kafka面试题
Kafka简介和机制
kafka ISR是什么
所有与leader副本保持一定程度同步的副本(包括Leader)集合
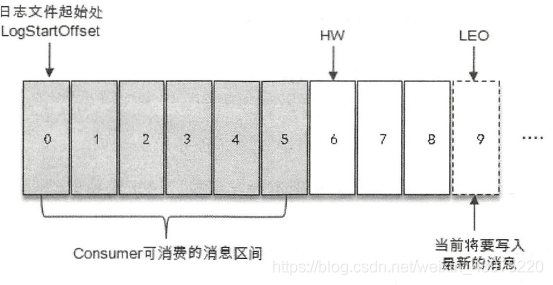
kafka HW是什么
高水位,消费者所能看到的最大的offset(消费位置),同时也是不同副本的同步的最小offset
kafka LEO是什么
每个分区中多个副本都有的最大的offset
kafka 消息顺序性怎么体现
Kafka只能保证分区内消息顺序有序,无法保证全局有序
kafka 拦截器,序列化器,分区器 有什么用,什么顺序运行
拦截器——>序列化器——>分区器
拦截器:生产者拦截器可以用来在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息,修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求。
序列化器:将发送给kafka的key,value序列化
分区器:确定消息要发往的分区
kafka生产者客户端整体结构,使用了几个线程处理
整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和发送线程。
在主线程中由 KafkaProducer 创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息收集器(RecordAccumulator,也称为消息累加器)中。
发送线程负责从消息收集器中获取消息并将其发送到 Kafka 中。
一个消费者只能消费一个分区的数据
消费者提交消费位移时,提交的是当前消费到最新位置的offset+1
数据重复消费:先消费,没有提交消费位移
数据漏消费:先提交消费位移,后消费
主题的分区数能增加不能减少,减少后已存在分区中的数据不能处理
kafka内部有自己的主题(offset),用来存不同分区的offset
kafka分区分配策略
- RoundRobin:轮训(消费者订阅同一主题)(合并所有的topic再分配) ==》topic不应该被全部消费者消费时,造成消费错误
- 轮询图片
- Range:(消费者订阅不同的主题)以topic为单位单独分==》造成分配不均匀
- range图片
kafka日志目录结构
生产者产生的数据会放在log的尾部,为防止log文件过大,kafka采用分片和索引的方式,将每个分区分为多个segment
每个segment分为.index文件和.log文件,
index文件就是log文件的索引文件(具有offset与对应的log文件的偏移量),log文件是数据文件
通过二分查找找到index文件名,进入index文件,通过查询的offset找到log文件数据的偏移量,通过当前获取的偏移量在index文件获取数据
kafka controller的作用
controller主要依靠ZK完成对集群broker和分区的管理如集群broker信息、分区选举ISR
kafka 有哪些地方需要选举 怎么选举
controller:通过抢先资源的方式选举,谁先谁就是controller
leader:通过在ISR中选举出leader,当 ISR 中的 follower 完成数据的同步之后,leader 就会给 follower 发送 ack。如果 follower长时间未向 leader 同 步 数 据 ,
则 该 follower将 被 踢 出 ISR , 该 时间阈值由replica.lag.time.max.ms 参数设定。Leader 发生故障之后,就会从 ISR 中选举新的 leader。
kafka高性能
分布式
顺序读写(新加数据追加到log文件尾部,顺序写入磁盘(速度快),而不是随机写磁盘)
零拷贝(磁盘文件读取到操作系统内核缓冲区后、直接扔给网卡,发送网络数据。没有经过应用程序,减少了两次copy)(传统拷贝:读取文件,再用socket发送出去)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号