
python爬取智联招聘职位信息(单进程)
我们先通过百度搜索智联招聘,进入智联招聘官网,一看,傻眼了,需要登录才能查看招聘信息
没办法,用账号登录进去,登录后的网页如下:
输入职位名称点击搜索,显示如下网页:

把这个URL:https://sou.zhaopin.com/?jl=765&kw=软件测试&kt=3 拷贝下来,退出登录,再在浏览器地址栏输入复制下来的URL
哈哈,居然不用登录,也可以显示搜索的职位信息。好了,到这一步,目的达成。
接下来,我们来分析下页面,打开浏览器的开发者工具,选择Network,查看XHR,重新刷新一次页面,可以看到有多个异步加载信息

查看每个请求的返回消息,我们可以找到其中有个请求已JSON方式返回了符合要求的总职位数以及职位链接等信息
点击Headers,查看这个请求的URL:
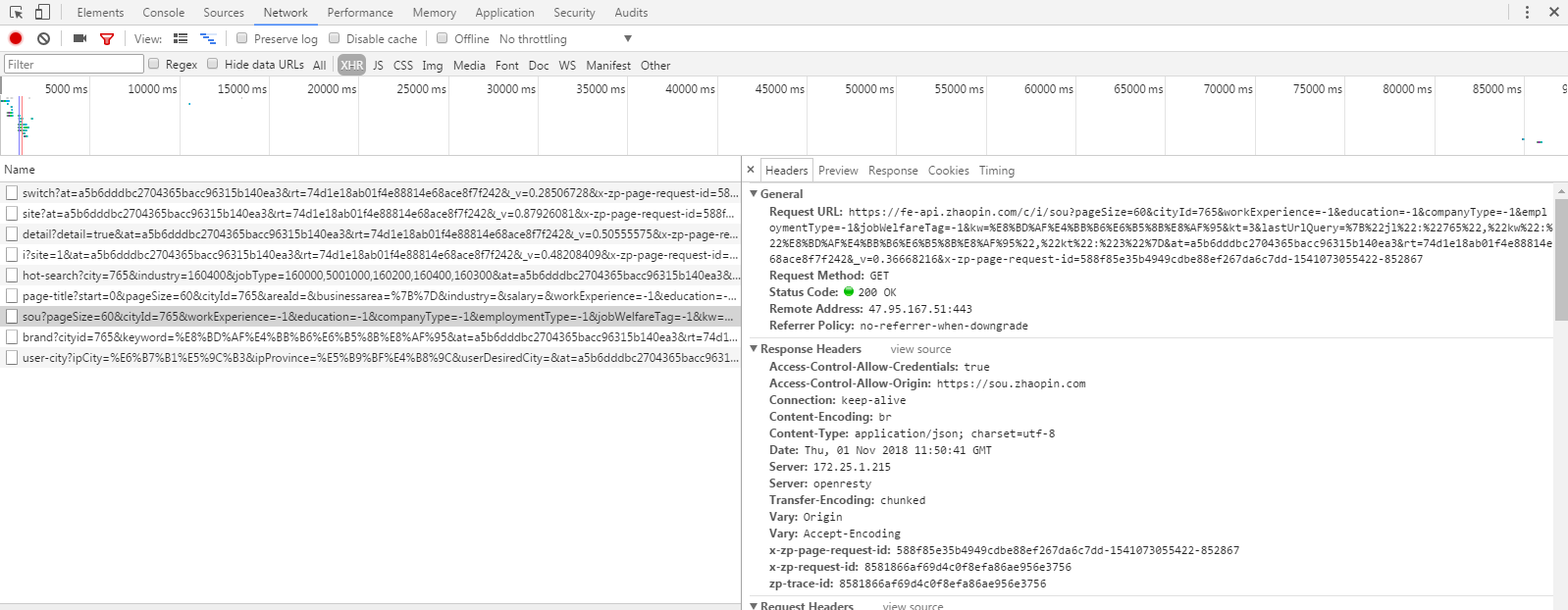
我们把Request URL复制到浏览器中打开,没错就是我们需要的信息:
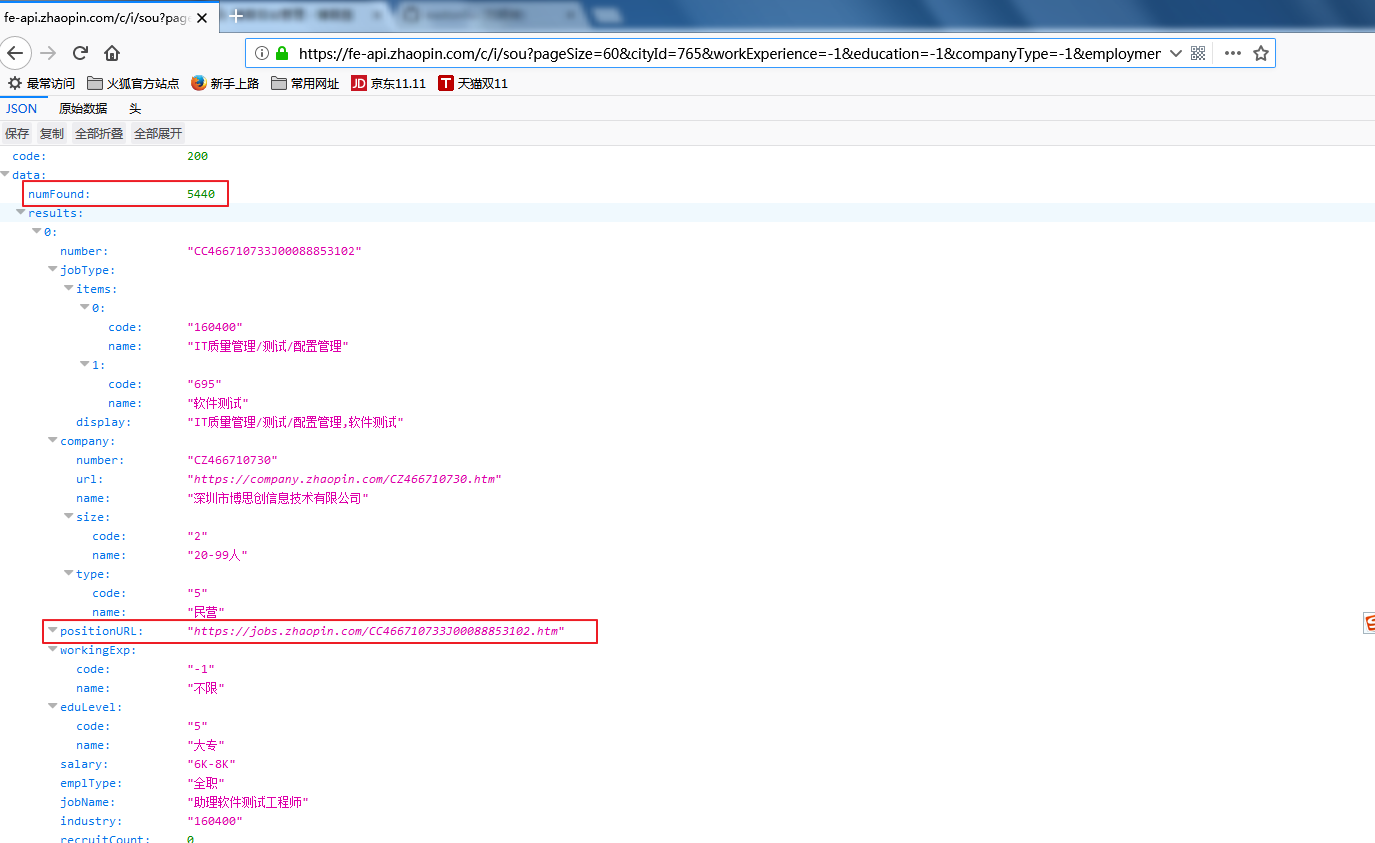
分析这个URL:https://fe-api.zhaopin.com/c/i/sou?pageSize=60&cityId=765&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=软件测试&kt=3
我们可以知道:
1、pageSize:每页开始的值,第一页是0,第二是60,第三页是120,以此类推
2、cityId:是城市编码,直接输入城市名,也是可以的,比如:深圳
3、kw:搜索时输入的关键词,也就是职位名称
其他的字段都可以不变。
分析完了之后,我们可以开始写代码了:
我们先定义一个日志模块,保存爬虫过程中的日志:


# !usr/bin/env python3 # -*- coding:utf-8 -*- """ @project = Spider_zhilian @file = log @author = Easton Liu @time = 2018/10/20 21:42 @Description: 定义日志输出,同时输出到文件和控制台 """ import logging import os from logging.handlers import TimedRotatingFileHandler class Logger: def __init__(self, logger_name='easton'): self.logger = logging.getLogger(logger_name) logging.root.setLevel(logging.NOTSET) self.log_file_name = 'spider_zhilian.log' self.backup_count = 5 # 日志输出级别 self.console_output_level = 'WARNING' self.file_output_level = 'DEBUG' # 日志输出格式 pattern='%(asctime)s - %(levelname)s - %(message)s' self.formatter = logging.Formatter(pattern) # 日志路径 if not os.path.exists('log'): os.mkdir('log') self.log_path = os.path.join(os.getcwd(),'log') def get_logger(self): """在logger中添加日志句柄并返回,如果logger已有句柄,则直接返回""" if not self.logger.handlers: console_handler=logging.StreamHandler() console_handler.setFormatter(self.formatter) console_handler.setLevel(self.console_output_level) self.logger.addHandler(console_handler) # 每天重新创建一个日志文件,最多保留backup_count份 file_handler = TimedRotatingFileHandler(filename=os.path.join(self.log_path, self.log_file_name), when='D', interval=1, backupCount=self.backup_count, delay=True, encoding='utf-8' ) file_handler.setFormatter(self.formatter) file_handler.setLevel(self.file_output_level) self.logger.addHandler(file_handler) return self.logger logger = Logger().get_logger()
用一个简单的方法来实现增量爬取,把爬取的URL以hashlib加密,加密后返回32个字符,为了节省内存,只取中间的16个字符,这样也可以保证每个不同的URL有不同的加密字符,把爬取的URL加密字符保存到集合中,在爬取完成后,序列化保存到本地磁盘,下次再次爬取时,反序列化保存的URL到内存,对于已经爬取的URL不再爬取,这样就实现了增量爬取。
URL加密:
def hash_url(url): ''' 对URL进行加密,取加密后中间16位 :param url:已爬取的URLL :return:加密的URL ''' m = hashlib.md5() m.update(url.encode('utf-8')) return m.hexdigest()[8:-8]
序列化:
def save_progress(data, path): ''' 序列化保存已爬取的URL文件 :param data:要保存的数据 :param path:文件路径 :return: ''' try: with open(path, 'wb+') as f: pickle.dump(data, f) logger.info('save url file success!') except Exception as e: logger.error('save url file failed:',e)
反序列化:
def load_progress( path): ''' 反序列化加载已爬取的URL文件 :param path: :return: ''' logger.info("load url file of already spider:%s" % path) try: with open(path, 'rb') as f: tmp = pickle.load(f) return tmp except: logger.info("not found url file of already spider!") return set()
获取符合要求的职位总页数:从JSON消息中获取numFound字段,这个是总条数,再除以60,向上取整,返回的就是总页数
def get_page_nums(cityname,jobname): ''' 获取符合要求的工作页数 :param cityname: 城市名 :param jobname: 工作名 :return: 总数 ''' url = r'https://fe-api.zhaopin.com/c/i/sou?pageSize=60&cityId={}&workExperience=-1&education=-1' \ r'&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw={}&kt=3'.format(cityname,jobname) logger.info('start get job count...') try: rec = requests.get(url) if rec.status_code==200: j = json.loads(rec.text) count_nums = j.get('data')['numFound'] logger.info('get job count nums sucess:%s'%count_nums) page_nums = math.ceil(count_nums/60) logger.info('page nums:%s' % page_nums) return page_nums except Exception as e: logger.error('get job count nums faild:%s',e)
获取每页的职位连接:JSON消息中的positionURL就是职位链接,在这里我们顺便获取职位的创建时间,更新时间,截止时间以及职位福利,以字典返回
1 def get_urls(start,cityname,jobname): 2 ''' 3 获取每页工作详情URL以及部分职位信息 4 :param start: 开始的工作条数 5 :param cityname: 城市名 6 :param jobname: 工作名 7 :return: 字典 8 ''' 9 url = r'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=60&cityId={}&workExperience=-1&education=-1' \ 10 r'&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw={}&kt=3'.format(start,cityname,jobname) 11 logger.info('spider start:%s',start) 12 logger.info('get current page all job urls...') 13 url_list=[] 14 try: 15 rec = requests.get(url) 16 if rec.status_code == 200: 17 j = json.loads(rec.text) 18 results = j.get('data').get('results') 19 for job in results: 20 empltype = job.get('emplType') # 职位类型,全职or校园 21 if empltype=='全职': 22 url_dict = {} 23 url_dict['positionURL'] = job.get('positionURL') # 职位链接 24 url_dict['createDate'] = job.get('createDate') # 招聘信息创建时间 25 url_dict['updateDate'] = job.get('updateDate') # 招聘信息更新时间 26 url_dict['endDate'] = job.get('endDate') # 招聘信息截止时间 27 positionLabel = job.get('positionLabel') 28 if positionLabel: 29 jobLight = (re.search('"jobLight":\[(.*?|[\u4E00-\u9FA5]+)\]',job.get('positionLabel'))) # 职位亮点 30 url_dict['jobLight'] = jobLight.group(1) if jobLight else None 31 else: 32 url_dict['jobLight'] = None 33 url_list.append(url_dict) 34 logger.info('get current page all job urls success:%s' % len(url_list)) 35 return url_list 36 except Exception as e: 37 logger.error('get current page all job urls faild:%s', e) 38 return None
在浏览器中输入一个职位链接,查看页面信息
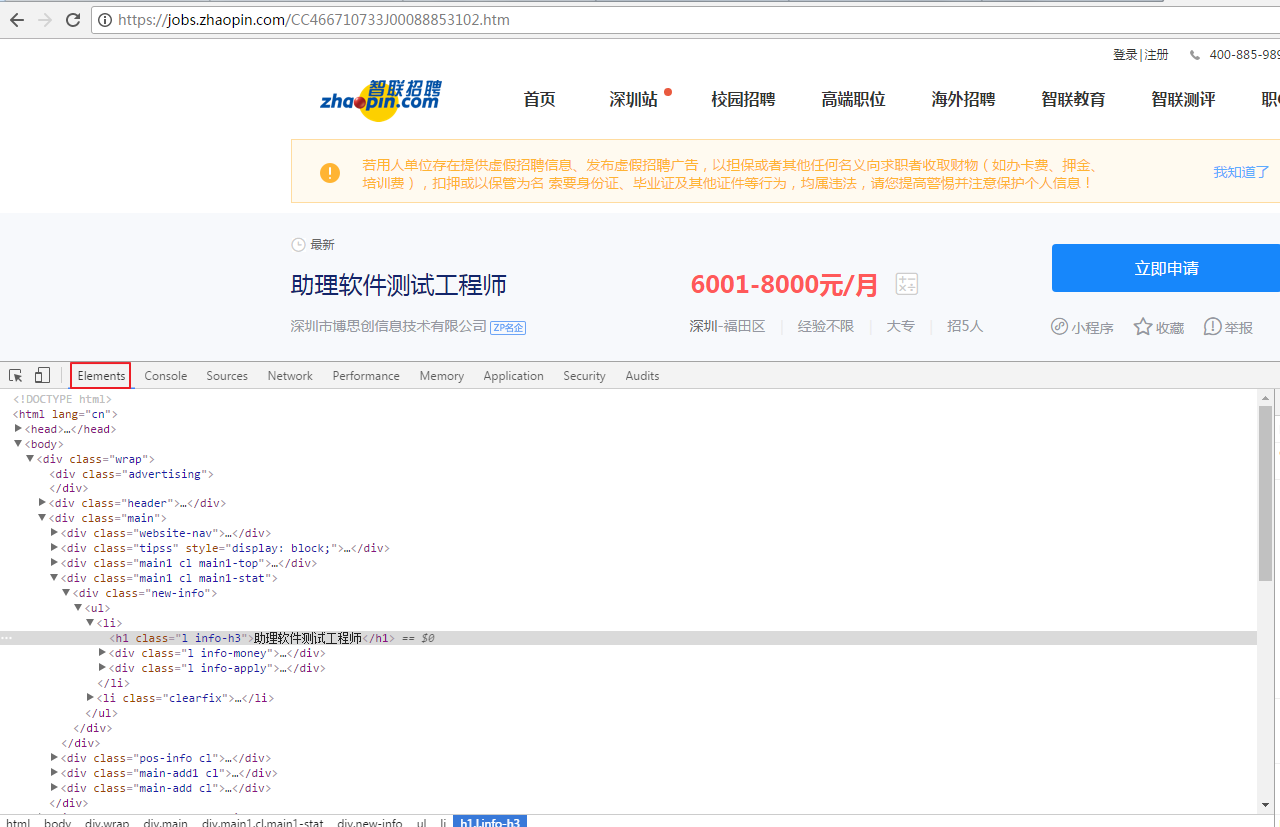
在这里我们以lxml来解析页面,解析结果以字典保存到生成器中
def get_job_info(url_list,old_url): ''' 获取工作详情 :param url_list: 列表 :return: 字典 ''' if url_list: for job in url_list: url = job.get('positionURL') h_url = hash_url(url) if not h_url in old_url: logger.info('spider url:%s'%url) try: response = requests.get(url) if response.status_code == 200: s = etree.HTML(response.text) job_stat = s.xpath('//div[@class="main1 cl main1-stat"]')[0] stat_li_first = job_stat.xpath('./div[@class="new-info"]/ul/li[1]')[0] job_name = stat_li_first.xpath('./h1/text()')[0] # 工作名 salary = stat_li_first.xpath('./div/strong/text()')[0] # 月薪 stat_li_second = job_stat.xpath('./div[@class="new-info"]/ul/li[2]')[0] company_url = stat_li_second.xpath('./div[1]/a/@href')[0] # 公司URL company_name = stat_li_second.xpath('./div[1]/a/text()')[0] # 公司名称 city_name = stat_li_second.xpath('./div[2]/span[1]/a/text()')[0] # 城市名 workingExp = stat_li_second.xpath('./div[2]/span[2]/text()')[0] # 工作经验 eduLevel = stat_li_second.xpath('./div[2]/span[3]/text()')[0] # 学历 amount = stat_li_second.xpath('./div[2]/span[4]/text()')[0] # 招聘人数 job_text = s.xpath('//div[@class="pos-ul"]//text()') # 工作要求 job_desc = '' for job_item in job_text: job_desc = job_desc+job_item.replace('\xa0','').strip('\n') job_address_path = s.xpath('//p[@class="add-txt"]/text()') # 上班地址 job_address = job_address_path[0] if job_address_path else None company_text = s.xpath('//div[@class="intro-content"]//text()') # 公司信息 company_info='' for item in company_text: company_info = company_info+item.replace('\xa0','').strip('\n') promulgator = s.xpath('//ul[@class="promulgator-ul cl"]/li') compant_industry = promulgator[0].xpath('./strong//text()')[0] #公司所属行业 company_type = promulgator[1].xpath('./strong/text()')[0] #公司类型:民营,国企,上市 totall_num = promulgator[2].xpath('./strong/text()')[0] #公司总人数 company_addr = promulgator[4].xpath('./strong/text()')[0].strip() #公司地址 logger.info('get job info success!') old_url.add(h_url) yield { 'job_name':job_name, # 工作名称 'salary':salary, # 月薪 'company_name':company_name, # 公司名称 'eduLevel':eduLevel, # 学历 'workingExp':workingExp, # 工作经验 'amount':amount, # 招聘总人数 'jobLight':job.get('jobLight'), # 职位亮点 'city_name':city_name, # 城市 'job_address':job_address, # 上班地址 'createDate':job.get('createDate'), # 创建时间 'updateDate':job.get('updateDate'), # 更新时间 'endDate':job.get('endDate'), # 截止日期 'compant_industry':compant_industry, # 公司所属行业 'company_type':company_type, # 公司类型 'totall_num':totall_num, # 公司总人数 'company_addr':company_addr, # 公司地址 'job_desc':job_desc, # 岗位职责 'job_url':'url', # 职位链接 'company_info':company_info, # 公司信息 'company_url':company_url # 公司链接 } except Exception as e: logger.error('get job info failed:',url,e)
输出到CSV
headers = ['职业名', '月薪', '公司名', '学历', '经验', '招聘人数', '公司亮点','城市', '上班地址', '创建时间', '更新时间', '截止时间', '行业', '公司类型', '公司总人数', '公司地址', '岗位描述', '职位链接', '信息', '公司网址'] def write_csv_headers(csv_filename): with open(csv_filename,'a',newline='',encoding='utf-8-sig') as f: f_csv = csv.DictWriter(f,headers) f_csv.writeheader() def save_csv(csv_filename,data): with open(csv_filename,'a+',newline='',encoding='utf-8-sig') as f: f_csv = csv.DictWriter(f,data.keys()) f_csv.writerow(data)
最后就是主函数了:
def main(): if not os.path.exists(output_path): os.mkdir(output_path) for jobname in job_names: for cityname in city_names: logger.info('*'*10+'start spider '+'jobname:'+jobname+'city:'+cityname+'*'*10) total_page = get_page_nums(cityname,jobname) old_url = load_progress('old_url.txt') csv_filename=output_path+'/{0}_{1}.csv'.format(jobname,cityname) if not os.path.exists(csv_filename): write_csv_headers(csv_filename) for i in range(int(total_page)): urls = get_urls(i*60, cityname, jobname) data = get_job_info(urls, old_url) for d in data: save_csv(csv_filename,d) save_progress(old_url,'old_url.txt') logger.info('*'*10+'jobname:'+jobname+'city:'+cityname+' spider finished!'+'*'*10)
打印爬虫耗时总时间:
city_names = ['深圳','广州']
job_names = ['软件测试','数据分析']
output_path = 'output'
if __name__=='__main__': start_time = datetime.datetime.now() logger.info('*'*20+"start running spider!"+'*'*20) main() end_time = datetime.datetime.now() logger.info('*'*20+"spider finished!Running time:%s"%(start_time-end_time) + '*'*20) print("Running time:%s"%(start_time-end_time))
以上代码已全部上传到github中,地址:https://github.com/Python3SpiderOrg/zhilianzhaopin

