幸存对象大于占生存区的一半
情况2:机器的内存大,堆中的伊甸园区内存比较大(30G),当存满伊甸园区时,需要回收(minor gc)大约30G的垃圾,STW时间长,用户使用卡
解决方法:使用G1垃圾收集器,设置垃圾收集的最大停滞时间(默认200ms),其垃圾收集器将回收机制的回收阈值降低(即当伊甸园区的内存装有对象需要回收达到最大停滞时间回收100ms,就进行回收),回收3G垃圾较轻松,STW只有ms级别,对用户就没什么影响了
情况3:如果函数调用太深,超过了栈的大小(-Xss 通常只有几百k),则会抛出java.lang.StackOverflowError
解决方法:通常不会修改栈的大小(即修改-Xss),而是会检查函数是否调用太深,是否使用递归,递归是否有出口
情况4:OOM错误(OutOfMemoryError):存放对象过多释放不了,年轻代和老年代空间都被占满,报堆内存溢出错误
解决方法:1.尝试扩大堆的内存空间 2.使用jvm工具分析线程运行情况定位代码错误位置
并发编程
守护线程和用户线程区别
守护线程(daemon):是为用户线程提供服务的,当守护线程没有可服务用户线程时(即用户线程都结束了),jvm会关闭清除所有守护线程。例如:jvm垃圾回收线程
用户线程:是程序创建的线程,当主线程结束后,用户线程不会结束会接着执行,jvm存活。
线程与进程的区别(一个jvm就是一个进程,进程中各个线程共享进程资源协同处理任务)
进程是操作系统分配资源的基本单元,线程是cpu处理器任务调度和执行的基本单位。
一个应用程序只对应着一个进程,Java应用程序不存在多进程
一个程序至少有一个进程,一个进程至少有一个线程。
并发与并行的区别(并发:一个cpu切换运行不同的任务,并行:多个cpu同时进行不同的任务)
并发:进程会相互抢夺cpu资源
一个cpu多个核心也可以做到并行
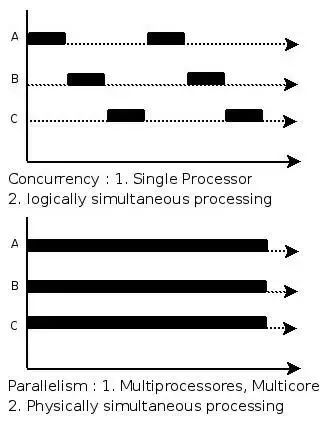
什么是多线程中的上下文切换(多线程不停抢夺cpu使用权,让cpu切换到自己线程)
上下文就是一个释放处理器的使用权,另外一个线程获取处理器的使用权,自发和非自发的调用操作,都会导致上下文切换,会导致系统资源开销。
如何避免多线程的上下文切换,资源浪费
1、简单任务使用单线程,避免多线程的上下文切换
2、在使用锁时,多线程会抢夺cpu资源导致上下文切换,
最好使用无锁hash算法并发并发编程,在多线程处理数据时,可以通过给数据取模分段(hash算法),均匀的把不同段数据的任务分给不同的线程
3、无锁CAS算法,就是等同于乐观锁(版本控制),多线程不会争夺cpu资源上锁,CAS算法采用 V现值,E期望现值,N修改后现值 参数控制是哪个线程获取资源
CAS算法(比较设置算法):通过比较V,E是否相同(线程版本号与资源版本号 是否相同),设置V值
相同就 使用N修改V(修改资源版本号),同时获取资源。
不同就 修改线程的 E期望现值,再次进入获取资源的循环
CAS可能产生ABA问题(简单的比较数值,可能产生V值变化1->2->1,但是最后的 1 已经不是之前的版本V了,无法控制版本)
需要添加版本号控制(version)
4、使用单线程协程多任务编程,通过在单线程中实现多任务的调度执行。
死锁与活锁与饥饿的区别?
死锁
是指两个或两个以上的进程(或线程)在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
产生死锁必要原因:
1.互斥条件,资源只能有一个线程占用 2.请求保持条件,在自己已有一个资源的情况下,请求其他资源被阻塞,会一直等待不释放已有资源
3.不剥夺条件,其他线程不能抢夺线程中的独占资源,只能自己主动释放 4.循环等待条件,线程间互相等待对方释放资源(乱序获取资源的锁,A线程A资源,B线程B资源 都要对方的资源)
解决办法:破坏其中一种产生原因就能解决
1.破坏互斥条件,使用CAS算法(乐观锁),不产生锁,资源不会被占用。
2.破坏请求保持条件,线程不使用 synchronized 使用 Lock锁 ,其中可以设置 获取锁的等待时长,等待超时就释放自己已有资源,重试线程。(可能导致活锁)
3.破坏循环等待条件,将获取资源的锁排序,必须按照顺序获取锁(先获取A资源再获取B资源),A线程获取A资源,B线程需要按照顺序 获取A资源阻塞,A线程能顺利获取B资源
检测死锁方法:
使用java自带的 jvisualvm(杰维u ven)检测定位发生死锁的代码行
活锁
因为某些原因,线程一直尝试,失败,尝试,失败、、导致线程一直重试
例如:使用 Lock锁 ,其中可以设置 获取锁的等待时长,等待超时就释放自己已有资源,重试线程
可能一直获取锁失败,一直重试,导致活锁
解决办法:
可以通过给重试随机设置延迟时间,在不同的时间里重试,能大大降低线程冲突的情况
饥饿(运气差和优先级低 导致 线程等待cpu运行时间长)
高优先级线程吞噬所有的低优先级线程的CPU时间。
线程被永久堵塞在一个等待进入同步块的状态,因为其他线程总是能在它之前持续地对该同步块进行访问。
线程在等待一个本身(在其上调用wait())也处于永久等待完成的对象,因为其他线程总是被持续地获得唤醒。
解决方法:
使用 Lock接口 代替 synchronized代码块 ,其中有公平锁,优先排队等待线程,不需要抢夺资源,不存在线程抢不到资源饥饿的情况
缓存一致性问题(两个线程本地缓存的数据不一致)
两个线程对共享变量 i 进行 i +1 本来预期值是2
初始时,两个线程分别读取i的值存入各自所在的CPU的高速缓存(有两个缓存其中的 i=0)当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。
此时线程2的高速缓存当中i的值还是0,进行加1操作之后,i的值为1,然后线程2把i的值写入内存。
但是主存的值是1
解决办法:
1.总线锁机制(将共享变量的内存锁住,只能由一个cpu操作,缺点:锁住内存期间,其他cpu无法访问内存,效率低下)
2.缓存一致性协议(当一个cpu在写共享变量内存时,会通知其他cpu将自己的缓存设为无效的,其他cpu在发现缓存无效后会重新读取内存并缓存)
解决以下三个特性(原子性,可见性,有序性)就能解决缓存一致性问题
原子性(线程中操作全部一起执行,不能被其他线程中断,要么就全部还没执行)
两个操作不是原子性的,就会发生执行了一个操作,另一个操作可能被中断,或者不执行,例如:i++
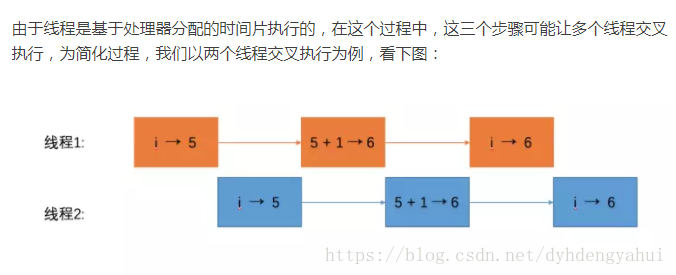
可见性(一个线程修改了共享变量的值,其他线程能够立即看得到修改的值。)
假若执行线程1的是CPU1,执行线程2的是CPU2。由上面的分析可知,当线程1执行 i =10这句时,会先把i的初始值加载到CPU1的高速缓存中,然后赋值为10,
那么在CPU1的高速缓存当中i的值变为10了,却没有立即写入到主存当中。
此时线程2执行 j = i,它会先去主存读取i的值并加载到CPU2的缓存当中,注意此时内存当中i的值还是0,那么就会使得j的值为0,而不是10.
有序性(程序执行的顺序按照代码的先后顺序执行)
指令重排序(不会影响单线程执行结果,会影响多线程):
因为只会考虑线程中数据依赖关系,对代码的执行顺序进行优化,即对没有数据依赖关系的后面的代码先执行,前面的代码后执行
多线程因为指令重排序不会考虑线程之间的数据依赖关系,会将线程中后面执行的代码先执行,可能导致其他有依赖关系的线程执行失败
//线程1: context = loadContext(); //语句1 inited = true; //语句2先执行,唤醒线程2,但是context并没有初始化完成,会导致线程2执行失败 //线程2: while(!inited ){ sleep() } doSomethingwithconfig(context);
Lock与synchronized的区别
1)Lock是一个类,而synchronized是Java中的关键字,synchronized是内置的语言(JVM)实现
2)synchronized在发生异常时,JVM会自动释放线程占有的锁,因此不会导致死锁现象发生;而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁
3)Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断
4)通过Lock可以知道有没有成功获取锁,而synchronized却无法办到
5)Lock可以多个线程同时进行读操作(读写锁)
在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,
而当竞争资源非常激烈时(即有大量线程同时竞争),此时Lock的性能要远远优于synchronized。所以说,在具体使用时要根据适当情况选择。
可重入锁
如果锁具备可重入性,则称作为可重入锁。像synchronized和ReentrantLock都是可重入锁,可重入性在我看来实际上表明了锁的分配机制:
基于线程的分配,而不是基于方法调用的分配。
举个简单的例子,当一个线程执行到某个synchronized方法时,比如说method1,
而在method1中会调用另外一个synchronized方法method2,此时线程不必重新去申请锁,而是可以直接执行方法method2。
可中断锁
在Java中,synchronized就不是可中断锁,而Lock是可中断锁。
如果某一线程A正在执行锁中的代码,另一线程B正在等待获取该锁,
可能由于等待时间过长,线程B不想等待了,想先处理其他事情,我们可以让它中断自己或者在别的线程中中断它,这种就是可中断锁。
公平锁
公平锁即尽量以请求锁的顺序来获取锁。比如同是有多个线程在等待一个锁,当这个锁被释放时,等待时间最久的线程(最先请求的线程)会获得该锁,这种就是公平锁。
非公平锁即无法保证锁的获取是按照请求锁的顺序进行的。这样就可能导致某个或者一些线程永远获取不到锁。
在Java中,synchronized就是非公平锁,它无法保证等待的线程获取锁的顺序。
而对于ReentrantLock和ReentrantReadWriteLock,它默认情况下是非公平锁,但是可以设置为公平锁(设为true)。
ReentrantLock lock = new ReentrantLock(true);
读写锁
读写锁将对一个资源(比如文件)的访问分成了2个锁,一个读锁和一个写锁。
正因为有了读写锁,才使得多个线程之间的读操作不会发生冲突(可以多个线程同时进行读操作)。
ReadWriteLock就是读写锁,它是一个接口,ReentrantReadWriteLock实现了这个接口。
可以通过readLock()获取读锁,通过writeLock()获取写锁。
volatile关键字(不会执行加锁操作。保证了可见性,有序性,无法保证原子性,使用场景:状态标记量,单例模式的双重if检验锁)
volatile bool flag = false;
有volatile修饰的变量在生成字节码文件时会产生内存屏障
作用:
1.保证了不同线程对该变量操作的内存可见性,当一个线程在自己的工作内存中修改了这个变量的值,volatile 保证了新值能立即同步到主内存。
2.在有线程作了写操作时,其他线程将自己的缓存设为无效的,其他线程在发现缓存无效后会重新读取主内存并缓存最新变量值
3.禁止指令重排序,有volatile修饰的变量,相隔两边的代码顺序不能越过内存屏障到另一边,一边可以随便换顺序
使用条件:必须对该变量的操作是原子性的
使用场景:
1.状态标记量
volatile boolean inited = false; //线程1: context = loadContext(); inited = true; //线程2: while(!inited ){ sleep() } doSomethingwithconfig(context);
2.懒汉式单例模式的双重 if 检验锁(用于创建供多线程使用的单例对象(类只能创建一个对象),因为创建对象不是原子性的,需要使用synchronized)
懒汉式:使用时才创建对象
public class Singleton{ private static volatile Singleton singleton; private Singleton(){} public static Singleton newInstance(){ //第一次if是用来提高创建后的效率,当对象已经创建了,多线程不会抢夺锁,浪费资源 if(singleton==null){ //获取对象的锁 synchronized(Singleton.class){ //第二次if是判断有没有创建对象 if(singleton==null){ singleton=new Singleton(); } } } return singleton; } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号