redis集群
Redis集群
Redis 集群:实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区来提供一定程度的可用性: 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
数据分片(将数据分给不同的redis服务器)
(1)客户端实现数据分片
即客户端自己计算数据的key应该在哪个机器上存储和查找,此方法的好处是降低了服务器集群的复杂度,客户端实现数据分片时,服务器是独立的,服务器之前没有任何关联。多数redis客户端库实现了此功能,也叫sharding,这种方式的缺点是客户端需要实时知道当前集群节点的联系信息,同时,当添加一个新的节点时,客户端要支持动态sharding.,多数客户端实现不支持此功能,需要重启redis。另一个弊端是redis的HA(高可用性)需要额外考虑。
(2)服务器实现数据分片
其理论是,客户端随意与集群中的任何节点通信,服务器端负责计算某个key在哪个机器上,当客户端访问某台机器时,服务器计算对应的key应该存储在哪个机器,然后把结果返回给客户端,客户端再去对应的节点操作key,是一个重定向的过程,此方式是redis3.0正在实现,目前处于beta版本, Redis 3.0的集群同时支持HA功能,某个master节点挂了后,其slave会自动接管。
(3)通过代理服务器实现数据分片
此方式是借助一个代理服务器实现数据分片,客户端直接与proxy联系,proxy计算集群节点信息,并把请求发送到对应的集群节点。降低了客户端的复杂度,需要proxy收集集群节点信息。Twemproxy是twitter开源的,实现这一功能的proxy。这个实现方式在客户端和服务器之间加了一个proxy,但这是在redis 3.0稳定版本出来之前官方推荐的方式。结合redis-sentinel的HA方案,是个不错的组合
Redis 集群提供了以下好处
实现扩容,分摊压力,无中心配置相对简单
Redis 集群的不足
多键操作是不被支持的,多键的Redis事务是不被支持的。lua脚本不被支持,由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
问题
容量不够,redis如何进行扩容?
并发写操作, redis如何分摊?
另外,主从模式,薪火相传模式,主机宕机,导致ip地址发生变化,应用程序中配置需要修改对应的主机地址、端口等信息。
解决
添加多个主机同时进行写操作
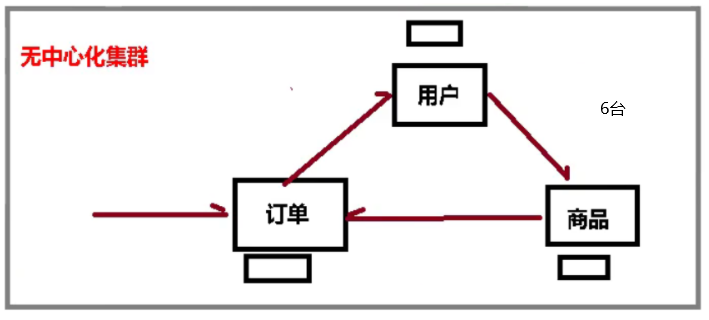
之前通过代理主机来解决,但是redis3.0中提供了解决方案。就是无中心化集群配置。
代理主机
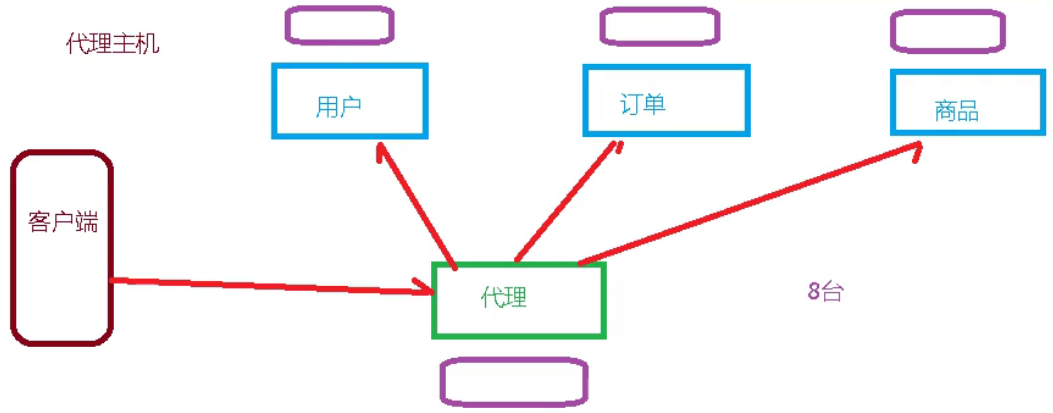
无中心化集群配置
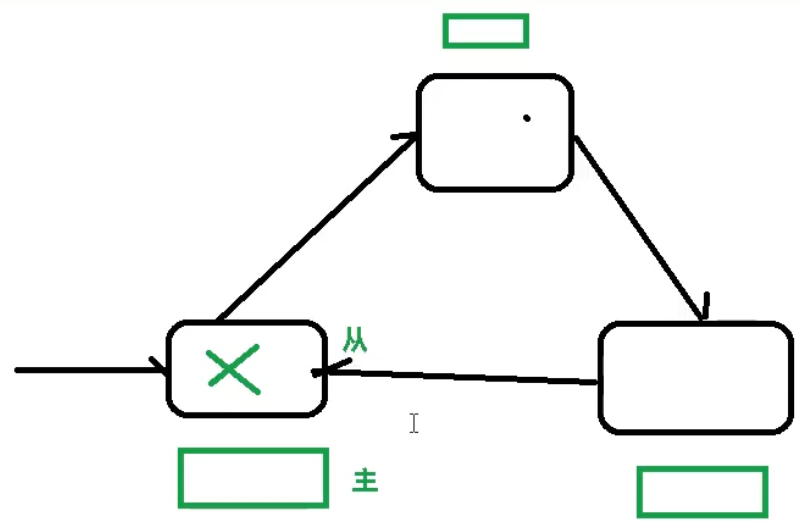
某一个主机挂掉后,之后从机补上空位,主机重启为从机(和哨兵模式一样)
先删除持久化文件(*为匹配通配符,dump63*代表前缀带dump63的文件)
rm -rf dump63*
创建配置文件(开启集群模式)(制作6个实例,6379,6380,6381,6389,6390,6391)
#引用原redis.conf
include /etc/redis.conf
#Pid文件名字pidfile(后台运行时写入pid的文件)
pidfile /var/run/redis_6391.pid
#开启daemonize yes(守护线程 即后台运行)
daemonize yes
#dump.rdb名字dbfilename
dbfilename dump6391.rdb
#30秒中有5个key修改了就进行持久化
save 30 5
#设置自己redis的密码
requirepass 123456
#给从机设置主机的密码
masterauth 123456
#指定端口port
port 6391
#打开集群模式
cluster-enabled yes
#设定节点配置文件名
cluster-config-file nodes-6391.conf
#设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。
cluster-node-timeout 15000
#设置某块主从都挂掉,是否挂掉整个集群(默认为no 某块主从的使用不了,其他的可以用)
#cluster-require-full-coverage yes
启动6个redis服务实例(重新启动节点时必须要先进入redis中 cd /myredis)
redis-server /myredis/redis6379.conf
redis-server /myredis/redis6380.conf
redis-server /myredis/redis6381.conf
redis-server /myredis/redis6389.conf
redis-server /myredis/redis6390.conf
redis-server /myredis/redis6391.conf
查看redis进程状态
ps -ef | grep redis
开放端口(需要防火墙开放6379到6391端口,以及redis总线(前面端口+10000):16379到16391:)
/sbin/iptables -I INPUT -p tcp --dport 6379:6381 -j ACCEPT
/sbin/iptables -I INPUT -p tcp --dport 6389:6391 -j ACCEPT
/sbin/iptables -I INPUT -p tcp --dport 16379:16381 -j ACCEPT
/sbin/iptables -I INPUT -p tcp --dport 16389:16391 -j ACCEPT
备注:关闭端口(将ACCEPT 换为 DROP)
将六个节点合成一个集群
组合之前,请确保所有redis实例启动后,nodes-xxxx.conf文件都生成正常。
跳转位置(需要先查看redis文件夹名称)
cd /opt/redis-6.2.5/src
合成集群(-a后的123456是密码 --cluster-replicas后的1为 主机和从机比例为1:1(ip必须使用真实的公网ip地址(使用云服务器情况) 后面ip不能为127.0.0.1 6381端口为主机对应6389端口从机,切两半对应最近的))
redis-cli -a 123456 --cluster create --cluster-replicas 1 112.126.246.5:6379 112.126.246.5:6380 112.126.246.5:6381 112.126.246.5:6389 112.126.246.5:6390 112.126.246.5:6391
成功后
普通方式登录redis-cli -p 6379
可能直接进入读主机,存储数据时,会出现MOVED重定向操作。所以,应该以集群方式登录
进入集群操作(多了-c 需要-a添加密码,跳转后放入数据不会报没有权限)
redis-cli -c -p 6379 -a 123456
查看节点状态
cluster nodes
放入一条数据(使用key来计算插槽)(不能同时添加多个key(计算不了插槽),需要使用组)
set k1 v1
放入几条数据(使用一个组 {xxx} 来计算插槽( 例如:user ))
mset name{user} lucy age{user} 20
查询集群中的key(5474:插槽值, 1:返回key的数量)
cluster getkeysinslot 5474 1
计算key对应的插槽值(不需要已放入值)
cluster keyslot user
查询已进入主机中的插槽对应有几个值(不能查询已进入插槽范围外的)
cluster countkeysinslot 5474


public class RedisCluster { public static void main(String[] args){ JedisPoolConfig config = new JedisPoolConfig(); config .setMaxTotal(500); config .setMinIdle(2); config .setMaxIdle(500); config .setMaxWaitMillis(10000); config .setTestOnBorrow(true); config .setTestOnReturn(true); //创建对象 Set<HostAndPort> nodes = new HashSet<HostAndPort>(); nodes.add(new HostAndPort("112.126.246.5", 6379)); nodes.add(new HostAndPort("112.126.246.5", 6380)); nodes.add(new HostAndPort("112.126.246.5", 6381)); nodes.add(new HostAndPort("112.126.246.5", 6389)); nodes.add(new HostAndPort("112.126.246.5", 6390)); nodes.add(new HostAndPort("112.126.246.5", 6391)); JedisCluster jedisCluster = new JedisCluster(nodes, 10000, 10000, 100, "123456", config); //进行操作 jedisCluster.set("b1","value"); String value = jedisCluster.get("b1"); System.out.println(value); jedisCluster.close(); } }
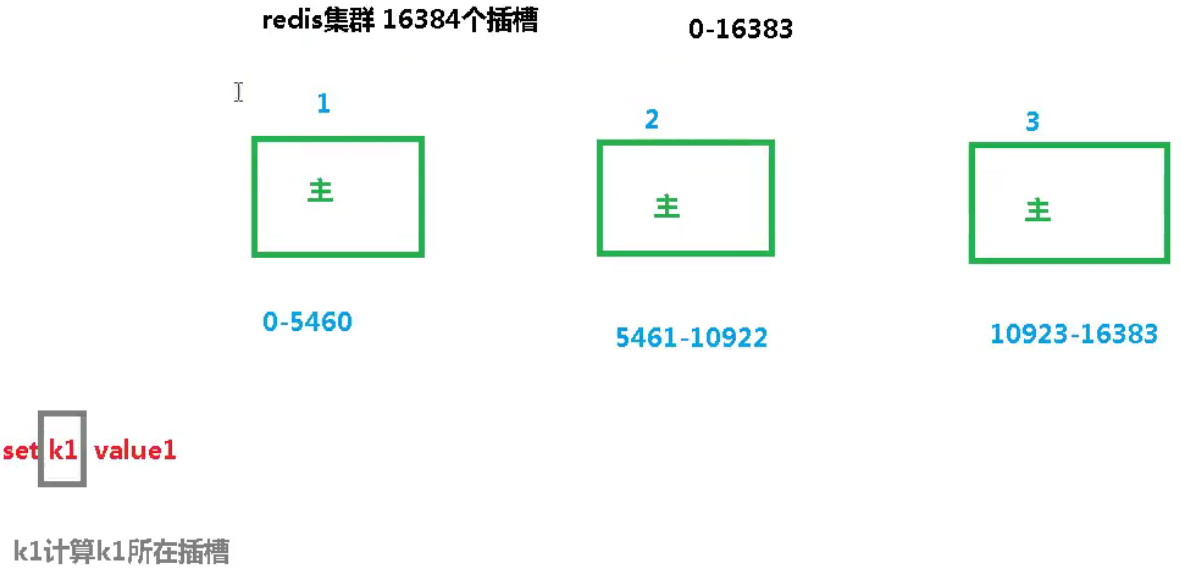
集群使用插槽将数据平均分配到不同的主机上(计算方式和hash算法相似)
一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个,
集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群可以有主节点, 其中:
节点 A 负责处理 0 号至 5460 号插槽。
节点 B 负责处理 5461 号至 10922 号插槽。
节点 C 负责处理 10923 号至 16383 号插槽。
当放入值时会计算键或者组插槽值,根据插槽范围决定切换到那台主机的redis中进行放入值的操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号