
Hadoop2的FN安装(federated namespace)
尝试了简单的安装hadoop2后,我们再来尝试一下hdfs的一项新功能:FN。这项技术可以解决namenode容量不足的问题。它采用多个namenode来共享datanode的方式,每个namenode属于不同的namespace。
下面是我们的安装信息
Hadoop 版本:2.2.0
OS 版本: Centos6.4
Jdk 版本: jdk1.6.0_32
机器配置
|
机器名 |
Ip地址 |
功能 |
|
Hadoop1 |
192.168.124.135 |
NameNode, DataNode, ResourceManager, NodeManager |
|
Hadoop2 |
192.168.124.136 |
NameNode DataNode, NodeManager |
|
Hadoop3 |
192.168.124.137 |
DataNode, NodeManager
|
配置
vi etc/hadoop/hadoop-env.sh 修改jdk位置
export JAVA_HOME=/home/hadoop/jdk1.6.0_32
vi etc/hadoop/mapred-env.sh修改jdk位置
export JAVA_HOME=/home/hadoop/jdk1.6.0_32
vi etc/hadoop/yarn-env.sh修改jdk位置
export JAVA_HOME=/home/hadoop/jdk1.6.0_32
vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/repo2/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
</configuration>
vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/repo2/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/repo2/data</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>hadoop1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>hadoop1:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns1</name>
<value>hadoop1:50090</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>hadoop2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>hadoop2:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.ns2</name>
<value>hadoop2:50090</value>
</property>
</configuration>
vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<description>the valid service name</description>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<description>The hostname of the RM.</description>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
</configuration>
vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi etc/hadoop/slaves
hadoop1
hadoop2
hadoop3
格式化namenode
在hadoop1和hadoop2上运行:bin/hdfs namenode -format -clusterid mycluster
启动hadoop集群
cd /home/hadoop/hadoop-2.2.0
sbin/start-all.sh
从图上可以看出,先启动namenode,再启动datanode, 再启动secondarynamenode, 再启动resourcemanger, 最后启动nodemanager。
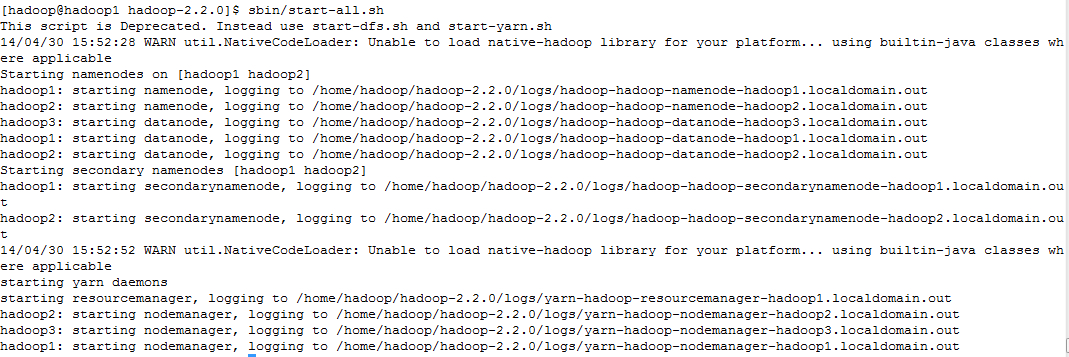
使用jps查看启动的进程
在hadoop1上运行jps
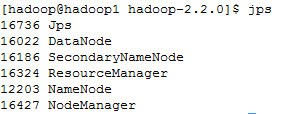
在hadoop2上运行jps
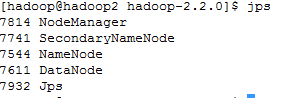
在hadoop3上运行jps

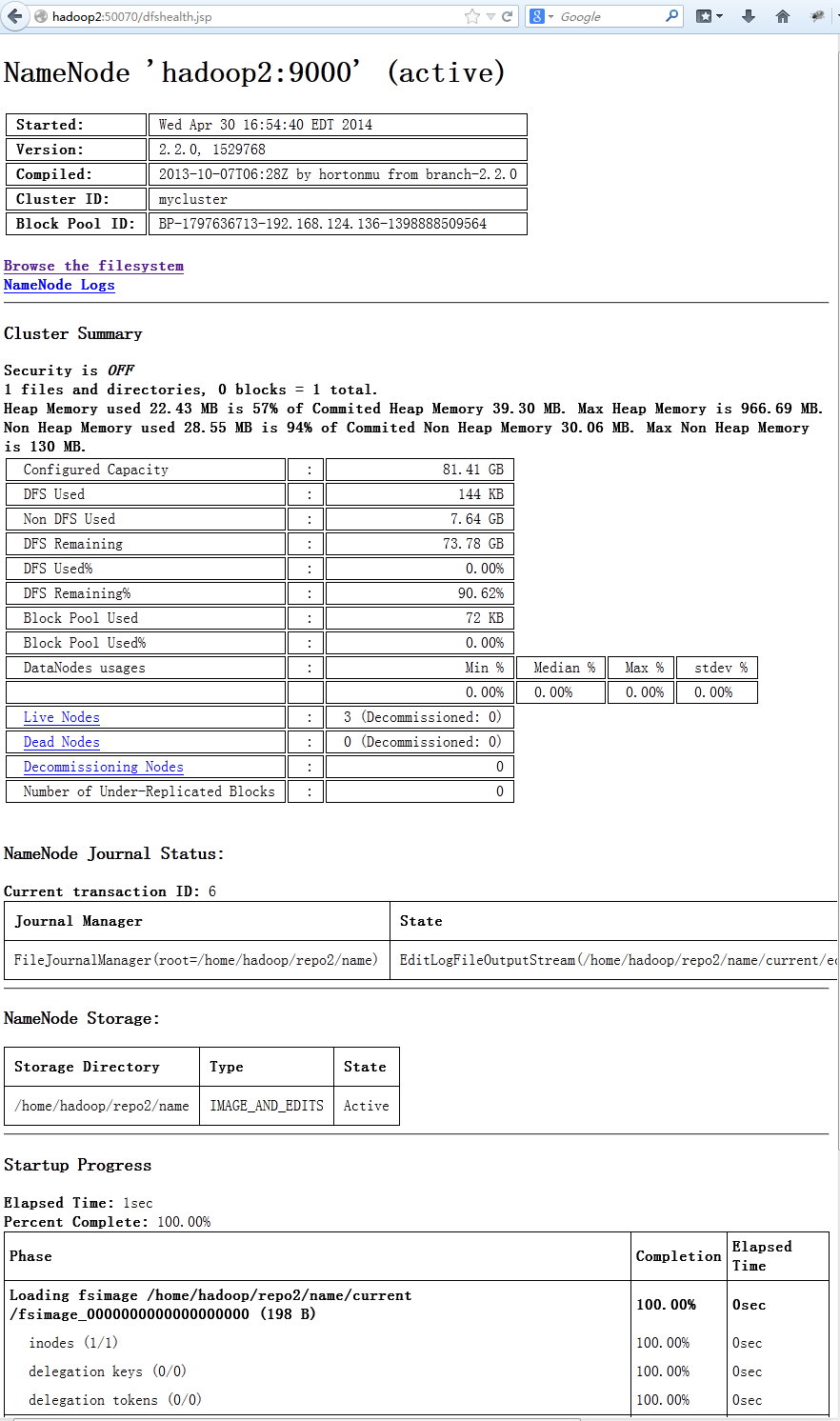
从图上可以看出hadoop2和hadoop1上的namenode都处于active状态,他们两个同时在线工作。
通过Hadoop的web界面可以看到,hadoop1和hadoop2都处于active状态,他们当前都是可以工作的,只是hadoop1工作在命名ns1,hadoop2工作在ns2上
在浏览器里输入http://hadoop1:50070
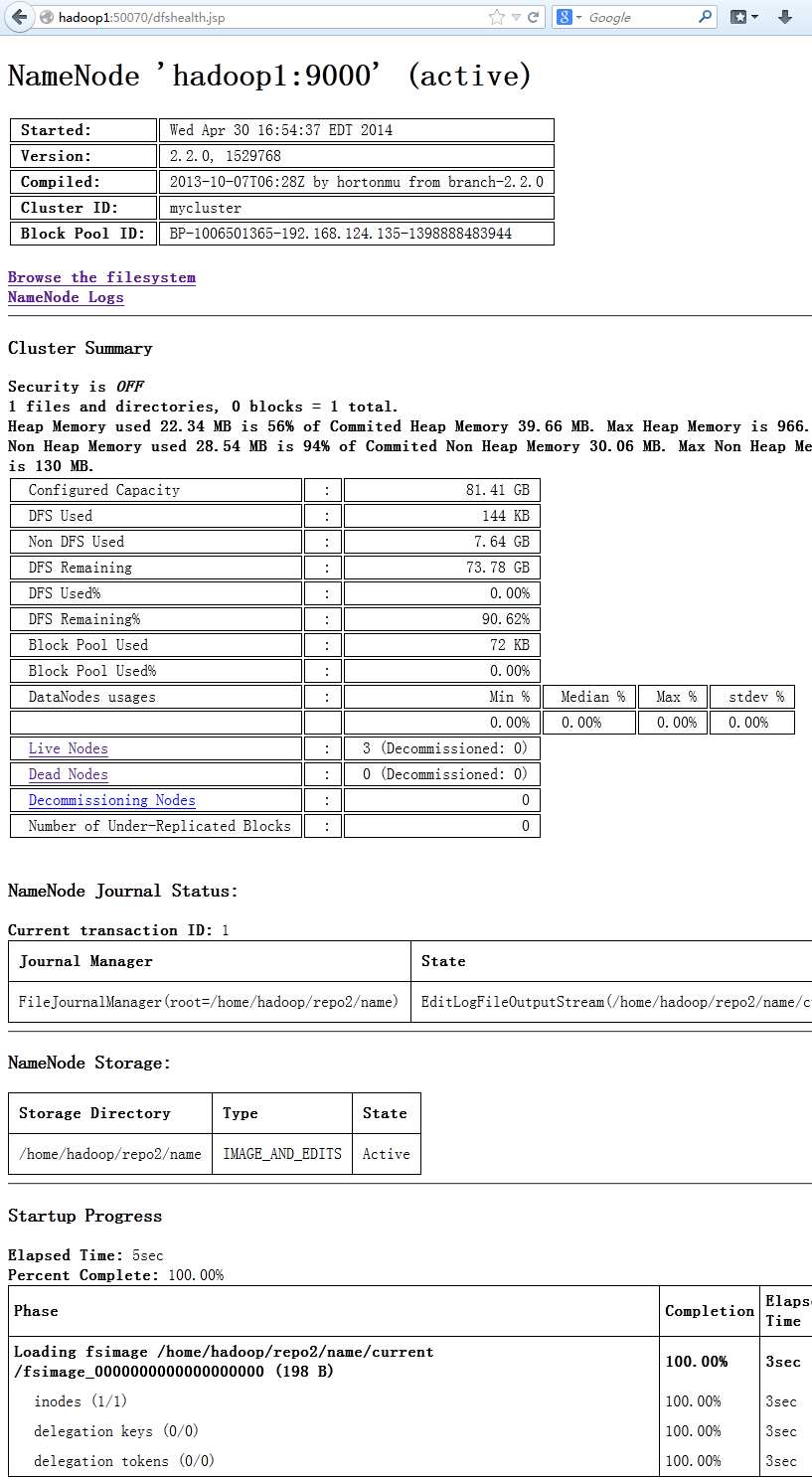
在浏览器里输入http://hadoop2:50070
通过命令行看这两个namenode数据
bin/hdfs dfs -mkdir hdfs://hadoop1:9000/user/hadoop/input
bin/hdfs dfs -copyFromLocal etc/hadoop/* hdfs://hadoop1:9000/user/hadoop/input
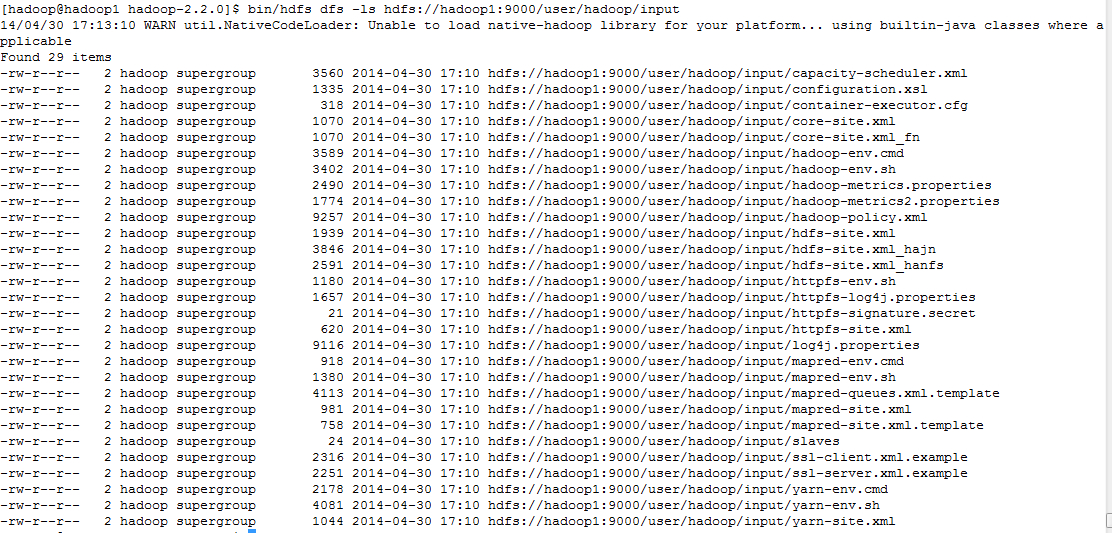
bin/hdfs dfs -ls hdfs://hadoop1:9000/user/hadoop/input
bin/hdfs dfs -ls hdfs://hadoop2:9000/user/hadoop/input

从上面可以看出对hadoop1上的namenode操作,不会影响到hadoop2上的namenode,因此采用federated namespace可以存储两倍或者更多的metadata信息。当发现namespace空间成瓶颈时,可以再添加一台来扩展namespace空间。目前有一个小的问题,当添加一个namespace节点时,需要重启整个集群。通常工作中hadoop集群是不能重启的,这有可能将是一个问题。我认为解决这个问题不存在技术上的问题,可能在后面的版本中解决这个问题。
posted on 2014-05-13 09:31 cloudkiller 阅读(693) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号