QA问答系统,QA匹配论文学习笔记
论文题目:
WIKIQA: A Challenge Dataset for Open-Domain Question Answering
论文代码运行:
首先按照readme中的提示安装需要的部分
遇到的问题:
theano的一些问题,主要是API改动
下面是解决方法
首先安装
https://stackoverflow.com/questions/39501152/importerror-no-module-named-downsample
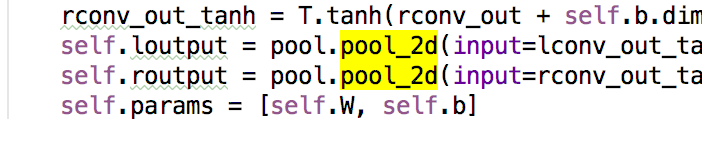
代码改动如下所示:

论文内容:
摘要:
介绍本文主要是提供了一种开放领域的QA匹配的问答系统,并且描述了创建的WIKI数据集的方式。
这种QA匹配的算法与之前的算法的不同之处在于,以往重点在于Q和A中相同词的个数,主要重点在于文本结构的相似,
本文的算法偏向于语义的相似。本文对比了几种算法在相同数据集上的表现。
引言:
Answer sentence selection (答案选择??)是开放领域QA的一个自问题。介绍了
TREC-QA data 的来历。说这个数据集虽然已经是该类问题的基准测试机,但是并不好,有巴拉巴拉一些缺点,
主要就是question和answer之间的文本相似度比较大,偏爱文本相似的答案,比实际情况效果有些膨胀了。
另一方面就是实际情况question不一定有对应的答案。
所以创建了wikiQA数据集。
本文的作者实现了几种模型来
wikiQA数据集的介绍:
这个数据集是从Bing的搜索日志中选出来的。这个数据集有3047条数据。
这是基于用户点击WIKI页面得到的。就是用户有个搜索的问题,返回结果有wiki,用户点开看了。
那答案怎么来呢?答案是wiki页面的摘要。
作者认为wiki的摘要质量很高,可以很好的概括页面的内容。
为了排除对于keyword(关键字)的偏好,数据集将摘要中的每一句话都作为问题的一个候选答案。
然后再由人工标注哪些句子是正确答案。
实验:
对比了使用TF-IDF和不使用TF-IDF的区别,实现了
LCLR 和CNN两种QA比较的算法
CNN-Cnt是最好的了,CNN加词的权重
在WIKI QA数据集上 CNN表现好与单纯的词匹配,好于LCLR
总结:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号