mysql 索引
索引:排好序的快速查找数据结构
优势:
会影响查询(select)(降低数据库io成本)
排序(order by)(降低cpu的消耗)
劣势:
索引也是一张表,保留了主键和索引字段,并指向实体表的记录,索引也是要占用空间的
降低更新表的速度(增删改),因为在更新表时,mysql不仅要保存数据,也要保存索引文件更新索引列的字段,调整因为更新所带来的索引信息
需要花时间研究建立最完美的索引(需要研究主要需要什么来索引)

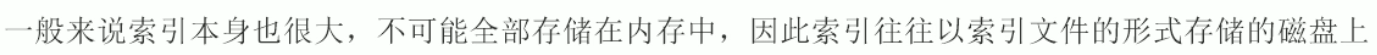
什么情况建索引:
主键自动建立唯一索引
频繁作为查询条件的应建索引
查询中与其他表关联的字段,外键关系建立索引
单键/组合索引的选择问题(高并发倾向建组合索引)
查询中需要排序的字段需要建索引
查询中统计或分组(group by)字段
什么时候不要建索引:
表的记录太少(300百万级别)
经常增删改的表(不仅要保存表,还要保存索引文件)
数据重复且平均分布的字段 (性别只有男女之分,且在表的分布将近为一半)
单值索引(一个索引只能包含一个列)(一个表可以有多个)
select * from user where name = ""
在user表中的name上建索引(索引名为(一般使用idx作为索引前缀):idx_user_name 建索引方法:create index)
create index idx_user_name on user(name)
复合索引
select * from user where name = "" and email = ""
在user表中的name和email上建索引(索引名为(一般使用idx作为索引前缀):idx_user_nameEmail 建索引方法:create index)
create index idx_user_nameEmail on user(name,email)
唯一索引(索引列的值必须唯一,允许有空值)(银行卡号)
create unique index
删除索引(idx_user_name是索引名 user是表名)
drop index idx_user_name on user
查看索引
show index from user

在最后,总结一下什么最左前缀原则:查询从索引的最左前列开始并且不跳过索引中的列,通俗易懂的来说就是:带头大哥不能死、中间兄弟不能断
为什么选用B+树作为数据库的索引结构:
B+树的中间节点不保存数据,是纯索引,但是B树的中间节点是保存数据和索引的,相对来说,B+树磁盘页能容纳更多节点元素,更“矮胖”;
B+树查询必须查找到叶子节点,B树只要匹配到即可不用管元素位置,因此b+树查找更稳定(并不慢);
对于范围查找来说,B+树只需遍历叶子节点链表即可,B树却需要重复地中序遍历,在项目中范围查找又很是常见的
增删文件(节点)时,效率更高,因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
b树(多路搜索树索引)(红色是数据 黄色是指针)
一个M阶的b树具有如下几个特征: (如下图M=3)(下文的关键字可以理解为 有效数据,而不是单纯的索引)
定义任意非叶子结点最多只有M个儿子,且M>2;
根结点的儿子数为[2, M];
除根结点以外的非叶子结点的儿子数为[M/2, M],向上取整; (儿子数:[2,3])
非叶子结点的关键字个数=儿子数-1;(关键字=2)
所有叶子结点位于同一层;
k个关键字把节点拆成k+1段,分别指向k+1个儿子,同时满足查找树的大小关系。(k=2)
有关b树的一些特性,注意与后面的b+树区分:
关键字集合分布在整颗树中;
任何一个关键字出现且只出现在一个结点中;
搜索有可能在非叶子结点结束;
其搜索性能等价于在关键字全集内做一次二分查找;
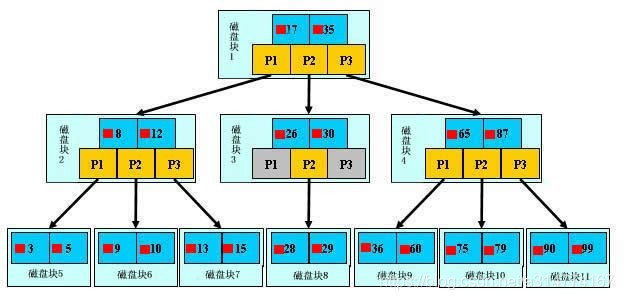
b+树,是b树的一种变体,查询性能更好。m阶的b+树的特征:
有n棵子树的非叶子结点中含有n个关键字(b树是n-1个),这些关键字不保存数据,只用来索引,所有数据都保存在叶子节点(b树是每个关键字都保存数据)。
所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
所有的非叶子结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
通常在b+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点。
同一个数字会在不同节点中重复出现,根节点的最大元素就是b+树的最大元素。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号