
十、Jmeter关联-Xpath提取器
写在前面的话
全国相继出现新型冠状病毒,也挡不住我更新Jmeter系列的热情!
Xpath提取器在做网页源文件提取时候用的比较多,提取完参数后,相当于把参数以key-value的形式放到参数池,以便后面的请求使用。
**注意:不能超前引用,即在定义前就进行参数化**
实战
在请求的子节点下添加后置处理器Xpath提取器,如下源文件
我们来利用xpath提取出所有随笔的URL,如下图,所有url都匹配出来了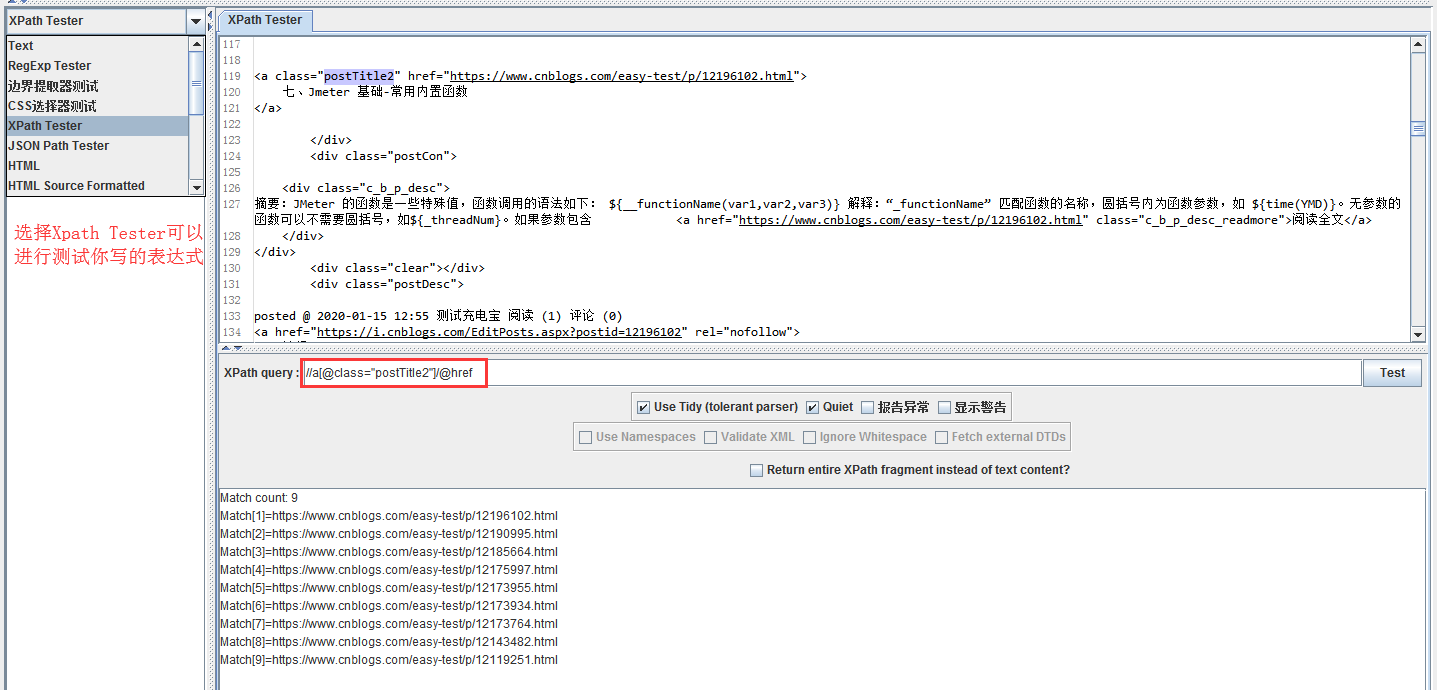
表达式://a[@class="postTitle2"]/@href解释,意思就是查找所有的a标签,a标签要满足class属性为“postTitle2”,通过@获取a标签的属性值
如果想提取a标签的名称,我们可以把表达式写成:
//a[@class="postTitle2"]/text()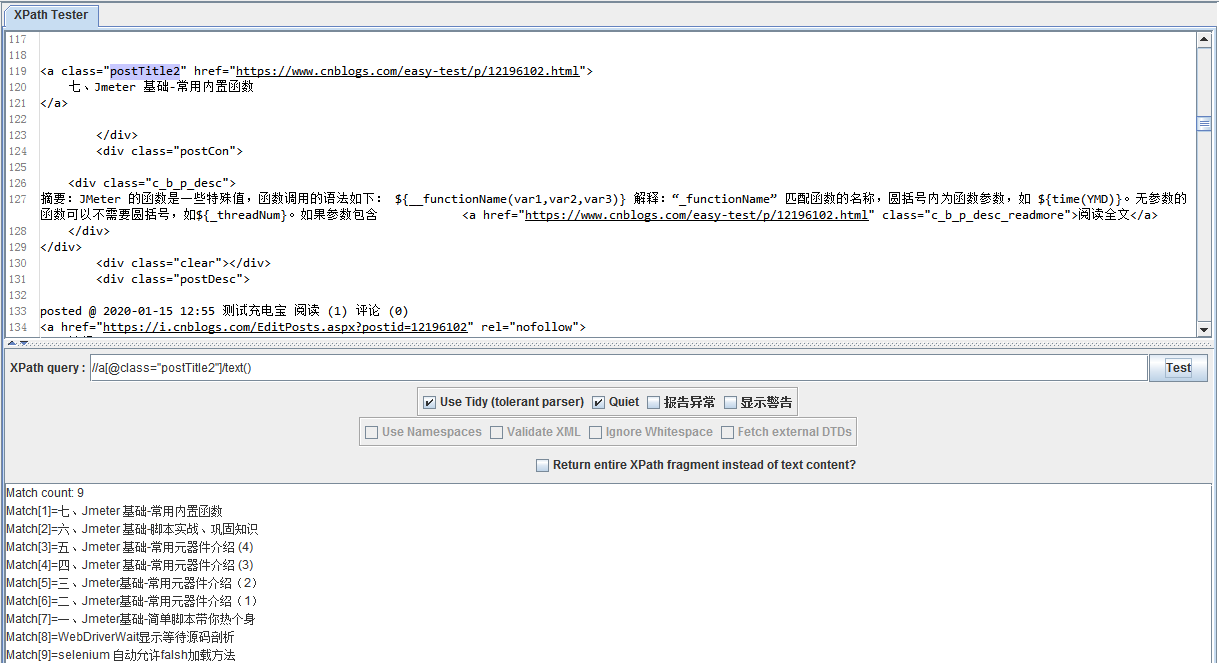
另外表达式://a[@class="postTitle2"],去掉/text()也是可以的,大家可以自己试试
Xpath语法:
- //*[@class='postTitle2']/@href 从根目录下定位所有class=postTitle2的href值
- //*[@class='postTitle2'] 从根目录下定位所有class=postTitle2标签内的文本
- //a[contains(@class,'postTitle2')] 从根目录下a标签的class值中包含postTitle2的节点
- substring-before(.//*[@class='postTitle2']/text(),'基础') 返回根目录下[@class='postTitle2']/text()中第一个'基础'前面的部分,如果不存在'基础',则返回空值
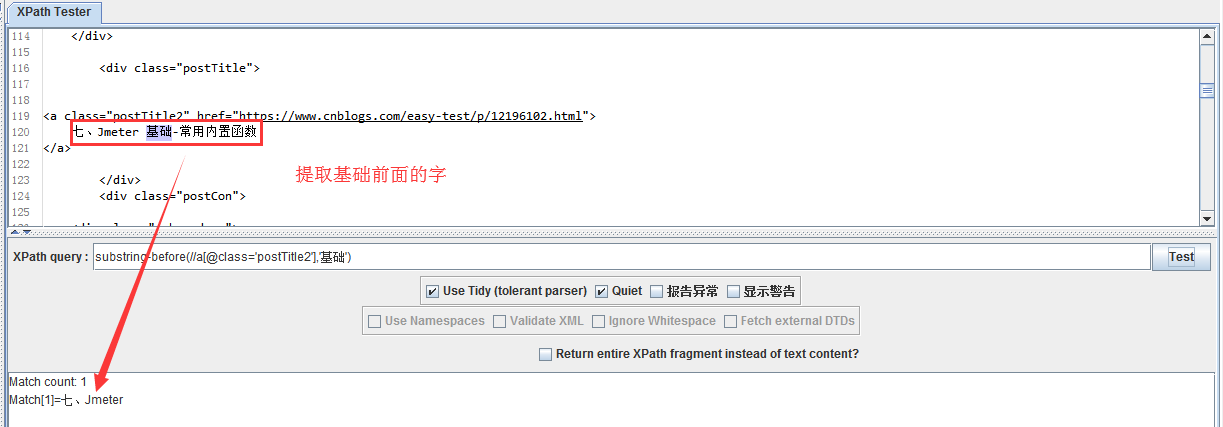
- substring-after(.//*[@class='postTitle2']/text(),'基础') 和上面的结果相反,得到“-常用内置函数”
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号