
小数据池、代码块以及编码转换
一、代码块
Python程序是由代码块构造的。块是一个python程序的文本,他是作为一个单元执行的。
代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块。
而作为交互方式输入的每个命令都是一个代码块。
什么叫交互方式?就是咱们在cmd中进入Python解释器里面,每一行代码都是一个代码块。
不同的代码块:
def func():
print(333)
class A:
name = 'alex'
虽然上面的缩进的内容都叫代码块,但是他不是python中严格定义的代码块。
for i in '12324545':
print(i)
交互模式下,每一行都是一个代码块
>>>i1 = 100 可以理解这一行在一个文件中
>>>i2 = 100 可以理解这一行在另一个文件中
# 二、 id, is ==
name = 'alex' #赋值
print('alex' == 'alex') #数值相同
name = 'alex123'
print(id(name)) #2112772900544
# 在内存中id都是唯一的,如果两个变量指向的值的id相同,就证明他们在内存中是同一个。
# is判断的是两个变量的id值是否相同。
# 如果is是True, == 一定是True。反过来不一定成立
# 如果is是True, == 一定是True。 反过来不一定成立 >>> i1 = 1000 >>> i2 = 1000 >>> print(i1 is i2) False >>> print(i1 == i2) True >>>
# 三、小数据池(缓存机制,驻留机制)
小数据池的应用数据类型:整数,字符串,bool值
# 小数据池,python对内存做的一个优化:
# 他将 -5~256 之间的整数,以及一定规则的字符串,提前在内存中创建了池,容器。容器里固定的放了这些数。
指向的都是同一个内存地址
在交互器中
s1 = 100
s2 = 100
指向地址一致
与
s1 = 1000
s2 = 1000
指向地址不一致
为什么这么做:
1. 节省内存。
2. 提高性能与效率
代码块:
python在对于同一个代码块中的变量,初始化对象的命令中时,它会将变量与值的对应关系放到一个字典中
如果下面的代码在遇到初始化对象的命令时,它会先从字典中寻找,如果存在相同的值,他会复用,所以指向的都是同一个内存地址。
dic = {'name':alex@的内存地址}
python交互方式对于不同的代码块:初始化命令时,他会从小数据池中寻找。
name = 'alex@'
name1 = 'alex@'
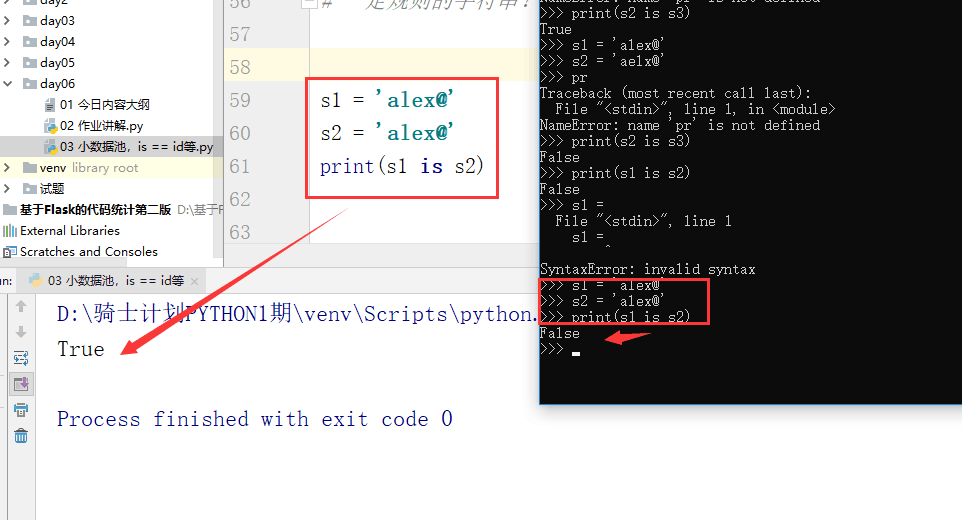


1 #内存地址会变 2 3 # 小数据池 指向同一地址 4 i1 = 100 5 i2 = 100 6 print(id(i1),id(i2)) 7 # pycharm 140708817920128 140708817920128 8 # 交互方式 140708990083200 140708990083200 9 10 11 # 同一代码块。pycharm指向的是同一地址,交互方式指向的不同地址。 12 i1 = 1000 13 i2 = 1000 14 print(id(i1),id(i2)) 15 #pycharm 2093897078224 2093897078224 16 #交互方式 1830950750224 1830950750096 17 18 19 # 不同代码块,地址不同 20 def func1(): 21 i = 1000 22 print(id(i)) # 2093927219472 23 24 def func2(): 25 i = 1000 26 print(id(i)) # 2093927219440 27 28 func1() 29 func2() 30 31 32 # 从小数据取得 地址相同 33 def func1(): 34 i = 100 35 print(id(i)) # 140708817920128 36 37 def func2(): 38 i = 100 39 print(id(i)) # 140708817920128 40 41 func1() 42 func2()
编码以及转换关系
ASCII码:
A : 0100 0001 8位
中:0100 0001 0100 0001 16位
Unicode编码:
A:0100 0001 0100 0001 16位
中:0100 0001 0100 0001
升级
A:0100 0001 0100 0001 0100 0001 0100 0001 32位
中:0100 0001 0100 0001 0100 0001 0100 0001
浪费资源
UTF-8编码:
一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。
A :01000001 8位
欧:01000001 01000001 16位
中 :01000001 01000001 01000001 24位
gbk:国标,只包含中文,英文(英文字母,数字,特殊字符)
A : 01000001 8位
中文 : 01000001 01000001 16位
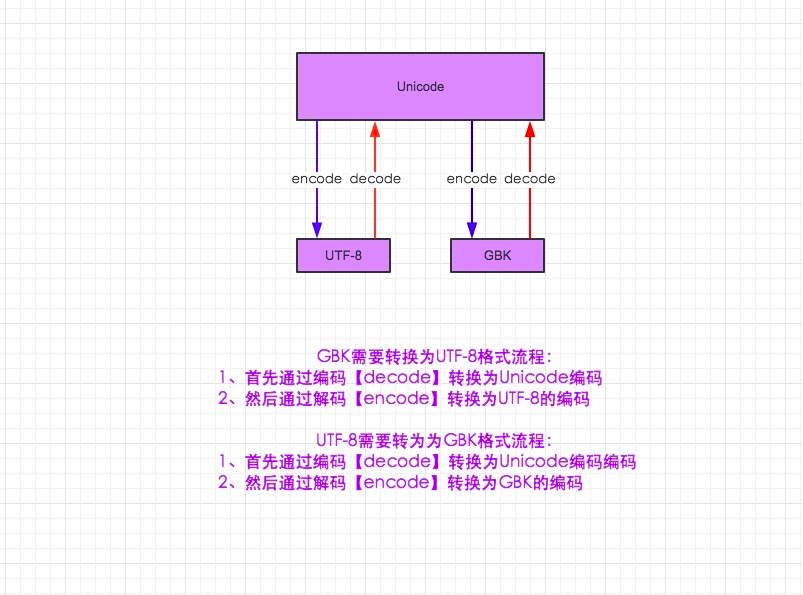
1.编码之间不能互相识别。
2.网络传输,或着硬盘存储的010101,必须是以非Unicode编码方式得01010101
大环境python3.x:
str:内存(内部)编码方式位Unicode。
其他都是utf-8
bytes:python的基础数据类型之一,他和str相当于双胞胎,str拥有的所有方法,bytes类型都适用。
str与bytes区别:
英文字母:
str:
表现形式:s1 = 'alex'
内部编码方式:Unicode
bytes:
表现形式:b1 = b'alex'
内部编码方式:非Unicode
中文字母:
str:
表现形式:s1 = '太白'
内部编码方式:Unicode
bytes:
表现形式:b1 = b'\xe5\xa4\xaa\xe7\x99\xbd'
内部编码方式:非Unicode
如何使用:
如果你想将一部分内容(字符串)写入文件,或者通过网络socket传输传输,这样这部分内容(字符串)必须转化成bytes才可以进行。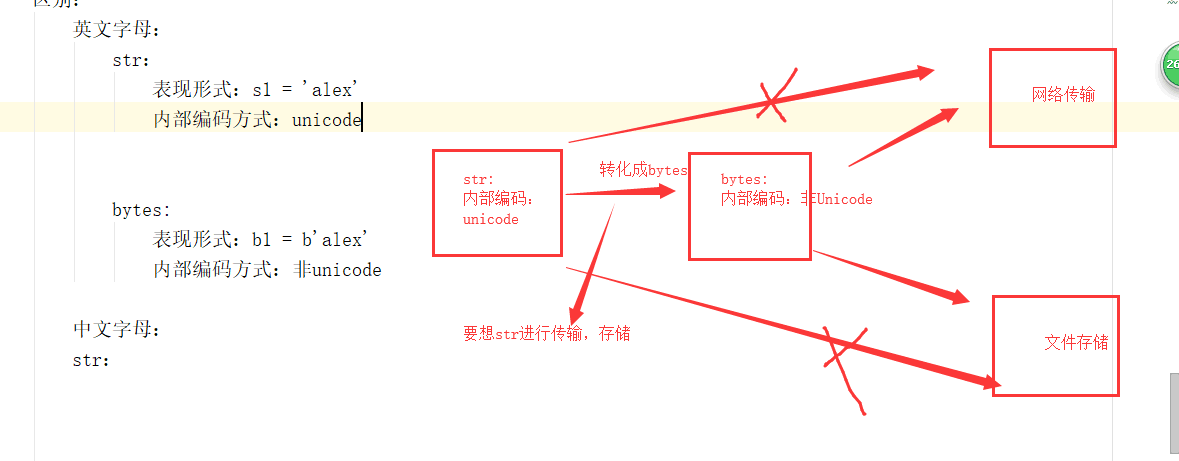
bytes类型gbk能与utf-8相互转换,前提是英文字母,数字,特殊字符。因为他们引用的都是ASCII
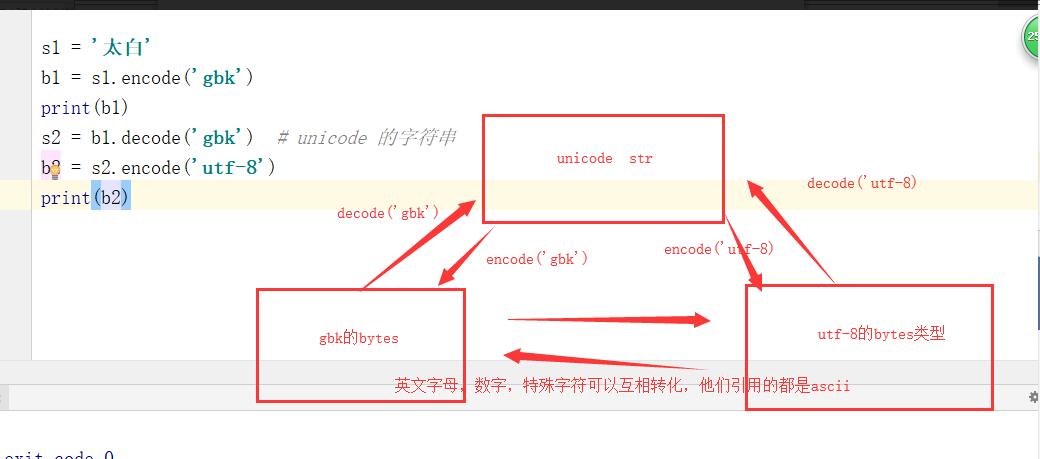
str --> bytes encode编码
s1 = 'alex'
b1 = s1.encode('utf-8')
s2 = '太白'
b2 = s2.encode('gbk')
bytes --> str decode 解码
b1 = b'\xcc\xab\xb0\xd7' #gbk的形式
s1 = b1.decode('gbk')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号