redis简介
Redis概述
- Redis是一个开源的key-value存储系统。
- 和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。
- 这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
- 在此基础上,Redis支持各种不同方式的排序。
- 与memcached一样,为了保证效率,数据都是缓存在内存中。
- 区别的是Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。
- 并且在此基础上实现了master-slave(主从)同步。
默认16个数据库,类似数组下标从0开始,初始默认使用0号库
使用命令 select <dbid>来切换数据库。如: select 8
统一密码管理,所有库同样密码。
dbsize查看当前数据库的key的数量
flushdb清空当前库
flushall通杀全部库
redis为什么速度快?
完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。
数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的
采用单线程,避免了不必要的上下文切换(切换线程)和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
(这里我们一直在强调的单线程,只是在处理我们的网络请求的时候只有一个线程来处理,一个正式的Redis Server运行的时候肯定是不止一个线程的,例如Redis进行持久化的时候会以子进程或者子线程的方式执行)
采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,
比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)
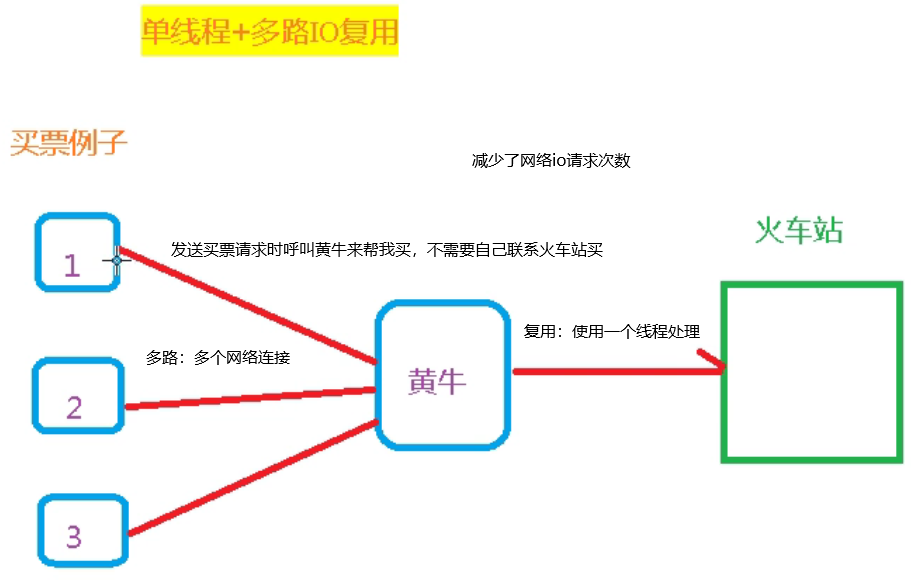
应用场景
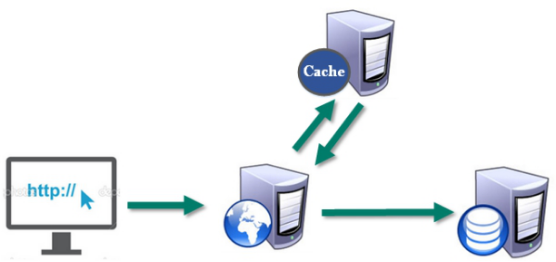
配合关系型数据库做高速缓存
- 高频次,热门访问的数据,降低数据库IO
- 分布式架构,做session共享
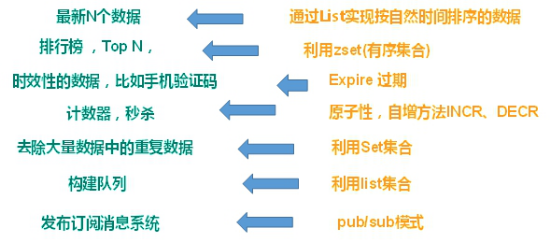
多样的数据结构存储持久化数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号