
四、Jmeter 基础-前置处理器、后置处理器
前置处理器
前置处理器中,我觉得BeanShell 预处理程序,用户参数,JDBC 预处理程序用的比较多
JDBC 预处理程序:跟JDBC request类似,不做过多介绍
BeanShell 预处理程序:准备在进阶篇中介绍,基础篇不做过多介绍,会用到java
用户参数:我在工作中用的很少,还是喜欢用户自定义变量
后置处理器
主要元器件:正则表达式提取器,JSON提取器,边界提取器,XPath提取器,BeanShell 后置处理程序
正则表达式提取器
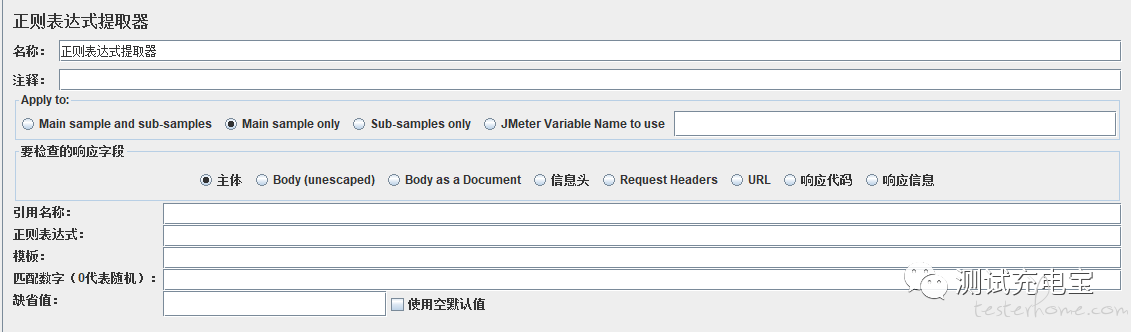
APPly to
Main sample and sub-samples:作用于主节点的取样器及对应子节点的取样器
Main sample only:仅作用于主节点的取样器
Sub-samples only:仅作用于子节点的取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称),从指定变量值中提取需要的值。
要检查的响应字段
主体:响应报文的主体,最常用
Body(unescaped):主体,是替换了所有的html转义符的响应主体内容,注意html转义符处理时不考虑上下文,因此可能有不正确的转换,不太建议使用
Body as a Document:从不同类型的文件中提取文本,注意这个选项比较影响性能
信息头:响应信息头(如果你使用的是中文版的Jmeter,会看到这一项是信息头,这是中文翻译问题,应以英文为准)
Request Headers:请求信息头
URL:请求url
响应代码:比如200、404等
响应信息:响应信息
参数设置说明
引用名称:参数名称,可以被调用
正则表达式:使用正则表达式解析响应结果,正则的基本使用方法可参考正则表达式的官方说明
模板:如果正则表达式有多个提取结果,则结果是数组形式,模板$1$,$2$等等,表示把解析到的第几个值赋给变量;从1开始匹配,以此类推。若只有一个结果,则只能是$1$;
匹配数字(0代表随机):正则表达式匹配数据的结果可以看做一个数组,表示如何取值:0代表随机取值,正数n则表示取第n个值(比如1代表取第一个值),负数则表示提取所有符合条件的值。
缺省值:默认值,取不到的情况,参数名称赋的值
举例
view=1&token=721652512141&name=ggui
要取token值
正则表达式:token=(\d+)&name=ggui
特别说明
".?"在正则中非常好用,能解决大部分匹配
上面表达式可改写成token=(.?)&name=ggui
JSON提取器
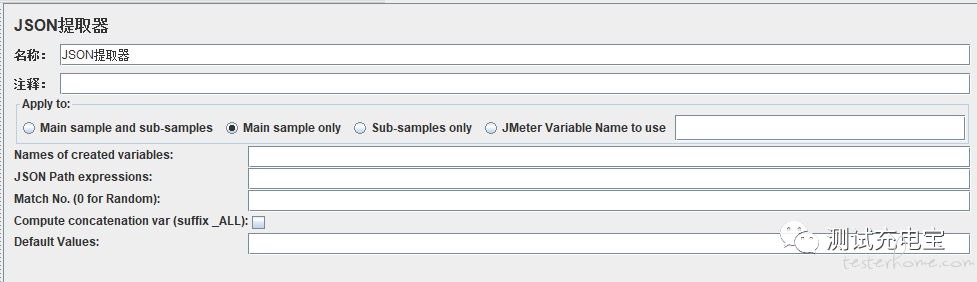
用于提取请求返回结果中的某个值或者某一组值,标准写法为$.key,其中key为返回结果中的一个键,如果是多层则继续用.key即可,如果遇到key的value值为一个List,则使用.key[n],其中n为list中元素的索引
参数设置说明
Names of created variables:参数名称,可以被调用
JSON Path expressions:表达式
Match No.(0 for Random):匹配编号,-1匹配所属有,0随机,其他则从1开始
Default Values:默认值,取不到的情况,参数名称赋的值
举例
{ "data":[ { "name":"张三", "age":18 }, { "name":"李四", "age":28 } ] }
要取第一个人的姓名
JSON Path expressions:$.data[0].name
要取年龄>18的姓名
JSON Path expressions:$.data[?(@.age>18)].name
边界提取器
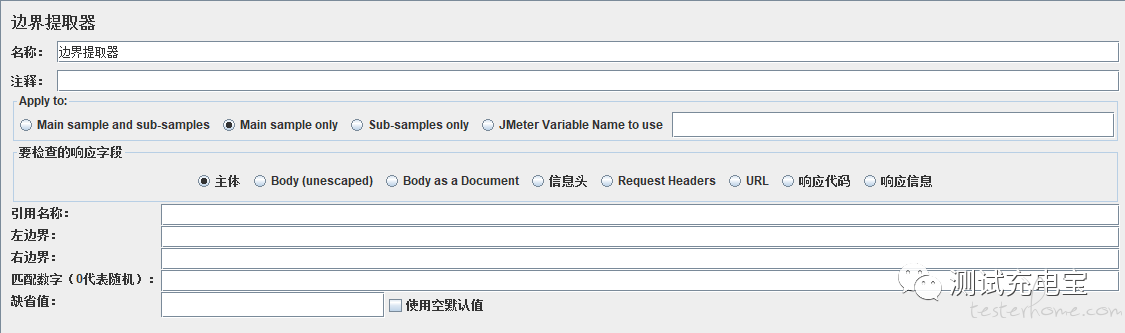
参数设置说明
引用名称:参数名称,可以被调用
左边界:要提取字符的左边
有边界:要提取字符的右边
匹配数字(0代表随机):匹配编号,-1匹配所属有,0随机,其他则从1开始
缺省值:默认值,取不到的情况,参数名称赋的值
举例
view=1&token=721652512141&name=ggui
左边界:token=
右边界:&name
可得到结果721652512141
PS:注意,左右边界尽可能唯一,能更精确匹配到想提取的字符
XPath提取器
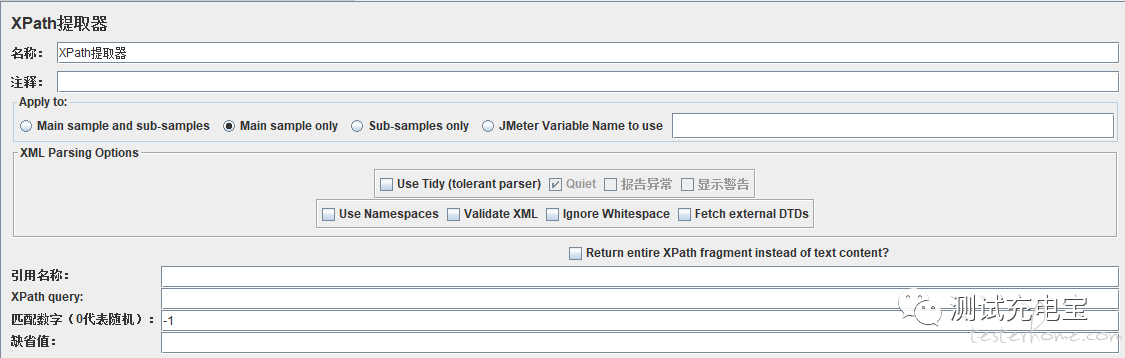
XML Parsing Options(要解析的XML参数)
Use Tidy(tolerant parser):当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式(例如RSS返回),则取消选中
Quiet:表示只显示需要的HTML页面
报告异常:表示显示响应报错
显示警告:表示显示警告
Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨
Validate XML:根据页面元素模式进行检查解析
Ignore Whitespace:忽略空白内容
Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容
Return entire XPath fragment of text content:返回文本内容的整个XPath片段
参数设置说明
引用名称:参数名称,可以被调用
XPath Query:用于提取值的XPath表达式
匹配数字:匹配编号,-1匹配所属有,0随机,其他则从1开始
缺省值:默认值,取不到的情况,参数名称赋的值
举例
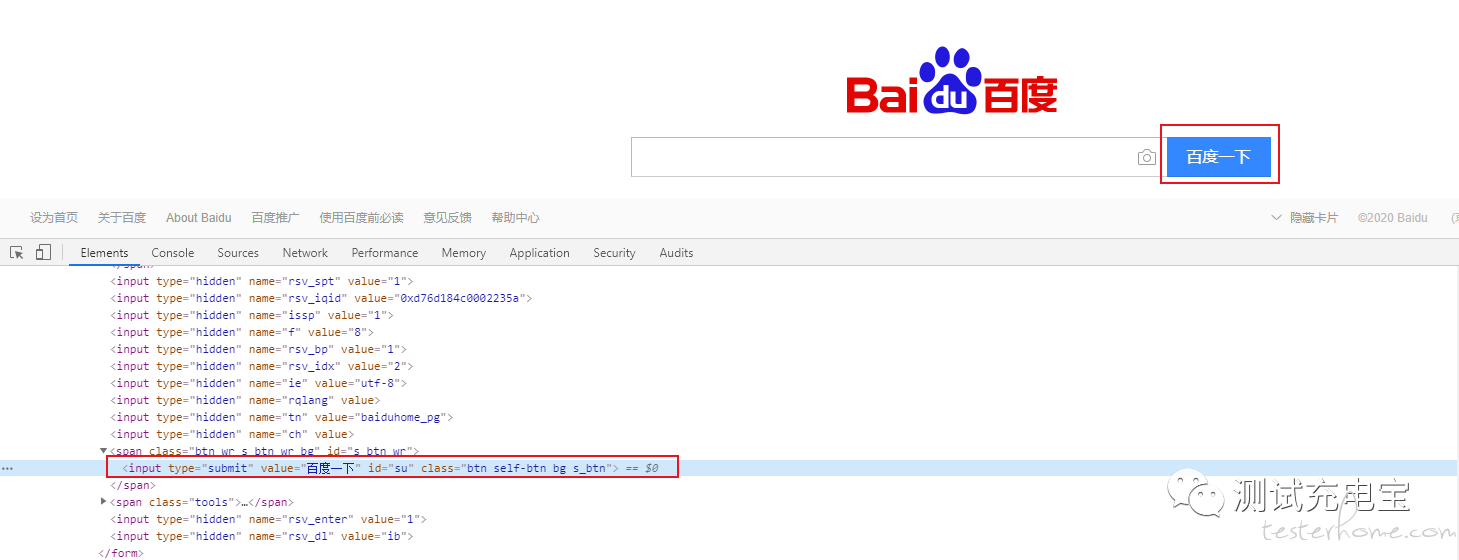
要获取【百度一下】按钮上的文字
XPath Query://input[@id="su"]/@value
BeanShell 后置处理程序
介于本阶段是基础篇,Beanshell相关的放在进阶篇介绍,这里不做过多讲解
总结
本章节讲述前置和后置处理器,前置处理器的元器件和Beanshell后置处理器会在进阶篇介绍,后置处理器介绍了最常用的正则表达式提取器,JSON提取器,边界提取器,XPath提取器。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号