一键更换转载博客的所有图床
一键更换转载博客的所有图床
一、引言
有时看到一些博客写的不错,贴个链接固然愉快,但过段时间总会发现要么博客中的图片挂了,要么直接是博客挂了。所以出于保护原博主的宝贵心血不至于白流(手动狗头),进行了一番折腾(当然,请注明转载并标注出处)。
本次折腾的思路是:利用正则表达式批量导出原博的所有图床链接,批量下载后通过调用Tencent cos的API进行批量上传,最后批量获取腾讯云中的图片链接并以此替换掉原博客中的图床链接。
二、基础内容
1. 正则部分
作为正则的入门,刘江的博客介绍的非常系统,之后再结合文档等的函数说明基本就够用了。
需要注意的是,re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search/re.findall匹配整个字符串,直到找到一个匹配。re.sub并不会直接替换目标字符串,一般需要借助赋值语句。
1-1. 关于字符串str、bytes编码
本次匹配虽然无涉编码
- str
在python3中,str字符串是以Unicode进行编码的。
具体的说,当我们实例化一个字符串时,如
list ='the winter is coming'。python将默认该字符串为str类型,同时将通过Unicode映射表将该字符串映射为对应的Unicode编码。所有的字符串相关的操作都将通过操作对应的Unicode编码实现。但当我们要储存这个字符串时,由于Unicode并不是具体的实现方式(即存储编码方式),我们需要指定具体的编码方式,如python默认的utf-8。
- bytes
bytes其实应该理解为存储在系统中的具体的字节流对象,而不存在什么单独的bytes类型字符串。如果我们要解读一个bytes对象,我们需要知道对应的编码方式(不是像Unicode这样的编码规范,而是像utf-8这样的具体编码方式)。
使我们迷惑的是这么一种声明方式:
>>> bytes([1,2,3,4,5,6,7,8,9]) >>> bytes("python", 'ascii') # 字符串,编码然而,这两种方式都是以默认或指定的方式将字符串编码为字节流。
参考:
python3字符串编码总结-str(unicode)_bytes
2. Tencent COS API调用
这里使用腾讯云的对象存储,是因为接口调用相对简单,且拥有50G的免费空间,一般个人博客使用是够用了。如果想用其他云盘服务也是可以的。
2-1. 注册cos服务
https://cloud.tencent.com/product/cos
2-2. 创建存储桶:(bucket)
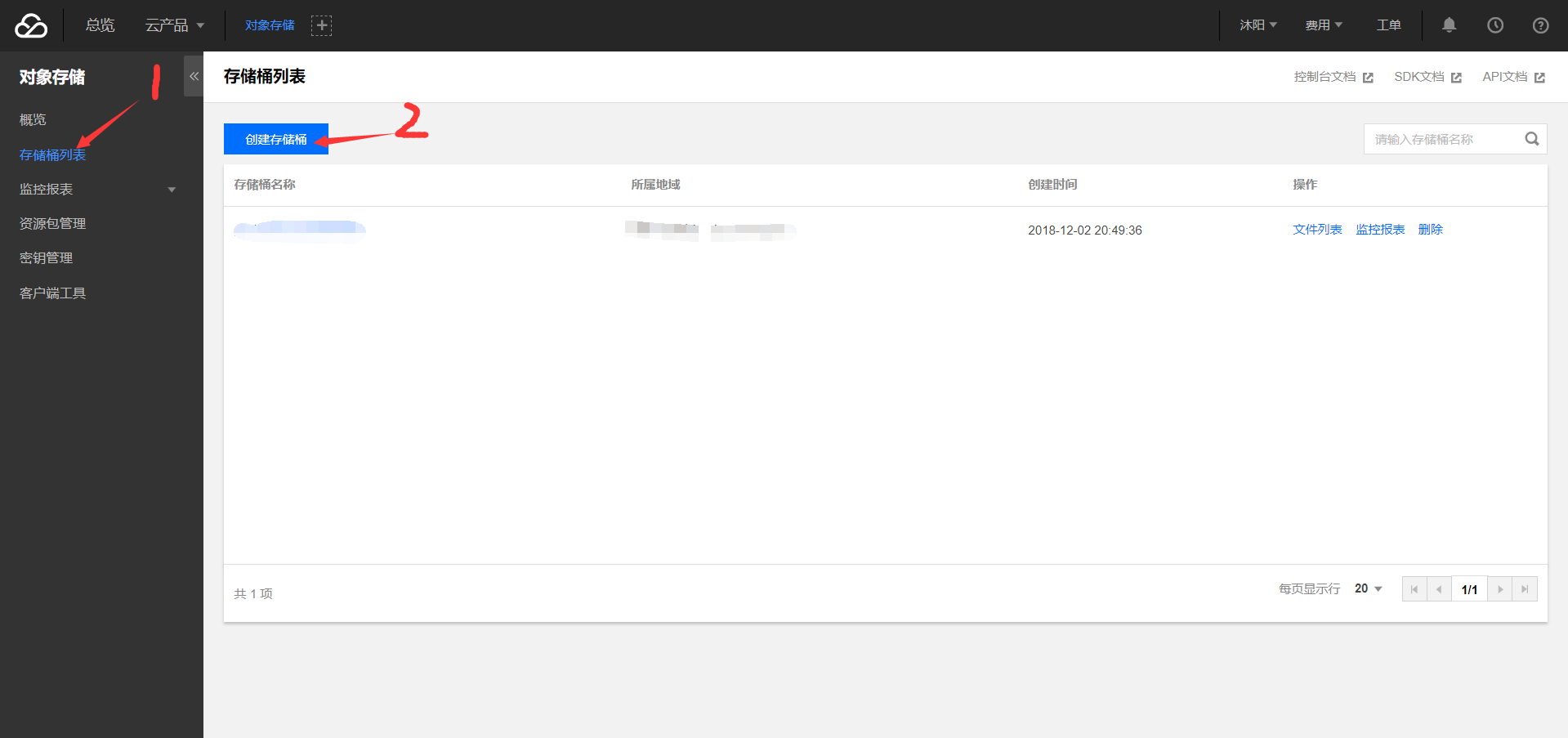
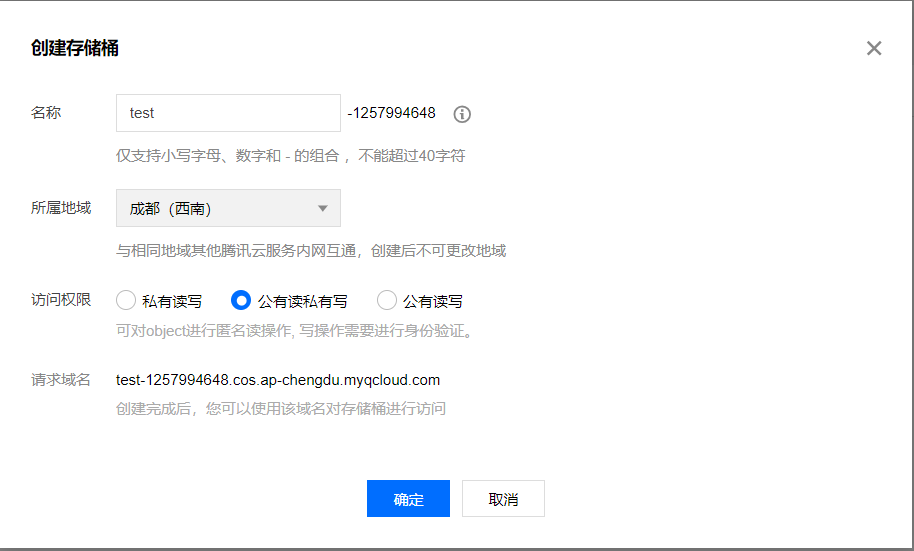
确定后点击基础配置
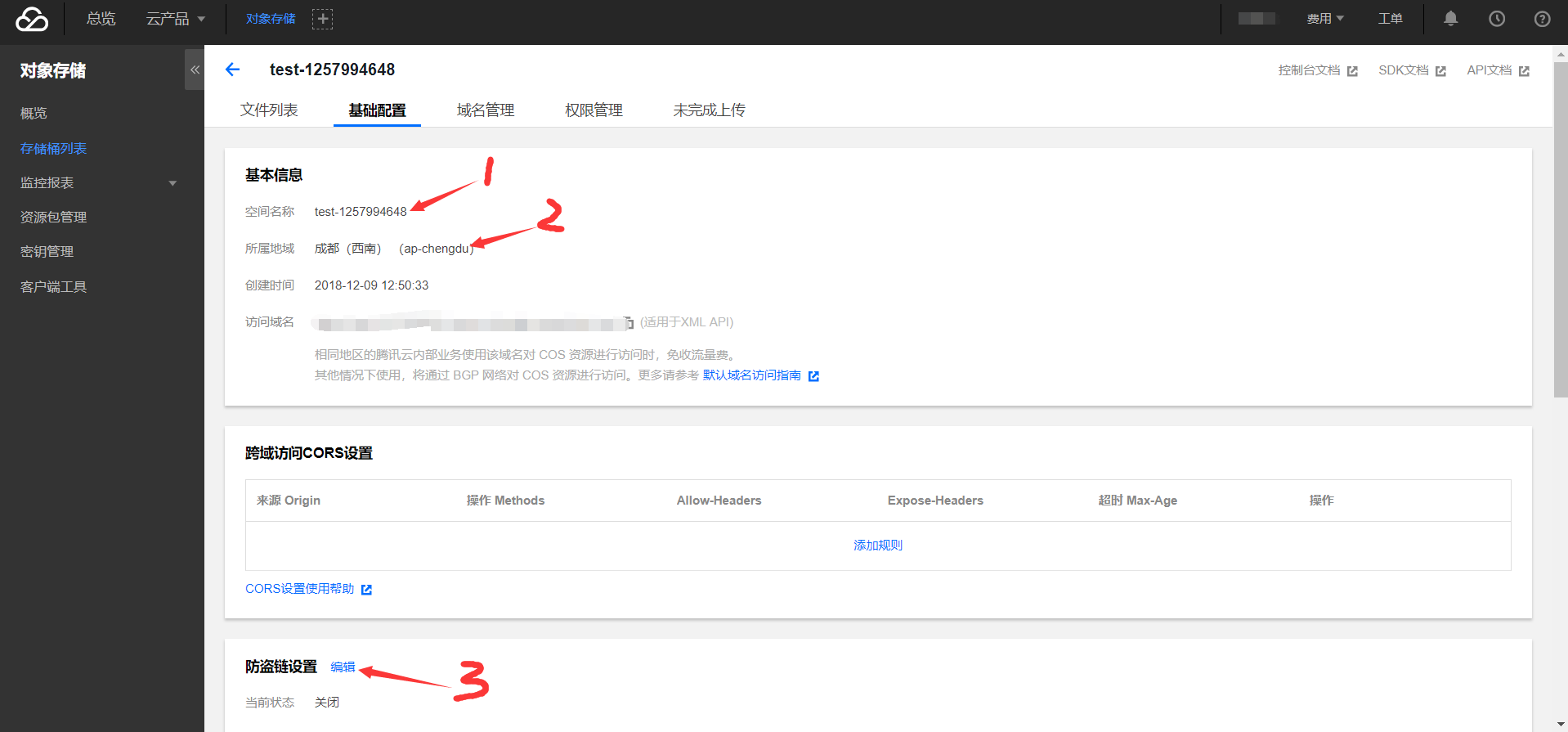
- 将空间名称(bucket)“test-1257994648”粘贴保存。
- 所属区域(region)的“ap-chengdu”粘贴保存,后面调用API时会用到。
- 编辑防盗链设置,在白名单中添加你的域名(博客链接)。
2-3. 新建秘钥
使用调用腾讯云API时需要签名,云API密钥用于生成签名。
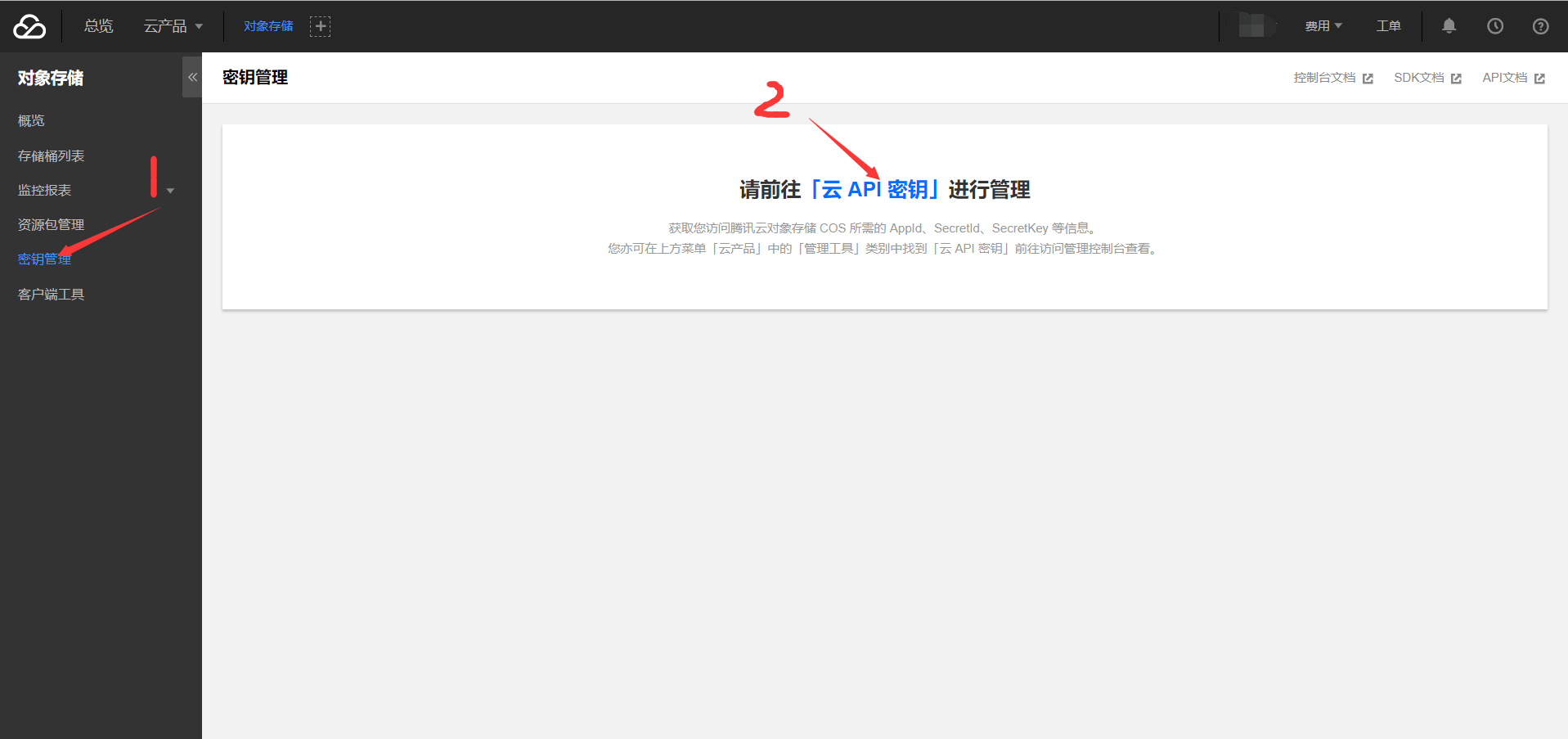
然后在打开的页面中点击“新建秘钥”,将获得的SecretId和SecretKey妥善保存。
2-4. 安装 SDK
安装 SDK 有三种安装方式:pip 安装、手动安装和离线安装。
2-4-1. 使用 pip 安装(推荐)
pip install -U cos-python-sdk-v52-4-2. 手动安装
从 XML Python SDK 下载源码,通过 setup 手动安装,执行以下命令。
python setup.py install2-4-3. 离线安装
# 在有外网的机器下运行如下命令
mkdir cos-python-sdk-packages
pip download cos-python-sdk-v5 -d cos-python-sdk-packages
tar -czvf cos-python-sdk-packages.tar.gz cos-python-sdk-packages
# 将安装包拷贝到没有外网的机器后运行如下命令
# 请确保两台机器的 python 版本保持一致,否则会出现安装失败的情况
tar -xzvf cos-python-sdk-packages.tar.gz
pip install cos-python-sdk-v5 --no-index -f cos-python-sdk-packages2-5. 调用API
完成上面的步骤后,调用API就很简单了。查查文档,修改即可。
不过最新版的SDK中未贴出创建、删除目录等操作(历史版本下的SDK对此却提供了支持)。通过摸索,发现多个函数方法中都包含的一个关键参数的说明是这样的:

解决之道就在此中。
- 创建文件夹:调用client.put_object方法实现。在上传文件时,在文件名(就是后面demo中的file_name/key)中给出想创建的文件夹,将会自动创建。
- 删除文件夹:调用client.delete_object方法实现。需要先删除文件夹下所有文件后才能删除文件夹。要删除文件夹时,只要将文件夹名传给key参数就行。比如要删除“EM算法”,则传入“EM算法/”。
2-5-1. python SDK的参考文档链接如下:
2-5-2. 大概流程:
- 导入SDK的相关包
- 使用上面创建的秘钥和ID来生成包含了签名的client对象
- 调用client的相应方法完成我们需要的功能
2-5-3. demo:
# 下面是调用前的重复性工作
## 1. 设置用户配置, 包括 secretId,secretKey 以及 Region
## -*- coding=utf-8
from qcloud_cos import CosConfig
from qcloud_cos import CosS3Client
import sys
import logging
logging.basicConfig(level=logging.INFO, stream=sys.stdout)
secret_id = 'xxxxxxxx' # 替换为用户的 secretId
secret_key = 'xxxxxxx' # 替换为用户的 secretKey
region = 'ap-beijing-1' # 替换为用户的 Region
token = None # 使用临时密钥需要传入 Token,默认为空,可不填
scheme = 'https' # 指定使用 http/https 协议来访问 COS,默认为 https,可不填
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key, Token=token, Scheme=scheme)
## 2. 获取客户端对象
client = CosS3Client(config)
## 参照下文的描述。或者参照 Demo 程序,详见 https://github.com/tencentyun/cos-python-sdk-v5/blob/master/qcloud_cos/demo.py
# 下面是API调用的实例,你可以根据需求从文档找到需要的方法。
file_name = 'test.txt'
with open('D://test.txt', 'rb') as fp:
response = client.put_object(
Bucket='test04-123456789',
Body=fp,
Key=file_name,
StorageClass='STANDARD',
ContentType='text/html; charset=utf-8'
)
print(response['ETag'])三、实践
1. 匹配原博图片链接
第一步是匹配出原博中所有的图片链接(当然,其他链接也可以)。
这次我转载的是CSDN上的一篇博客,CSDN的图片链接是这样的:[](图片地址2)
对应的正则表达式为:\\[!\\[.*?\\]\\(.*?\\)\\]\\((.*?)\\)
注意:
- 由于‘[ ] ( )’等在正则表达式中都有别义,所以需要单独加上转义符‘\’。需要指出的是,此处使用python的原生字符串(即在字符串前加上一个“r”)实际效果区别不大。具体区别可参考:python正则表达式转义注意事项
- 这里需要加上?来进行非贪婪匹配,以防会漏掉链接。
- 后面的一对未转义的圆括号是为了仅仅将括号里的链接输出出来。
2. 下载图片到本地
将所得的图片链接下载到本地,为下一步上传做准备。
3. 上传图片到云端
调用API实现。
4. 获得图床链接
本应该通过API批量生成分享链接,但实践发现,腾讯的分享链接接口有个expire参数,用于控制链接有效时间,默认300秒,非常不便。后来通过观察发现,存储桶中的文件直链结构非常简单,直接由桶的域名加上文件名就构成了。如果你的链接访问不了,请检查桶的读权限是否为公有。
5. 将原博中的图片链接更换为自己的图床链接
这个简单,通过正则匹配就可以了。
四、完整代码
最后贴上代码,有需要的可以自己修改使用。
# -*- coding=utf-8
import re
import os
import urllib
from qcloud_cos import CosConfig
from qcloud_cos import CosS3Client
import sys
import logging
# 将本地md中的图片链接提取出并储存于urllist中,
blog_url = 'C:\\Users\\zzp\OneDrive - stu.xjtu.edu.cn\\文档\\typora\\草稿.md'
blog_name = re.match(u'(.*)\.md$',os.path.basename(blog_url)).group(1)
pic_type = []
try:
f = open(blog_url, encoding='utf-8')
lines = f.readlines()
except FileNotFoundError as e:
print("夭寿啦,文件没找到!")
f.close()
urllist =[]
compile_eurl = re.compile('\[!\[.*?\]\(.*?\)\]\((.*?)\)')
for line in lines:
try:
urllist.extend(compile_eurl.findall(line))
except AttributeError as e:
print("error")
# 获取图片后缀,以备后面命名使用
pic_type = re.match('.*?\.([a-zA-Z]{3}$)', urllist[0]).group(1)
# 批量下载链接对应图片到本地
for i in range(len(urllist)):
try:
urllib.request.urlretrieve(urllist[i], "D:/临时/"+blog_name+'_'+str(i) + '.'+pic_type)
except:
print('夭寿啦,下载失败啦!')
print('完成图片下载')
## 利用腾讯提供的cos存储官网sdk进行批量上传
logging.basicConfig(level=logging.INFO, stream=sys.stdout)
## 设置用户属性, 包括secret_id, secret_key, region
secret_id = 'AKERXXXXXXXXXXXXXXXXXXXXXXXX' # 替换为你的secret_id
secret_key = 'TmxxXXXXXXXXXXXXXXXXXXXXXXXXXXXX' # 替换为你的的secret_key
region = 'ap-chengdu' # 替换为你的region/服务器地域编号
token = None # 使用临时秘钥需要传入Token,默认为空,可不填
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key, Token=token) # 获取配置对象
client = CosS3Client(config)
# 文件流 简单上传
for i in range(len(urllist)):
with open("D:/临时/"+blog_name+'_'+str(i) + '.'+pic_type, 'rb') as fp:
response = client.put_object(
Bucket='test-1257994648', # 我们上面保存的空间名
Body=fp,
Key=blog_name + '_' + str(i) + '.' + pic_type,
StorageClass='STANDARD',
ContentType='text/html; charset=utf-8'
)
print('完成图片上传')
# 更换博客图片链接
i = len(urllist)
compile_url = re.compile(u'\[!\[.*?\]\(.*?\)\]\(.*?\)')
for x in range(len(lines)):
while compile_url.findall(lines[x]):
lines[x] = re.sub(compile_url, ') + '.' + pic_type+')', lines[x], count=1)
i = i+1
print(lines)
# 写入博客
with open(blog_url, encoding='utf-8', mode='w') as f:
f.writelines(lines)